Deep Reinforcement Learning
|
|
|
- Alban Cobb
- 6 years ago
- Views:
Transcription

1 Deep Reinforcement Learning Lex Fridman
2 Environment Sensors Sensor Data Open Question: What can be learned from data? Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Action Effector








3 Environment Sensors Sensor Data Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Lidar Camera (Visible, Infrared) Radar GPS Action Effector Stereo Camera Microphone Networking (Wired, Wireless) IMU References: [132]

4 Environment Sensors Sensor Data Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Action Effector

5 Environment Sensors Sensor Data Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Action Effector



6 Environment Sensors Image Recognition: If it looks like a duck Audio Recognition: Quacks like a duck Sensor Data Feature Extraction Representation Machine Learning Activity Recognition: Swims like a duck Knowledge Reasoning Planning Action Effector
7 Environment Sensors Sensor Data Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Action Effector Final breakthrough, 358 years after its conjecture: It was so indescribably beautiful; it was so simple and so elegant. I couldn t understand how I d missed it and I just stared at it in disbelief for twenty minutes. Then during the day I walked around the department, and I d keep coming back to my desk looking to see if it was still there. It was still there. I couldn t contain myself, I was so excited. It was the most important moment of my working life. Nothing I ever do again will mean as much."


8 Environment Sensors Sensor Data Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Action Effector

9 Environment Sensors Sensor Data Feature Extraction Representation Machine Learning Knowledge Reasoning Planning Action Effector References: [133]
10 Environment Sensors Sensor Data Feature Extraction Representation The promise of Deep Learning Machine Learning Knowledge Reasoning Planning The promise of Deep Reinforcement Learning Action Effector



![[81, 165]](/docs-images/78/78642844/images/11-3.jpg)
11 Types of Deep Learning Supervised Learning Semi-Supervised Learning Reinforcement Learning Unsupervised Learning [81, 165]
12 Philosophical Motivation for Reinforcement Learning Takeaway from Supervised Learning: Neural networks are great at memorization and not (yet) great at reasoning. Hope for Reinforcement Learning: Brute-force propagation of outcomes to knowledge about states and actions. This is a kind of brute-force reasoning.
13 Agent and Environment At each step the agent: Executes action Receives observation (new state) Receives reward The environment: Receives action Emits observation (new state) Emits reward [80]


14 Examples of Reinforcement Learning Reinforcement learning is a general-purpose framework for decision-making: An agent operates in an environment: Atari Breakout An agent has the capacity to act Each action influences the agent s future state Success is measured by a reward signal Goal is to select actions to maximize future reward [85]
15 Examples of Reinforcement Learning Cart-Pole Balancing Goal Balance the pole on top of a moving cart State Pole angle, angular speed. Cart position, horizontal velocity. Actions horizontal force to the cart Reward 1 at each time step if the pole is upright [166]

16 Examples of Reinforcement Learning Doom Goal Eliminate all opponents State Raw game pixels of the game Actions Up, Down, Left, Right etc Reward Positive when eliminating an opponent, negative when the agent is eliminated [166]

17 Examples of Reinforcement Learning Bin Packing Goal - Pick a device from a box and put it into a container State - Raw pixels of the real world Actions - Possible actions of the robot Reward - Positive when placing a device successfully, negative otherwise [166]
18 Examples of Reinforcement Learning Human Life Goal - Survival? Happiness? State - Sight. Hearing. Taste. Smell. Touch. Actions - Think. Move. Reward Homeostasis?
19 Key Takeaways for Real-World Impact Deep Learning: Fun part: Good algorithms that learn from data. Hard part: Huge amounts of representative data. Deep Reinforcement Learning: Fun part: Good algorithms that learn from data. Hard part: Defining a useful state space, action space, and reward. Hardest part: Getting meaningful data for the above formalization.

20 Markov Decision Process s 0, a 0, r 1, s 1, a 1, r 2,, s n 1, a n 1, r n, s n state Terminal state action reward [84]
21 Major Components of an RL Agent An RL agent may include one or more of these components: Policy: agent s behavior function Value function: how good is each state and/or action Model: agent s representation of the environment s 0, a 0, r 1, s 1, a 1, r 2,, s n 1, a n 1, r n, s n state Terminal state action reward
22 Robot in a Room +1-1 actions: UP, DOWN, LEFT, RIGHT When actions are stochastic: UP START 80% move UP 10% move LEFT 10% move RIGHT reward +1 at [4,3], -1 at [4,2] reward for each step what s the strategy to achieve max reward? what if the actions were deterministic?
23 Is this a solution? +1-1 actions: UP, DOWN, LEFT, RIGHT When actions are stochastic: UP 80% move UP 10% move LEFT 10% move RIGHT only if actions deterministic not in this case (actions are stochastic) solution/policy mapping from each state to an action
24 Optimal policy +1-1 actions: UP, DOWN, LEFT, RIGHT When actions are stochastic: UP 80% move UP 10% move LEFT 10% move RIGHT
25 Reward for each step
26 Reward for each step:
27 Reward for each step:
28 Reward for each step:
29 Reward for each step:
30 Value Function Future reward R = r 1 + r 2 + r r n R t = r t + r t +1 + r t r n Discounted future reward (environment is stochastic) R t = r t + γr t+1 + γ 2 r t γ n t r n = r t + γ(r t+1 + γ(r t+2 + )) = r t + γr t+1 A good strategy for an agent would be to always choose an action that maximizes the (discounted) future reward References: [84]
31 Q-Learning s State-action value function: Q (s,a) Expected return when starting in s, performing a, and following s r a Q-Learning: Use any policy to estimate Q that maximizes future reward: Q directly approximates Q* (Bellman optimality equation) Independent of the policy being followed Only requirement: keep updating each (s,a) pair Learning Rate Discount Factor New State Old State Reward


32 Exploration vs Exploitation Deterministic/greedy policy won t explore all actions Don t know anything about the environment at the beginning Need to try all actions to find the optimal one ε-greedy policy With probability 1-ε perform the optimal/greedy action, otherwise random action Slowly move it towards greedy policy: ε -> 0

33 Q-Learning: Value Iteration A1 A2 A3 A4 S S S S References: [84]
 Consecutive 4 images Grayscale with 256 gray levels 256 84 84 4 rows in the Q-table!")
34 Q-Learning: Representation Matters In practice, Value Iteration is impractical Very limited states/actions Cannot generalize to unobserved states Think about the Breakout game State: screen pixels Image size: (resized) Consecutive 4 images Grayscale with 256 gray levels rows in the Q-table! References: [83, 84]
35 Philosophical Motivation for Deep Reinforcement Learning Takeaway from Supervised Learning: Neural networks are great at memorization and not (yet) great at reasoning. Hope for Reinforcement Learning: Brute-force propagation of outcomes to knowledge about states and actions. This is a kind of brute-force reasoning. Hope for Deep Learning + Reinforcement Learning: General purpose artificial intelligence through efficient generalizable learning of the optimal thing to do given a formalized set of actions and states (possibly huge).
36 Deep Learning is Representation Learning (aka Feature Learning) Deep Learning Representation Learning Machine Learning Artificial Intelligence Intelligence: Ability to accomplish complex goals. Understanding: Ability to turn complex information to into simple, useful information. [20]

37 DQN: Deep Q-Learning Use a function (with parameters) to approximate the Q-function Linear Non-linear: Q-Network [83]

38 Deep Q-Network (DQN): Atari Mnih et al. "Playing atari with deep reinforcement learning." [83]
39 DQN and Double DQN (DDQN) Loss function (squared error): target prediction DQN: same network for both Q DDQN: separate network for each Q Helps reduce bias introduced by the inaccuracies of Q network at the beginning of training [83]
40 DQN Tricks Experience Replay Stores experiences (actions, state transitions, and rewards) and creates mini-batches from them for the training process Fixed Target Network Error calculation includes the target function depends on network parameters and thus changes quickly. Updating it only every 1,000 steps increases stability of training process. Reward Clipping To standardize rewards across games by setting all positive rewards to +1 and all negative to -1. Skipping Frames Skip every 4 frames to take action [83, 167]
41 DQN Tricks Experience Replay Stores experiences (actions, state transitions, and rewards) and creates mini-batches from them for the training process Fixed Target Network Error calculation includes the target function depends on network parameters and thus changes quickly. Updating it only every 1,000 steps increases stability of training process. [83, 167]
42 Deep Q-Learning Algorithm [83, 167]
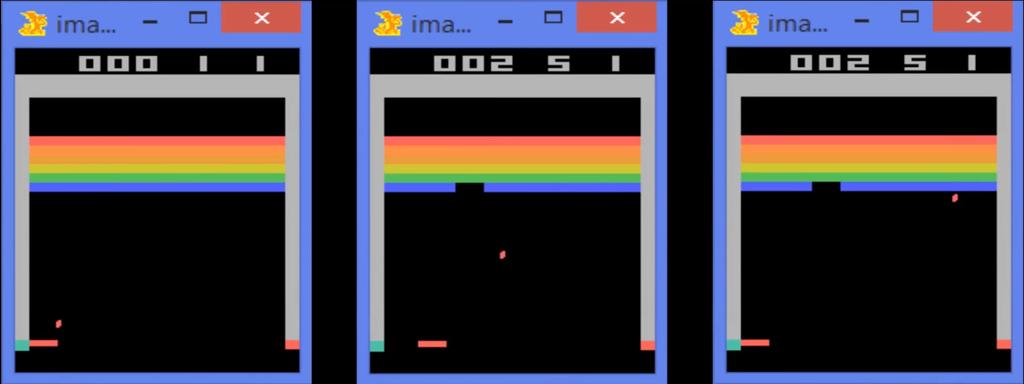
43 Atari Breakout After 10 Minutes of Training After 120 Minutes of Training After 240 Minutes of Training [85]

44 DQN Results in Atari [83]

45 Policy Gradients (PG) DQN (off-policy): Approximate Q and infer optimal policy PG (on-policy): Directly optimize policy space Good illustrative explanation: Deep Reinforcement Learning: Pong from Pixels Policy Network [63]
46 Policy Gradients Training REINFORCE (aka Actor-Critic): Policy gradient that increases probability of good actions and decreases probability of bad action: Policy network is the actor R t is the critic [63, 204]


47 Policy Gradients (PG) Pros vs DQN: Able to deal with more complex Q function Faster convergence Since Policy Gradients model probabilities of actions, it is capable of learning stochastic policies, while DQN can t. Cons: Needs more data [63]

48 Game of Go [170]
")

49 AlphaGo (2016) Beat Top Human at Go [83]
50 AlphaGo Zero (2017): Beats AlphaGo [149]
51 AlphaGo Zero Approach Same as the best before: Monte Carlo Tree Search (MCTS) Balance exploitation/exploration (going deep on promising positions or exploring new underplayed positions) Use a neural network as intuition for which positions to expand as part of MCTS (same as AlphaGo) [170]
52 AlphaGo Zero Approach Same as the best before: Monte Carlo Tree Search (MCTS) Balance exploitation/exploration (going deep on promising positions or exploring new underplayed positions) Use a neural network as intuition for which positions to expand as part of MCTS (same as AlphaGo) Tricks Use MCTS intelligent look-ahead (instead of human games) to improve value estimates of play options Multi-task learning: two-headed network that outputs (1) move probability and (2) probability of winning. Updated architecture: use residual networks [170]
 (in heads-up poker)")
53 DeepStack first to beat professional poker players (2017) (in heads-up poker) [150]
54 To date, for most successful robots operating in the real world: Deep RL is not involved (to the best of our knowledge)
")
55 To date, for most successful robots operating in the real world: Deep RL is not involved (to the best of our knowledge) [169]


56 Unexpected Local Pockets of High Reward [63, 64]
 Part of the Loss")
57 AI Safety Risk (and thus Human Life) Part of the Loss Function



58 DeepTraffic: Deep Reinforcement Learning Competition
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
LEGO MINDSTORMS Education EV3 Coding Activities
 LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Welcome to ACT Brain Boot Camp
 Welcome to ACT Brain Boot Camp 9:30 am - 9:45 am Basics (in every room) 9:45 am - 10:15 am Breakout Session #1 ACT Math: Adame ACT Science: Moreno ACT Reading: Campbell ACT English: Lee 10:20 am - 10:50
Welcome to ACT Brain Boot Camp 9:30 am - 9:45 am Basics (in every room) 9:45 am - 10:15 am Breakout Session #1 ACT Math: Adame ACT Science: Moreno ACT Reading: Campbell ACT English: Lee 10:20 am - 10:50
MYCIN. The MYCIN Task
 MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games
 Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Ohio s Learning Standards-Clear Learning Targets
 Ohio s Learning Standards-Clear Learning Targets Math Grade 1 Use addition and subtraction within 20 to solve word problems involving situations of 1.OA.1 adding to, taking from, putting together, taking
Ohio s Learning Standards-Clear Learning Targets Math Grade 1 Use addition and subtraction within 20 to solve word problems involving situations of 1.OA.1 adding to, taking from, putting together, taking
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Temper Tamer s Handbook
 Temper Tamer s Handbook Training School Psychologists to Be Experts in Evidence Based Practices for Tertiary Students with Serious Emotional Disturbance/Behavior Disorders US Office of Education 84.325K
Temper Tamer s Handbook Training School Psychologists to Be Experts in Evidence Based Practices for Tertiary Students with Serious Emotional Disturbance/Behavior Disorders US Office of Education 84.325K
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Cal s Dinner Card Deals
 Cal s Dinner Card Deals Overview: In this lesson students compare three linear functions in the context of Dinner Card Deals. Students are required to interpret a graph for each Dinner Card Deal to help
Cal s Dinner Card Deals Overview: In this lesson students compare three linear functions in the context of Dinner Card Deals. Students are required to interpret a graph for each Dinner Card Deal to help
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Quantitative Evaluation of an Intuitive Teaching Method for Industrial Robot Using a Force / Moment Direction Sensor
 International Journal of Control, Automation, and Systems Vol. 1, No. 3, September 2003 395 Quantitative Evaluation of an Intuitive Teaching Method for Industrial Robot Using a Force / Moment Direction
International Journal of Control, Automation, and Systems Vol. 1, No. 3, September 2003 395 Quantitative Evaluation of an Intuitive Teaching Method for Industrial Robot Using a Force / Moment Direction
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
The Success Principles How to Get from Where You Are to Where You Want to Be
 The Success Principles How to Get from Where You Are to Where You Want to Be Life is like a combination lock. If you know the combination to the lock... it doesn t matter who you are, the lock has to open.
The Success Principles How to Get from Where You Are to Where You Want to Be Life is like a combination lock. If you know the combination to the lock... it doesn t matter who you are, the lock has to open.
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
Surprise-Based Learning for Autonomous Systems
 Surprise-Based Learning for Autonomous Systems Nadeesha Ranasinghe and Wei-Min Shen ABSTRACT Dealing with unexpected situations is a key challenge faced by autonomous robots. This paper describes a promising
Surprise-Based Learning for Autonomous Systems Nadeesha Ranasinghe and Wei-Min Shen ABSTRACT Dealing with unexpected situations is a key challenge faced by autonomous robots. This paper describes a promising
Hentai High School A Game Guide
 Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I
 Session 1793 Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I John Greco, Ph.D. Department of Electrical and Computer Engineering Lafayette College Easton, PA 18042 Abstract
Session 1793 Designing a Computer to Play Nim: A Mini-Capstone Project in Digital Design I John Greco, Ph.D. Department of Electrical and Computer Engineering Lafayette College Easton, PA 18042 Abstract
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
FINAL ASSIGNMENT: A MYTH. PANDORA S BOX
 089-INTRODUCING THE ADVANCED ENGLISH CURRICULUM: TOOLS, STRATEGIES AND RESOURCES FINAL ASSIGNMENT: A MYTH. PANDORA S BOX PABLO MORENO RIBAGORDA 1 LESSON PLAN: A MYTH -CLASS PROFILE & TEACHING CONTEXT-
089-INTRODUCING THE ADVANCED ENGLISH CURRICULUM: TOOLS, STRATEGIES AND RESOURCES FINAL ASSIGNMENT: A MYTH. PANDORA S BOX PABLO MORENO RIBAGORDA 1 LESSON PLAN: A MYTH -CLASS PROFILE & TEACHING CONTEXT-
A BOOK IN A SLIDESHOW. The Dragonfly Effect JENNIFER AAKER & ANDY SMITH
 A BOOK IN A SLIDESHOW The Dragonfly Effect JENNIFER AAKER & ANDY SMITH THE DRAGONFLY MODEL FOCUS GRAB ATTENTION TAKE ACTION ENGAGE A Book In A Slideshow JENNIFER AAKER & ANDY SMITH WING 1: FOCUS IDENTIFY
A BOOK IN A SLIDESHOW The Dragonfly Effect JENNIFER AAKER & ANDY SMITH THE DRAGONFLY MODEL FOCUS GRAB ATTENTION TAKE ACTION ENGAGE A Book In A Slideshow JENNIFER AAKER & ANDY SMITH WING 1: FOCUS IDENTIFY
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
An Introduction to Simulation Optimization
 An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Interaction Design Considerations for an Aircraft Carrier Deck Agent-based Simulation
 Interaction Design Considerations for an Aircraft Carrier Deck Agent-based Simulation Miles Aubert (919) 619-5078 Miles.Aubert@duke. edu Weston Ross (505) 385-5867 Weston.Ross@duke. edu Steven Mazzari
Interaction Design Considerations for an Aircraft Carrier Deck Agent-based Simulation Miles Aubert (919) 619-5078 Miles.Aubert@duke. edu Weston Ross (505) 385-5867 Weston.Ross@duke. edu Steven Mazzari
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE. Junior Year. Summer (Bridge Quarter) Fall Winter Spring GAME Credits.
 Fall Winter Spring GAME Credits.") DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
GACE Computer Science Assessment Test at a Glance
 GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
B. How to write a research paper
 From: Nikolaus Correll. "Introduction to Autonomous Robots", ISBN 1493773070, CC-ND 3.0 B. How to write a research paper The final deliverable of a robotics class often is a write-up on a research project,
From: Nikolaus Correll. "Introduction to Autonomous Robots", ISBN 1493773070, CC-ND 3.0 B. How to write a research paper The final deliverable of a robotics class often is a write-up on a research project,
Appendix L: Online Testing Highlights and Script
 Online Testing Highlights and Script for Fall 2017 Ohio s State Tests Administrations Test administrators must use this document when administering Ohio s State Tests online. It includes step-by-step directions,
Online Testing Highlights and Script for Fall 2017 Ohio s State Tests Administrations Test administrators must use this document when administering Ohio s State Tests online. It includes step-by-step directions,
MGT/MGP/MGB 261: Investment Analysis
 UNIVERSITY OF CALIFORNIA, DAVIS GRADUATE SCHOOL OF MANAGEMENT SYLLABUS for Fall 2014 MGT/MGP/MGB 261: Investment Analysis Daytime MBA: Tu 12:00p.m. - 3:00 p.m. Location: 1302 Gallagher (CRN: 51489) Sacramento
UNIVERSITY OF CALIFORNIA, DAVIS GRADUATE SCHOOL OF MANAGEMENT SYLLABUS for Fall 2014 MGT/MGP/MGB 261: Investment Analysis Daytime MBA: Tu 12:00p.m. - 3:00 p.m. Location: 1302 Gallagher (CRN: 51489) Sacramento
Essentials of Ability Testing. Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology
 Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Using the CU*BASE Member Survey
 Using the CU*BASE Member Survey INTRODUCTION Now more than ever, credit unions are realizing that being the primary financial institution not only for an individual but for an entire family may be the
Using the CU*BASE Member Survey INTRODUCTION Now more than ever, credit unions are realizing that being the primary financial institution not only for an individual but for an entire family may be the
Classify: by elimination Road signs
 WORK IT Road signs 9-11 Level 1 Exercise 1 Aims Practise observing a series to determine the points in common and the differences: the observation criteria are: - the shape; - what the message represents.
WORK IT Road signs 9-11 Level 1 Exercise 1 Aims Practise observing a series to determine the points in common and the differences: the observation criteria are: - the shape; - what the message represents.
Bluetooth mlearning Applications for the Classroom of the Future
 Bluetooth mlearning Applications for the Classroom of the Future Tracey J. Mehigan, Daniel C. Doolan, Sabin Tabirca Department of Computer Science, University College Cork, College Road, Cork, Ireland
Bluetooth mlearning Applications for the Classroom of the Future Tracey J. Mehigan, Daniel C. Doolan, Sabin Tabirca Department of Computer Science, University College Cork, College Road, Cork, Ireland
Algebra 2- Semester 2 Review
 Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain