COMP 551 Applied Machine Learning Lecture 12: Ensemble learning
|
|
|
- Anis George
- 6 years ago
- Views:
Transcription
1 COMP 551 Applied Machine Learning Lecture 12: Ensemble learning Associate Instructor: Herke van Hoof Slides mostly by: Class web page: Unless otherwise noted, all material posted for this course are copyright of the instructor, and cannot be reused or reposted without the instructor s written permission.
2 Today s quiz 1. Output of 1NN for A? 2. Output of 3NN for A? 3. Output of 3NN for B? 4. Explain in 1-2 sentences the difference between a "lazy" learner (such as nearest neighbour classifier) and an "eager" learner (such as logistic regression classifier). 2
3 Project #2 A note on the contest rules: You are allowed to use the built-in cross-validation methods from libraries like scikit-learn, for all parts. You are allowed to use NLTK or another library for preprocessing your data for all parts You can use an outside corpus to evaluate the features (e.g. TF-IDF). 3
4 Project #2 4
5 Project #2 Some features: Sub-word features (skiing: ski kii iin - ing) allows out-ofvocabulary and misspelling Languages in hierarchical tree make use of inbalance in classes K-means and feature selection to reduce model size 5
6 Next topic: Ensemble methods Recently seen supervised learning methods: Logistic regression, Naïve Bayes, LDA/QDA Decision trees, Instance-based learning Core idea of decision trees? Build complex classifiers from simpler ones. E.g. Linear separator -> Decision trees Ensemble methods use this idea with other simple methods Several ways to do this. Bagging Random forests Boosting Lectures 4,5 Linear Classification Lecture 7 Decision Trees 6
7 Ensemble learning in general Key idea: Run a base learning algorithm multiple times, then combine the predictions of the different learners to get a final prediction. What s a base learning algorithm? Naïve Bayes, LDA, Decision trees, SVMs, 7
8 Ensemble learning in general Key idea: Run a base learning algorithm multiple times, then combine the predictions of the different learners to get a final prediction. What s a base learning algorithm? Naïve Bayes, LDA, Decision trees, SVMs, First attempt: Construct several classifiers independently. Bagging. Randomizing the test selection in decision trees (Random forests). Using a different subset of input features to train different trees. 8
9 Ensemble learning in general Key idea: Run a base learning algorithm multiple times, then combine the predictions of the different learners to get a final prediction. What s a base learning algorithm? Naïve Bayes, LDA, Decision trees, SVMs, First attempt: Construct several classifiers independently. Bagging. Randomizing the test selection in decision trees (Random forests). Using a different subset of input features to train different trees. More complex approach: Coordinate the construction of the hypotheses in the ensemble. 9
10 Ensemble methods in general Training models independently on same dataset tends to yield same result! For an ensemble to be useful, trained models need to be different 1. Use slightly different (randomized) datasets 2. Use slightly different (randomized) training procedure 10
11 Recall bootstrapping Lecture 6 Evaluation Given dataset D, construct a bootstrap replicate of D, called D k, which has the same number of examples, by drawing samples from D with replacement. Use the learning algorithm to construct a hypothesis h k by training on D k. Compute the prediction of h k on each of the remaining points, from the set T k = D D k. Repeat this process K times, where K is typically a few hundred. 11
12 Estimating bias and variance For each point x, we have a set of estimates h 1 (x),, h K (x), with K B (since x might not appear in some replicates). The average empirical prediction of x is: ĥ (x) = (1/K) k=1:k h k (x). We estimate the bias as: y ĥ(x). We estimate the variance as: (1/(K-1)) k=1:k ( ĥ(x) - h k (x) ) 2. 12
13 Bagging: Bootstrap aggregation If we did all the work to get the hypotheses h b, why not use all of them to make a prediction? (as opposed to just estimating bias/variance/error). All hypotheses get to have a vote. For classification: pick the majority class. For regression, average all the predictions. Which hypotheses classes would benefit most from this approach? 13
14 Bagging For each point x, we have a set of estimates h 1 (x),, h K (x), with K B (since x might not appear in some replicates). The average empirical prediction of x is: ĥ (x) = (1/K) k=1:k h k (x). We estimate the bias as: y ĥ(x). We estimate the variance as: (1/(K-1)) k=1:k ( ĥ(x) - h k (x) ) 2. 14
15 Bagging In theory, bagging eliminates variance altogether. In practice, bagging tends to reduce variance and increase bias. Use this with unstable learners that have high variance, e.g. decision trees, neural networks, nearest-neighbour. 15
16 Random forests (Breiman, 2001) Basic algorithm: Use K bootstrap replicates to train K different trees. At each node, pick m variables at random (use m<m, the total number of features). Determine the best test (using normalized information gain). Recurse until the tree reaches maximum depth (no pruning). 16
17 Random forests (Breiman, 2001) Basic algorithm: Use K bootstrap replicates to train K different trees. At each node, pick m variables at random (use m<m, the total number of features). Determine the best test (using normalized information gain). Recurse until the tree reaches maximum depth (no pruning). Comments: Each tree has high variance, but the ensemble uses averaging, which reduces variance. Random forests are very competitive in both classification and regression, but still subject to overfitting. 17
18 Extremely randomized trees (Geurts et al., 2006) Basic algorithm: Construct K decision trees. Pick m attributes at random (without replacement) and pick a random test involving each attribute. Evaluate all tests (using a normalized information gain metric) and pick the best one for the node. Continue until a desired depth or a desired number of instances (n min ) at the leaf is reached. 18
19 Extremely randomized trees (Geurts et al., 2005) Basic algorithm: Construct K decision trees. Pick m attributes at random (without replacement) and pick a random test involving each attribute. Evaluate all tests (using a normalized information gain metric) and pick the best one for the node. Continue until a desired depth or a desired number of instances (n min ) at the leaf is reached. Comments: Very reliable method for both classification and regression. The smaller m is, the more randomized the trees are; small m is best, especially with large levels of noise. Small n min means less bias and more variance, but variance is controlled by averaging over trees. Compared to single trees, can pick smaller n min (less bias) 19
20 Randomization For an ensemble to be useful, trained models need to be different 1. Use slightly different (randomized) datasets Bootstrap Aggregation (Bagging) 2. Use slightly different (randomized) training procedure Extremely randomized trees, Random Forests 20
21 Randomization in general Instead of searching very hard for the best hypothesis, generate lots of random ones, then average their results. Examples: Random feature selection Random projections. Advantages? Disadvantages? 21
22 Randomization in general Instead of searching very hard for the best hypothesis, generate lots of random ones, then average their results. Examples: Random feature selection Random projections. Advantages? Very fast, easy, can handle lots of data. Can circumvent difficulties in optimization. Averaging reduces the variance introduced by randomization. Disadvantages? 22
23 Randomization in general Instead of searching very hard for the best hypothesis, generate lots of random ones, then average their results. Examples: Random feature selection Random projections. Advantages? Very fast, easy, can handle lots of data. Can circumvent difficulties in optimization. Averaging reduces the variance introduced by randomization. Disadvantages? New prediction may be more expensive to evaluate (go over all trees). Still typically subject to overfitting. Low interpretability compared to standard decision trees. 23
24 Randomization For an ensemble to be useful, trained models need to be different 1. Use slightly different (randomized) datasets Bootstrap Aggregation (Bagging) 2. Use slightly different (randomized) training procedure Extremely randomized trees, Random Forests 3. Alternative method to randomization? 24
25 Additive models In an ensemble, the output on any instance is computed by averaging the outputs of several hypotheses. Idea: Don t construct the hypotheses independently. Instead, new hypotheses should focus on instances that are problematic for existing hypotheses. If an example is difficult, more components should focus on it. 25
26 Boosting Boosting: Use the training set to train a simple predictor. Re-weight the training examples, putting more weight on examples that were not properly classified in the previous predictor. Repeat n times. Combine the simple hypotheses into a single, accurate predictor. D1 Weak Learner H1 Original Data D2 Weak Learner H2 Final hypothesis Dn Weak Learner Hn F(H1,H2,...Hn) 26
27 Notation Assume that examples are drawn independently from some probability distribution P on the set of possible data D. Let J P (h) be the expected error of hypothesis h when data is drawn from P: J P (h) = <x,y> J(h(x),y)P(<x,y>) where J(h(x),y) could be the squared error, or 0/1 loss. 27
28 Weak learners Assume we have some weak binary classifiers: A decision stump is a single node decision tree: x i >t A single feature Naïve Bayes classifier. A 1-nearest neighbour classifier. Weak means J P (h)<1/2-ɣ (assuming 2 classes), where ɣ>0 So true error of the classifier is only slightly better than random. Questions: How do we re-weight the examples? How do we combine many simple predictors into a single classifier? 28
29 Example 29
30 Example: First step 30
31 Example: Second step 31
32 Example: Third step 32

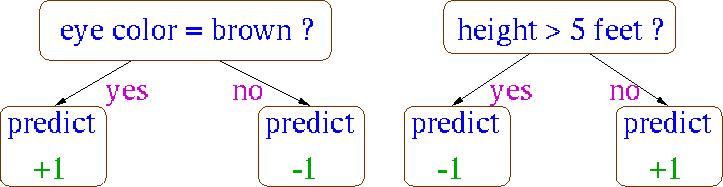
33 Example: Final hypothesis 33
34 AdaBoost (Freund & Schapire, 1995) 34
35 AdaBoost (Freund & Schapire, 1995) 35
36 AdaBoost (Freund & Schapire, 1995) weight of weak learner t 36
37 AdaBoost (Freund & Schapire, 1995) weight of weak learner t 37
38 AdaBoost (Freund & Schapire, 1995) weight of weak learner t 38
39 Why these equations? Loss function: m i = y i NX L = K X k=1 i=1 e m i k h k (x i ) Has a gradient Upper bound on classification loss Stronger signal for wrong classifications Stronger signal if wrong and far from boundary 39
40 Why these equations? Loss function: m i = y i NX L = K X k=1 i=1 e m i k h k (x i ) Update equations are derived from this loss function 40
41 Properties of AdaBoost Compared to other boosting algorithms, main insight is to automatically adapt the error rate at each iteration. 41
42 Properties of AdaBoost Compared to other boosting algorithms, main insight is to automatically adapt the weights at each iteration. Training error on the final hypothesis is at most: recall: ɣ t is how much better than random is h t AdaBoost gradually reduces the training error exponentially fast. 42
43 Real data set: Text categorization ;5)585,*/%N6% ;5)585,*/%:*1)*7,% 43


44 Boosting empirical evaluation error error error C4.5: Lecture 7 Decision Trees 44
45 Bagging vs Boosting boosting C bagging C4.5 45
46 Bagging vs Boosting Bagging is typically faster, but may get a smaller error reduction (not by much). Bagging works well with reasonable classifiers. Boosting works with very simple classifiers. E.g., Boostexter - text classification using decision stumps based on single words. Boosting may have a problem if a lot of the data is mislabeled, because it will focus on those examples a lot, leading to overfitting. 46
47 Why does boosting work? 47
48 Why does boosting work? Weak learners have high bias. By combining them, we get more expressive classifiers. Hence, boosting is a bias-reduction technique. 48
49 Why does boosting work? Weak learners have high bias. By combining them, we get more expressive classifiers. Hence, boosting is a bias-reduction technique. Adaboost minimizes an upper bound on the misclassifcation error, within the space of functions that can be captured by a linear combination of the base classifiers. What happens as we run boosting longer? Intuitively, we get more and more complex hypotheses. How would you expect bias and variance to evolve over time? 49
50 A naïve (but reasonable) analysis of error Expect the training error to continue to drop (until it reaches 0). Expect the test error to increase as we get more voters, and h f becomes too complex
51 Actual typical run of AdaBoost Test error does not increase even after 1000 runs! (more than 2 million decision nodes!) Test error continues to drop even after training error reaches 0! These are consistent results through many sets of experiments! Conjecture: Boosting does not overfit!
52 What you should know Ensemble methods combine several hypotheses into one prediction. They work better than the best individual hypothesis from the same class because they reduce bias or variance (or both). Extremely randomized trees are a bias-reduction technique. Bagging is mainly a variance-reduction technique, useful for complex hypotheses. Main idea is to sample the data repeatedly, train several classifiers and average their predictions. Boosting focuses on harder examples, and gives a weighted vote to the hypotheses. Boosting works by reducing bias and increasing classification margin. 52
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
The Boosting Approach to Machine Learning An Overview
 Nonlinear Estimation and Classification, Springer, 2003. The Boosting Approach to Machine Learning An Overview Robert E. Schapire AT&T Labs Research Shannon Laboratory 180 Park Avenue, Room A203 Florham
Nonlinear Estimation and Classification, Springer, 2003. The Boosting Approach to Machine Learning An Overview Robert E. Schapire AT&T Labs Research Shannon Laboratory 180 Park Avenue, Room A203 Florham
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Optimizing to Arbitrary NLP Metrics using Ensemble Selection
 Optimizing to Arbitrary NLP Metrics using Ensemble Selection Art Munson, Claire Cardie, Rich Caruana Department of Computer Science Cornell University Ithaca, NY 14850 {mmunson, cardie, caruana}@cs.cornell.edu
Optimizing to Arbitrary NLP Metrics using Ensemble Selection Art Munson, Claire Cardie, Rich Caruana Department of Computer Science Cornell University Ithaca, NY 14850 {mmunson, cardie, caruana}@cs.cornell.edu
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Activity Recognition from Accelerometer Data
 Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees
 Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the SAT
 The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Algebra 2- Semester 2 Review
 Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
School Size and the Quality of Teaching and Learning
 School Size and the Quality of Teaching and Learning An Analysis of Relationships between School Size and Assessments of Factors Related to the Quality of Teaching and Learning in Primary Schools Undertaken
School Size and the Quality of Teaching and Learning An Analysis of Relationships between School Size and Assessments of Factors Related to the Quality of Teaching and Learning in Primary Schools Undertaken
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
An Empirical Comparison of Supervised Ensemble Learning Approaches
 An Empirical Comparison of Supervised Ensemble Learning Approaches Mohamed Bibimoune 1,2, Haytham Elghazel 1, Alex Aussem 1 1 Université de Lyon, CNRS Université Lyon 1, LIRIS UMR 5205, F-69622, France
An Empirical Comparison of Supervised Ensemble Learning Approaches Mohamed Bibimoune 1,2, Haytham Elghazel 1, Alex Aussem 1 1 Université de Lyon, CNRS Université Lyon 1, LIRIS UMR 5205, F-69622, France
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany
 Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Purdue Data Summit Communication of Big Data Analytics. New SAT Predictive Validity Case Study
 Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Word learning as Bayesian inference
 Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
Learning Distributed Linguistic Classes
 In: Proceedings of CoNLL-2000 and LLL-2000, pages -60, Lisbon, Portugal, 2000. Learning Distributed Linguistic Classes Stephan Raaijmakers Netherlands Organisation for Applied Scientific Research (TNO)
In: Proceedings of CoNLL-2000 and LLL-2000, pages -60, Lisbon, Portugal, 2000. Learning Distributed Linguistic Classes Stephan Raaijmakers Netherlands Organisation for Applied Scientific Research (TNO)
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
STT 231 Test 1. Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point.
 STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning
 Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Corpus Linguistics (L615)
") (L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
(L615) Basics of Markus Dickinson Department of, Indiana University Spring 2013 1 / 23 : the extent to which a sample includes the full range of variability in a population distinguishes corpora from archives
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur)
 (Some slides, pony-based examples from Blase Ur)") Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Statistical Analysis of Climate Change, Renewable Energies, and Sustainability An Independent Investigation for Introduction to Statistics
 5/22/2012 Statistical Analysis of Climate Change, Renewable Energies, and Sustainability An Independent Investigation for Introduction to Statistics College of Menominee Nation & University of Wisconsin
5/22/2012 Statistical Analysis of Climate Change, Renewable Energies, and Sustainability An Independent Investigation for Introduction to Statistics College of Menominee Nation & University of Wisconsin
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
An Introduction to the Minimalist Program
 An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
An Introduction to the Minimalist Program Luke Smith University of Arizona Summer 2016 Some findings of traditional syntax Human languages vary greatly, but digging deeper, they all have distinct commonalities:
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
ScienceDirect. A Framework for Clustering Cardiac Patient s Records Using Unsupervised Learning Techniques
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Content-based Image Retrieval Using Image Regions as Query Examples
 Content-based Image Retrieval Using Image Regions as Query Examples D. N. F. Awang Iskandar James A. Thom S. M. M. Tahaghoghi School of Computer Science and Information Technology, RMIT University Melbourne,
Content-based Image Retrieval Using Image Regions as Query Examples D. N. F. Awang Iskandar James A. Thom S. M. M. Tahaghoghi School of Computer Science and Information Technology, RMIT University Melbourne,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Conference Presentation
 Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Article A Novel, Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful: A Case Study for Modern Greek
 Article A Novel, Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful: A Case Study for Modern Greek Vasileios Athanasiou and Manolis Maragoudakis * Artificial
Article A Novel, Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful: A Case Study for Modern Greek Vasileios Athanasiou and Manolis Maragoudakis * Artificial
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Time series prediction
 Chapter 13 Time series prediction Amaury Lendasse, Timo Honkela, Federico Pouzols, Antti Sorjamaa, Yoan Miche, Qi Yu, Eric Severin, Mark van Heeswijk, Erkki Oja, Francesco Corona, Elia Liitiäinen, Zhanxing
Chapter 13 Time series prediction Amaury Lendasse, Timo Honkela, Federico Pouzols, Antti Sorjamaa, Yoan Miche, Qi Yu, Eric Severin, Mark van Heeswijk, Erkki Oja, Francesco Corona, Elia Liitiäinen, Zhanxing
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Unit 3: Lesson 1 Decimals as Equal Divisions
 Unit 3: Lesson 1 Strategy Problem: Each photograph in a series has different dimensions that follow a pattern. The 1 st photo has a length that is half its width and an area of 8 in². The 2 nd is a square
Unit 3: Lesson 1 Strategy Problem: Each photograph in a series has different dimensions that follow a pattern. The 1 st photo has a length that is half its width and an area of 8 in². The 2 nd is a square
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE. Pierre Foy
 TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
MYCIN. The MYCIN Task
 MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Version Space. Term 2012/2013 LSI - FIB. Javier Béjar cbea (LSI - FIB) Version Space Term 2012/ / 18
 Version Space Term 2012/ / 18") Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Interpreting ACER Test Results
 Interpreting ACER Test Results This document briefly explains the different reports provided by the online ACER Progressive Achievement Tests (PAT). More detailed information can be found in the relevant
Interpreting ACER Test Results This document briefly explains the different reports provided by the online ACER Progressive Achievement Tests (PAT). More detailed information can be found in the relevant
Multivariate k-nearest Neighbor Regression for Time Series data -
 Multivariate k-nearest Neighbor Regression for Time Series data - a novel Algorithm for Forecasting UK Electricity Demand ISF 2013, Seoul, Korea Fahad H. Al-Qahtani Dr. Sven F. Crone Management Science,
Multivariate k-nearest Neighbor Regression for Time Series data - a novel Algorithm for Forecasting UK Electricity Demand ISF 2013, Seoul, Korea Fahad H. Al-Qahtani Dr. Sven F. Crone Management Science,
Data Fusion Through Statistical Matching
 A research and education initiative at the MIT Sloan School of Management Data Fusion Through Statistical Matching Paper 185 Peter Van Der Puttan Joost N. Kok Amar Gupta January 2002 For more information,
A research and education initiative at the MIT Sloan School of Management Data Fusion Through Statistical Matching Paper 185 Peter Van Der Puttan Joost N. Kok Amar Gupta January 2002 For more information,
Detailed course syllabus
 Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Learning goal-oriented strategies in problem solving
 Learning goal-oriented strategies in problem solving Martin Možina, Timotej Lazar, Ivan Bratko Faculty of Computer and Information Science University of Ljubljana, Ljubljana, Slovenia Abstract The need
Learning goal-oriented strategies in problem solving Martin Možina, Timotej Lazar, Ivan Bratko Faculty of Computer and Information Science University of Ljubljana, Ljubljana, Slovenia Abstract The need
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
The lab is designed to remind you how to work with scientific data (including dealing with uncertainty) and to review experimental design.
 and to review experimental design.") Name: Partner(s): Lab #1 The Scientific Method Due 6/25 Objective The lab is designed to remind you how to work with scientific data (including dealing with uncertainty) and to review experimental design.
Name: Partner(s): Lab #1 The Scientific Method Due 6/25 Objective The lab is designed to remind you how to work with scientific data (including dealing with uncertainty) and to review experimental design.
Essentials of Ability Testing. Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology
 Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are