Question Classification in Question-Answering Systems Pujari Rajkumar
|
|
|
- Julius Watts
- 6 years ago
- Views:
Transcription
1 Question Classification in Question-Answering Systems Pujari Rajkumar
2 Question-Answering Question Answering(QA) is one of the most intuitive applications of Natural Language Processing(NLP) QA engines attempt to let you ask your question the way you'd normally ask it. More specific than short keyword queries Orange chicken What is orange chicken? How to make orange chicken? Inexperienced search users
3 Types of QA Systems Two types of QA Systems: 1. Open domain QA Systems Should be able to answer questions written in natural language similar to humans Eg: Google 2. Domain-Specific QA Systems Answer questions pertaining to a specific domain. Can give more detailed answers but restricted to a single domain Eg: Medical-domain QA systems (WebMD)
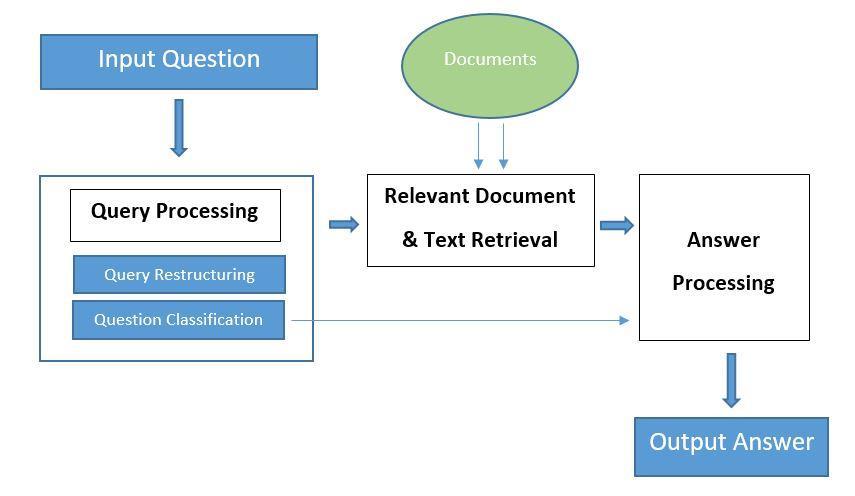
4 Typical QA Architecture
5 Stages of QA System Question Processing Consists of two phases, query reformation and question classification. Query reformation consists of forming suitable IR/knowledge-base query needed to extract relevant text from available documents/database. Question Classification(QC) consists of assigning the question to one or more of pre-defined classes of questions Passage Retrieval Relevant documents or relevant text from those documents, that helps in formation of answer, is retrieved from available documents. QC is also useful in this stage as question category determines the search strategy that needs to be employed to find the most suitable answer(s) Answer Processing Consists of constructing appropriate answer(s) from the text retrieved in previous stage. This stage also uses QC as it helps in choosing the candidate answer which is most probable to belong to the same class as the question
6 IBM Watson IBM Research undertook a challenge to build a computer system that could compete at the human champion level in real time on the American TV quiz show, Jeopardy Meeting the Jeopardy Challenge requires advancing and incorporating a variety of QA technologies including parsing, question classification, question decomposition, automatic source acquisition and evaluation, entity and relation detection, logical form generation, and knowledge representation and reasoning Category: General Science Clue: When hit by electrons, a phosphor gives off electromagnetic energy in this form. Answer: Light (or Photons)
7 Question Processing Consists of two phases: 1. Query Reformation 2. Question Classification Eg: Where is India gate? Restructured query: India gate location Question Category: location

8 An example
9 Example(contd.) Restructured Query: India Gate, Address Question Class: Address
10 Example(contd..) Restructured Query: India Gate, Coordinates Question Class: Coordinates
11 Another Example Answers can be of descriptive type as well
12 Question Taxonomy Also known as Question Ontology or Question Taxonomy Pre-defined set of classes that questions are classified into Tailored according to the dataset and task at hand IBM Watson has 11 pre-defined Question Classes: Definition, Fill in the blanks, Abbreviation, Category relation, Puzzle, Verb, Translation, Number, Bond, Multiple choice and Date. The classes were tailored towards Jeopardy! Challenge questions
13 Li and Roth s Taxonomy

14 Bloom s Taxonomy
15 Question Classification Systems Essentially two types of Question Classification Systems: 1. Rule-based Systems 1 2. Learning-based Systems Hybrid systems that combine both the approaches also exist Eg: IBM Watson
16 Rule-Based Systems A rule based approach consists of hand written rules that are run on the given question to assign it to a pre-defined category Such systems do not need any training data Eg: (Hull, 1999) Set of Question Categories: <Person>, <Place>, <Time>, <Money>, <Number>, <Quantity>, <Name>, <How>, <What>, <Unknown> Mapping from keyword to question category: who <Person>, where <Place>, what <What>, whose <Person>, when <Time>, which <What>, whom <Person>, how <How>, why <Unknown>
17 Drawbacks of Rule-based Systems Lack of thoroughness Contradictory rules Large set of rules to cater for corner cases A small rule set doesn t always do a thorough job and a good enough system often needs large rule set which is difficult to handle. Illustration: Rule: Whom - <person>? Works fine: Whom did the contestant call using the lifeline? Issue: Whom might also represent organizations Whom did Chicago bulls beat in 1992 Championship finals?
18 Learning-based Systems Systems based on machine-learning techniques Given labelled data and a set of features, the system learns how to classify the questions into pre-defined categories Learning based approaches proposed for QC are mainly supervised learning techniques Some of the popular supervised classifiers used are SVM, Maximum Entropy models and language modeling Semi-supervised classifiers such as co-learning have also been used effectively.
19 Support Vector Machine (SVM) SVM tries to find a hyper plane which has maximum margin between separating classes.
20 Maximum-Entropy Models Probability that a sample x i belongs to class y i is calculated as: f k is feature indicator function which is usually a binary-valued function defined for each feature. λ k is weight parameter which specifies the importance of f k (x i, y i ) in prediction and Z(x i λ) is the normalization function To learn parameters λ k, the model tries to maximize log-likelihood LL, defined as follows:
21 Language-Modeling Base idea of language modeling is that every word in the text is viewed as being generated by a language. Each question can be viewed as a document. Probability of a question belonging to language of a given class c can be computed as: p(x c) = p(w 1 c)p(w 2 c,w 1 ) p(w n c, w 1,, w n-1 ) As learning all the probabilities needs quite a large amount of data, unigram assumption can be made i.e., probability of each word is only dependent on the previous word. This reduces the equation to: p(x c) = p(w 1 c)p(w 2 c, w 1 ) p(w n c, w n-1 ) Most probable class can be determined using Bayes rule: c = argmax p(x c) p(c) where p(c) is a prior probability that can be assigned to the classes or can be taken as equal for all classes.
22 Semi-Supervised Learning Models Semi-supervised learning methods such as co-training have also been used to construct QC systems successfully. Co-training is a method of training two classifiers simultaneously. Given a set of labeled and unlabeled data, both classifiers are trained on labeled data and unlabeled data is marked by both the classifiers. Top results with high confidence from each classifier is fed to the other classifier for training. This process is repeated again.
23 Hybrid Approach Question Classification systems have also been constructed using hybrid approach which uses both rule-based and learning-based classifiers. IBM Watson is a very good example of such system. The detection in Watson is mostly rule based, which includes regular expressions patterns to detect the question class. On top of which, a logistic classifier is employed to get the best possible class. IBM Watson has 11 pre-defined Question Classes: Definition, Fill in the blanks, Abbreviation, Category relation, Puzzle, Verb, Translation, Number, Bond, Multiple choice and Date.
24 Features in Question Classification Pivotal part of using a classifier is construction of feature vector using optimal set of features. A simple feature vector can be constructed as: x = (w 1, w 2,, w n ) where w i is frequency of word i in question x. This would be a very sparse feature vector A simple modification can be done by dropping words with zero frequency from the vector Various other features that provide much deeper information about a question are used, in practice
25 Syntactic Features Syntactic features consist of structural aspects of the given question such as parts of speech(pos) tags and head words. Successful POS taggers exist which can give POS tags with high accuracy (~96%) such as Stanford NLP POS tagger. A head word is usually defined as most informative word in the sentence. Extracting head word of a sentence is a challenging problem and requires construction of parse tree of the question based on a set of grammar rules. Probabilistic Context Free Grammars(PCFGs) can be used for such purpose.
26 Head Word Example What year did the Titanic sink? Head Word: year
27 Semantic Features Semantic features are extracted based on meaning of the words in the question Eg: Hypernyms and named entities Hypernym is word which denotes a higher level semantic concept to the given word Eg: animal is a hypernym of cat Wordnet can be used to find hypernyms of given words Named entity is a well-known place, person or event, approximately a proper noun present in the question. Named entity recognition(ner) is a well researched area in NLP with lot of existing systems which achieve high accuracy
28 Evaluation Performance metric for any QC system would be accuracy of the system, i.e. Accuracy = Number of correctly classified questions Total number of input questions Standard IR metrics such as precision and recall also can be looked at for a given question category. Precision = Number of correctly classified questions as a given category Total number of input questions labeled as that category Recall = Number of correctly classified questions as a given category Total no. of questions actually belonging that category in input data


29 Questions?
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
ScienceDirect. Malayalam question answering system
 Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
Available online at www.sciencedirect.com ScienceDirect Procedia Technology 24 (2016 ) 1388 1392 International Conference on Emerging Trends in Engineering, Science and Technology (ICETEST - 2015) Malayalam
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Conversational Framework for Web Search and Recommendations
 Conversational Framework for Web Search and Recommendations Saurav Sahay and Ashwin Ram ssahay@cc.gatech.edu, ashwin@cc.gatech.edu College of Computing Georgia Institute of Technology Atlanta, GA Abstract.
Conversational Framework for Web Search and Recommendations Saurav Sahay and Ashwin Ram ssahay@cc.gatech.edu, ashwin@cc.gatech.edu College of Computing Georgia Institute of Technology Atlanta, GA Abstract.
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability
 Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability Shih-Bin Chen Dept. of Information and Computer Engineering, Chung-Yuan Christian University Chung-Li, Taiwan
Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability Shih-Bin Chen Dept. of Information and Computer Engineering, Chung-Yuan Christian University Chung-Li, Taiwan
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Language Independent Passage Retrieval for Question Answering
 Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Physics 270: Experimental Physics
 2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Leveraging Sentiment to Compute Word Similarity
 Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Leveraging Sentiment to Compute Word Similarity Balamurali A.R., Subhabrata Mukherjee, Akshat Malu and Pushpak Bhattacharyya Dept. of Computer Science and Engineering, IIT Bombay 6th International Global
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Loughton School s curriculum evening. 28 th February 2017
 Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Named Entity Recognition: A Survey for the Indian Languages
 Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
Named Entity Recognition: A Survey for the Indian Languages Padmaja Sharma Dept. of CSE Tezpur University Assam, India 784028 psharma@tezu.ernet.in Utpal Sharma Dept.of CSE Tezpur University Assam, India
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language
 Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Defragmenting Textual Data by Leveraging the Syntactic Structure of the English Language Nathaniel Hayes Department of Computer Science Simpson College 701 N. C. St. Indianola, IA, 50125 nate.hayes@my.simpson.edu
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Short Text Understanding Through Lexical-Semantic Analysis
 Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Short Text Understanding Through Lexical-Semantic Analysis Wen Hua #1, Zhongyuan Wang 2, Haixun Wang 3, Kai Zheng #4, Xiaofang Zhou #5 School of Information, Renmin University of China, Beijing, China
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
The Smart/Empire TIPSTER IR System
 The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The Smart/Empire TIPSTER IR System Chris Buckley, Janet Walz Sabir Research, Gaithersburg, MD chrisb,walz@sabir.com Claire Cardie, Scott Mardis, Mandar Mitra, David Pierce, Kiri Wagstaff Department of
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
arxiv:cmp-lg/ v1 22 Aug 1994
 arxiv:cmp-lg/94080v 22 Aug 994 DISTRIBUTIONAL CLUSTERING OF ENGLISH WORDS Fernando Pereira AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974 pereira@research.att.com Abstract We describe and
arxiv:cmp-lg/94080v 22 Aug 994 DISTRIBUTIONAL CLUSTERING OF ENGLISH WORDS Fernando Pereira AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974 pereira@research.att.com Abstract We describe and
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C
 Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
On document relevance and lexical cohesion between query terms
 Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Information Processing and Management 42 (2006) 1230 1247 www.elsevier.com/locate/infoproman On document relevance and lexical cohesion between query terms Olga Vechtomova a, *, Murat Karamuftuoglu b,
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures
 Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Modeling Attachment Decisions with a Probabilistic Parser: The Case of Head Final Structures Ulrike Baldewein (ulrike@coli.uni-sb.de) Computational Psycholinguistics, Saarland University D-66041 Saarbrücken,
Analysis: Evaluation: Knowledge: Comprehension: Synthesis: Application:
 In 1956, Benjamin Bloom headed a group of educational psychologists who developed a classification of levels of intellectual behavior important in learning. Bloom found that over 95 % of the test questions
In 1956, Benjamin Bloom headed a group of educational psychologists who developed a classification of levels of intellectual behavior important in learning. Bloom found that over 95 % of the test questions
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
The MEANING Multilingual Central Repository
 The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
The MEANING Multilingual Central Repository J. Atserias, L. Villarejo, G. Rigau, E. Agirre, J. Carroll, B. Magnini, P. Vossen January 27, 2004 http://www.lsi.upc.es/ nlp/meaning Jordi Atserias TALP Index
Vocabulary Usage and Intelligibility in Learner Language
 Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
Vocabulary Usage and Intelligibility in Learner Language Emi Izumi, 1 Kiyotaka Uchimoto 1 and Hitoshi Isahara 1 1. Introduction In verbal communication, the primary purpose of which is to convey and understand
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Latent Semantic Analysis
 Latent Semantic Analysis Adapted from: www.ics.uci.edu/~lopes/teaching/inf141w10/.../lsa_intro_ai_seminar.ppt (from Melanie Martin) and http://videolectures.net/slsfs05_hofmann_lsvm/ (from Thomas Hoffman)
Latent Semantic Analysis Adapted from: www.ics.uci.edu/~lopes/teaching/inf141w10/.../lsa_intro_ai_seminar.ppt (from Melanie Martin) and http://videolectures.net/slsfs05_hofmann_lsvm/ (from Thomas Hoffman)
Parsing of part-of-speech tagged Assamese Texts
 IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
IJCSI International Journal of Computer Science Issues, Vol. 6, No. 1, 2009 ISSN (Online): 1694-0784 ISSN (Print): 1694-0814 28 Parsing of part-of-speech tagged Assamese Texts Mirzanur Rahman 1, Sufal
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Automatic document classification of biological literature
 BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic
BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic
A Domain Ontology Development Environment Using a MRD and Text Corpus
 A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
A Domain Ontology Development Environment Using a MRD and Text Corpus Naomi Nakaya 1 and Masaki Kurematsu 2 and Takahira Yamaguchi 1 1 Faculty of Information, Shizuoka University 3-5-1 Johoku Hamamatsu
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Abstractions and the Brain
 Abstractions and the Brain Brian D. Josephson Department of Physics, University of Cambridge Cavendish Lab. Madingley Road Cambridge, UK. CB3 OHE bdj10@cam.ac.uk http://www.tcm.phy.cam.ac.uk/~bdj10 ABSTRACT
Abstractions and the Brain Brian D. Josephson Department of Physics, University of Cambridge Cavendish Lab. Madingley Road Cambridge, UK. CB3 OHE bdj10@cam.ac.uk http://www.tcm.phy.cam.ac.uk/~bdj10 ABSTRACT
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models
 Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
Clickthrough-Based Translation Models for Web Search: from Word Models to Phrase Models Jianfeng Gao Microsoft Research One Microsoft Way Redmond, WA 98052 USA jfgao@microsoft.com Xiaodong He Microsoft
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models
 Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models Jung-Tae Lee and Sang-Bum Kim and Young-In Song and Hae-Chang Rim Dept. of Computer &
Bridging Lexical Gaps between Queries and Questions on Large Online Q&A Collections with Compact Translation Models Jung-Tae Lee and Sang-Bum Kim and Young-In Song and Hae-Chang Rim Dept. of Computer &
Natural Language Processing: Interpretation, Reasoning and Machine Learning
 Natural Language Processing: Interpretation, Reasoning and Machine Learning Roberto Basili (Università di Roma, Tor Vergata) dblp: http://dblp.uni-trier.de/pers/hd/b/basili:roberto.html Google scholar:
Natural Language Processing: Interpretation, Reasoning and Machine Learning Roberto Basili (Università di Roma, Tor Vergata) dblp: http://dblp.uni-trier.de/pers/hd/b/basili:roberto.html Google scholar:
Cross-Lingual Text Categorization
 Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Mining Topic-level Opinion Influence in Microblog
 Mining Topic-level Opinion Influence in Microblog Daifeng Li Dept. of Computer Science and Technology Tsinghua University ldf3824@yahoo.com.cn Jie Tang Dept. of Computer Science and Technology Tsinghua
Mining Topic-level Opinion Influence in Microblog Daifeng Li Dept. of Computer Science and Technology Tsinghua University ldf3824@yahoo.com.cn Jie Tang Dept. of Computer Science and Technology Tsinghua
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
USER ADAPTATION IN E-LEARNING ENVIRONMENTS
 USER ADAPTATION IN E-LEARNING ENVIRONMENTS Paraskevi Tzouveli Image, Video and Multimedia Systems Laboratory School of Electrical and Computer Engineering National Technical University of Athens tpar@image.
USER ADAPTATION IN E-LEARNING ENVIRONMENTS Paraskevi Tzouveli Image, Video and Multimedia Systems Laboratory School of Electrical and Computer Engineering National Technical University of Athens tpar@image.