10703 Deep Reinforcement Learning and Control
|
|
|
- Owen Malone
- 6 years ago
- Views:
Transcription
1 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Slides borrowed from Katerina Fragkiadaki Learning and Planning with Tabular Methods

2 What can I learn by interacting with the world?! Past classes: the agent learned to estimate value functions and optimal policies from experience.! state action S t A t reward R t
3 Model-free RL Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Policy
 and just use it to plan and estimate")
.! - Very slow when many states.")
4 What can I learn by interacting with the world?! - So far: We know the true environment (dynamics and rewards) and just use it to plan and estimate value functions (value iteration, policy iteration using exhaustive state sweeps of Bellman back-up operations).! - Very slow when many states.! Planning: any computational process that uses a model to create or improve a policy! Model! Planning! Policy!
5 Planning Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Policy

6 What can I learn by interacting with the world?! This lecture: we will combine both, learning from experience and planning:! - If the model is unknown, we will learn the model.!


7 What can I learn by interacting with the world?! This lecture: we will combine both, learning from experience and planning:! - If the model is unknown, we will learn the model! - Learn value functions using both real and simulated experience!

8 What can I learn by interacting with the world?! This lecture: we will combine both, learning from experience and planning:! - If the model is unknown, we will learn the model! - Learn value functions using both real and simulated experience! - Learn value functions online using model-based look-ahead search!


9 What can I learn by interacting with the world?! This lecture: we will combine both, learning from experience and planning:! - If the model is unknown, we will learn the model! - Learn value functions using both real and simulated experience! - Learn value functions online using model-based look-ahead search!

10 Model-based RL Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Policy
11 Advantages of Model-Based RL! Advantages: Model learning transfers across tasks and environment configurations (learning physics) Better exploits experience in case of sparse rewards It is probably what the brain does (more later) Helps exploration: Can reason about model uncertainty Disadvantages: First learn model, then construct a value function: Two sources of approximation error
")
12 What is a Model?! Model: anything the agent can use to predict how the environment will respond to its actions: -- specifically, the transition (dynamics) T(s s,a) and reward functions R(s,a).! this includes transitions of the state of the environment and the state of the agent.!
13 What is a Model?! Model: anything the agent can use to predict how the environment will respond to its actions, specifically:! - the transition function (dynamics)! - reward function! Distribution model: description of all possibilities and their probabilities, T(s s,a) for all (s, a, s ) Sample model, a.k.a. a simulation model: produces sample experiences for a given s, often much easier to come by! Both types of models can be used to produce hypothetical experience (what if )!

14 Model Learning! - If the model is unknown, we will learn the model.! - Learn value functions using both real and simulated experience! - Learn value functions online using model-based lookahead search!

15 Model Learning! Goal: estimate model from experience This can be thought as a supervised learning problem Learning Learning is a regression problem is a density estimation problem Pick loss function, e.g. mean-squared error, KL divergence Find parameters that minimize empirical loss
:")


16 Examples of Models for T(s s,a)! Table lookup model (tabular): bookkeeping a probability of occurrence for each transition (s,a,s ) Transition function is approximated through some function approximator A! S! S!

17 A supervised learning problem?! To look ahead far in the future you need to chain your dynamic predictions! Data is sequential! i.i.d. assumptions break! Errors accumulate in time! Solutions:! - Hierarchical dynamics models! - Linear local approximations!
18 Examples of Models for T(s s,a)! Table lookup model (tabular): bookkeeping a probability of occurrence for each transition (s,a,s ) Transition function is approximated through some features This Lecture Later..
19 Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Policy


20 Table Lookup Model! Model is an explicit MDP, Count visits to each state action pair Alternatively At each time-step, record experience tuple To sample model, randomly pick tuple matching
21 A simple Example! Two states A,B; no discounting; 8 episodes of experience A, 0, B, 0! B, 1! B, 1! B, 1! B, 1! B, 1! B, 1! B, 0! We have constructed a table lookup model from the experience
22 Planning with a Model! Given a model Solve the MDP Using favorite planning algorithm Value iteration Policy iteration Tree search curse of dimensionality!!
23 Planning with a Model! Given a model Solve the MDP Using favorite planning algorithm Value iteration Policy iteration Tree search Sample-based planning
24 Sample-based Planning! Use the model only to generate samples, not using its transition probabilities and expected immediate rewards Sample experience from model Apply model-free RL to samples, e.g.: Monte-Carlo control Sarsa Q-learning Sample-based planning methods are often more efficient: rather than exhaustive state sweeps: we focus on what is likely to happen

25 Sample-based planning Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Policy
26 A Simple Example! Construct a table-lookup model from real experience Apply model-free RL to sampled experience A, 0, B, 0! B, 1! B, 1! B, 1! B, 1! B, 1! B, 1! B, 0! e.g. Monte-Carlo learning:
27 Planning with an Inaccurate Model! Given an imperfect model Performance of model-based RL is limited to optimal policy for approximate MDP i.e. Model-based RL is only as good as the estimated model When the model is inaccurate, planning process will compute a suboptimal policy Solution 1: when model is wrong, use model-free RL Solution 2: reason explicitly about model uncertainty
28 Combine real and simulated experience! - If the model is unknown, we will learn the model.! - Learn value functions using both real and simulated experience! - Learn value functions online using model-based lookahead search!
29 Real and Simulated Experience! We consider two sources of experience Real experience - Sampled from environment (true MDP) Simulated experience - Sampled from model (approximate MD)
30 Integrating Learning and Planning! Model-Free RL No model Learn value function (and/or policy) from real experience
31 Integrating Learning and Planning! Model-Free RL No model Learn value function (and/or policy) from real experience Model-Based RL (using Sample-Based Planning) Learn a model from real experience Plan value function (and/or policy) from simulated experience
32 Integrating Learning and Planning! Model-Free RL No model Learn value function (and/or policy) from real experience Model-Based RL (using Sample-Based Planning) Dyna Learn a model from real experience Plan value function (and/or policy) from simulated experience Learn a model from real experience Learn and plan value function (and/or policy) from real and simulated experience
33 Dyna Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Policy
34 Dyna-Q Algorithm!
35 Dyna-Q on a Simple Maze!
36 Midway in 2nd Episode!
37 Midway in 2nd Episode!
38 Dyna-Q with an Inaccurate Model! The changed environment is harder
39 Dyna-Q with an Inaccurate model Cont.! The changed environment is easier
40 Sampling-based look-ahead search! - If the model is unknown, we will learn the model.! - Learn value functions using both real and simulated experience! - Learn value functions online using model-based lookahead search!


41 Forward Search Model Planning! Interaction with Environment! Experience Direct RL methods! Value function Greedification! Action (from a given state s)
42 Forward Search! Prioritizes the state the agent is currently in Using a model of the MDP to look ahead (exhaustively) Builds a search tree with the current state at the root Focus on sub-mdp starting from now, often dramatically easier than solving the whole MDP s t T! T! T! T! T! T! T! T! T! T!
43 Why Forward search?! Why don t we learn a value function directly for every state offline, so that we do not waste time online? Because the environment has many many states (consider Go 10^170, Chess 10^48, real world.) Very hard to compute a good value function for each one, most you will never even visit Thus, it makes sense, condition on the current state you are in, to try to estimate the value function of the relevant part of the state space online Use the the online forward search to pick the best action Disadvantages: Nothing is learnt from episode to episode
44 Simulation-based Search I! Forward search paradigm using sample-based planning Simulate episodes of experience starting from now with the model Apply model-free RL to simulated episodes s t T! T! T! T! T! T! T! T! T! T!
45 Simulation-Based Search II! Simulate episodes of experience from now with the model Apply model-free RL to simulated episodes Monte-Carlo control Monte-Carlo search

")
46 Simple Monte-Carlo Search! Given a model and a simulation policy For each action Simulate episodes from current (real) state : Evaluate action value function of the root by mean return (Monte-Carlo evaluation) Select current (real) action with maximum value
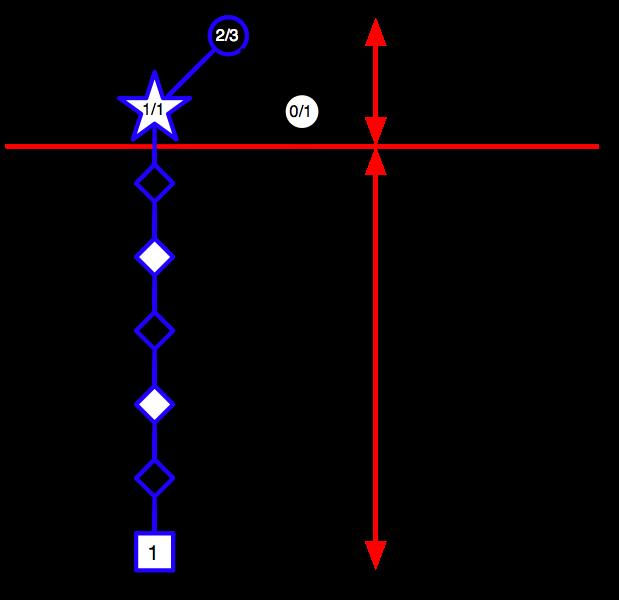
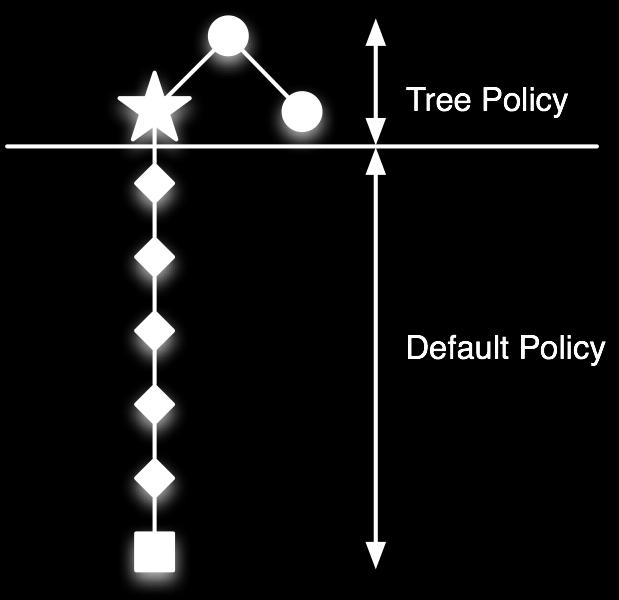
47 Monte-Carlo Tree Search (Evaluation)! Given a model Simulate episodes from current state using current simulation policy Build a search tree containing visited states and actions Evaluate states by mean return of episodes from for all states and actions in the tree After search is finished, select current (real) action with maximum value in search tree
48 Monte-Carlo Tree Search (Simulation)! In MCTS, the simulation policy improves Each simulation consists of two phases (in-tree, out-of-tree) Tree policy (improves): pick actions to maximize Default policy (fixed): pick actions randomly Repeat (each simulation) Evaluate states by Monte-Carlo evaluation Improve there policy, e.g. by Monte-Carlo control applied to simulated experience Converges on the optimal search tree,

49 Case Study: the Game of Go! The ancient oriental game of Go is 2500 years old Considered to be the hardest classic board game Considered a grand challenge task for AI (John McCarthy) Traditional game-tree search has failed in Go


50 Rules of Go! Usually played on 19x19, also 13x13 or 9x9 board Simple rules, complex strategy Black and white place down stones alternately Surrounded stones are captured and removed The player with more territory wins the game
: for all non-terminal steps Policy selects moves for both")
51 Position Evaluation in Go! How good is a position? Reward function (undiscounted): for all non-terminal steps Policy selects moves for both players Value function (how good is position ):

52 Monte-Carlo Evaluation in Go! V(s) = 2/4 = 0.5 Current position s Simulation Outcomes

53 Applying Monte-Carlo Tree Search!

54 Applying Monte-Carlo Tree Search!
55 Applying Monte-Carlo Tree Search!

56 Applying Monte-Carlo Tree Search!

57 Applying Monte-Carlo Tree Search!
58 Advantages of MC Tree Search! Highly selective: best-first search Evaluate states dynamically (unlike e.g. DP) Uses sampling to break curse of dimensionality Computationally efficient, anytime, parallelizable
59 Combining offline and online value function estimation! Use policy networks to have priors on Q(s,a): Use fast and light policy networks for rollouts (instead of random policy)
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Acquiring Competence from Performance Data
 Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Rule-based Expert Systems
 Rule-based Expert Systems What is knowledge? is a theoretical or practical understanding of a subject or a domain. is also the sim of what is currently known, and apparently knowledge is power. Those who
Rule-based Expert Systems What is knowledge? is a theoretical or practical understanding of a subject or a domain. is also the sim of what is currently known, and apparently knowledge is power. Those who
MYCIN. The MYCIN Task
 MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling
 Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE. Junior Year. Summer (Bridge Quarter) Fall Winter Spring GAME Credits.
 Fall Winter Spring GAME Credits.") DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
TU-E2090 Research Assignment in Operations Management and Services
 Aalto University School of Science Operations and Service Management TU-E2090 Research Assignment in Operations Management and Services Version 2016-08-29 COURSE INSTRUCTOR: OFFICE HOURS: CONTACT: Saara
Aalto University School of Science Operations and Service Management TU-E2090 Research Assignment in Operations Management and Services Version 2016-08-29 COURSE INSTRUCTOR: OFFICE HOURS: CONTACT: Saara
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Emergency Management Games and Test Case Utility:
 IST Project N 027568 IRRIIS Project Rome Workshop, 18-19 October 2006 Emergency Management Games and Test Case Utility: a Synthetic Methodological Socio-Cognitive Perspective Adam Maria Gadomski, ENEA
IST Project N 027568 IRRIIS Project Rome Workshop, 18-19 October 2006 Emergency Management Games and Test Case Utility: a Synthetic Methodological Socio-Cognitive Perspective Adam Maria Gadomski, ENEA
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search
 Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Using Deep Convolutional Neural Networks in Monte Carlo Tree Search Tobias Graf (B) and Marco Platzner University of Paderborn, Paderborn, Germany tobiasg@mail.upb.de, platzner@upb.de Abstract. Deep Convolutional
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS
 EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS by Robert Smith Submitted in partial fulfillment of the requirements for the degree of Master of
EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS by Robert Smith Submitted in partial fulfillment of the requirements for the degree of Master of
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Planning with External Events
 94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games
 Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
give every teacher everything they need to teach mathematics
 give every teacher everything they need to teach mathematics AUSTRALIA give every teacher everything ORIGO Stepping Stones is an award winning, core mathematics program developed by specialists for Australian
give every teacher everything they need to teach mathematics AUSTRALIA give every teacher everything ORIGO Stepping Stones is an award winning, core mathematics program developed by specialists for Australian
Evidence-based Practice: A Workshop for Training Adult Basic Education, TANF and One Stop Practitioners and Program Administrators
 Evidence-based Practice: A Workshop for Training Adult Basic Education, TANF and One Stop Practitioners and Program Administrators May 2007 Developed by Cristine Smith, Beth Bingman, Lennox McLendon and
Evidence-based Practice: A Workshop for Training Adult Basic Education, TANF and One Stop Practitioners and Program Administrators May 2007 Developed by Cristine Smith, Beth Bingman, Lennox McLendon and
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Universal Design for Learning Lesson Plan
 Universal Design for Learning Lesson Plan Teacher(s): Alexandra Romano Date: April 9 th, 2014 Subject: English Language Arts NYS Common Core Standard: RL.5 Reading Standards for Literature Cluster Key
Universal Design for Learning Lesson Plan Teacher(s): Alexandra Romano Date: April 9 th, 2014 Subject: English Language Arts NYS Common Core Standard: RL.5 Reading Standards for Literature Cluster Key
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Investigate the program components
 Investigate the program components ORIGO Stepping Stones is an award-winning core mathematics program developed by specialists for Australian primary schools. Stepping Stones provides every teacher with
Investigate the program components ORIGO Stepping Stones is an award-winning core mathematics program developed by specialists for Australian primary schools. Stepping Stones provides every teacher with
PreReading. Lateral Leadership. provided by MDI Management Development International
 PreReading Lateral Leadership NEW STRUCTURES REQUIRE A NEW ATTITUDE In an increasing number of organizations hierarchies lose their importance and instead companies focus on more network-like structures.
PreReading Lateral Leadership NEW STRUCTURES REQUIRE A NEW ATTITUDE In an increasing number of organizations hierarchies lose their importance and instead companies focus on more network-like structures.
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Introduction to Questionnaire Design
 Introduction to Questionnaire Design Why this seminar is necessary! Bad questions are everywhere! Don t let them happen to you! Fall 2012 Seminar Series University of Illinois www.srl.uic.edu The first
Introduction to Questionnaire Design Why this seminar is necessary! Bad questions are everywhere! Don t let them happen to you! Fall 2012 Seminar Series University of Illinois www.srl.uic.edu The first
Telekooperation Seminar
 Telekooperation Seminar 3 CP, SoSe 2017 Nikolaos Alexopoulos, Rolf Egert. {alexopoulos,egert}@tk.tu-darmstadt.de based on slides by Dr. Leonardo Martucci and Florian Volk General Information What? Read
Telekooperation Seminar 3 CP, SoSe 2017 Nikolaos Alexopoulos, Rolf Egert. {alexopoulos,egert}@tk.tu-darmstadt.de based on slides by Dr. Leonardo Martucci and Florian Volk General Information What? Read
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Lecturing Module
 Lecturing: What, why and when www.facultydevelopment.ca Lecturing Module What is lecturing? Lecturing is the most common and established method of teaching at universities around the world. The traditional
Lecturing: What, why and when www.facultydevelopment.ca Lecturing Module What is lecturing? Lecturing is the most common and established method of teaching at universities around the world. The traditional
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge
 Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Expert Reference Series of White Papers. Mastering Problem Management
 Expert Reference Series of White Papers Mastering Problem Management 1-800-COURSES www.globalknowledge.com Mastering Problem Management Hank Marquis, PhD, FBCS, CITP Introduction IT Organization (ITO)
Expert Reference Series of White Papers Mastering Problem Management 1-800-COURSES www.globalknowledge.com Mastering Problem Management Hank Marquis, PhD, FBCS, CITP Introduction IT Organization (ITO)
Uncertainty concepts, types, sources
 Copernicus Institute SENSE Autumn School Dealing with Uncertainties Bunnik, 8 Oct 2012 Uncertainty concepts, types, sources Dr. Jeroen van der Sluijs j.p.vandersluijs@uu.nl Copernicus Institute, Utrecht
Copernicus Institute SENSE Autumn School Dealing with Uncertainties Bunnik, 8 Oct 2012 Uncertainty concepts, types, sources Dr. Jeroen van der Sluijs j.p.vandersluijs@uu.nl Copernicus Institute, Utrecht
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
Conceptual and Procedural Knowledge of a Mathematics Problem: Their Measurement and Their Causal Interrelations
 Conceptual and Procedural Knowledge of a Mathematics Problem: Their Measurement and Their Causal Interrelations Michael Schneider (mschneider@mpib-berlin.mpg.de) Elsbeth Stern (stern@mpib-berlin.mpg.de)
Conceptual and Procedural Knowledge of a Mathematics Problem: Their Measurement and Their Causal Interrelations Michael Schneider (mschneider@mpib-berlin.mpg.de) Elsbeth Stern (stern@mpib-berlin.mpg.de)
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Executive Guide to Simulation for Health
 Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
An Introduction to Simulation Optimization
 An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
1.1 Examining beliefs and assumptions Begin a conversation to clarify beliefs and assumptions about professional learning and change.
 TOOLS INDEX TOOL TITLE PURPOSE 1.1 Examining beliefs and assumptions Begin a conversation to clarify beliefs and assumptions about professional learning and change. 1.2 Uncovering assumptions Identify
TOOLS INDEX TOOL TITLE PURPOSE 1.1 Examining beliefs and assumptions Begin a conversation to clarify beliefs and assumptions about professional learning and change. 1.2 Uncovering assumptions Identify