CS 510: Lecture 8. Deep Learning, Fairness, and Bias
|
|
|
- Arthur Stevens
- 6 years ago
- Views:
Transcription
1 CS 510: Lecture 8 Deep Learning, Fairness, and Bias
2 Next Week All Presentations, all the time Upload your presentation before class if using slides Sign up for a timeslot google doc, if you haven t already done so
3 Artificial Neural Networks: History Belief that it was necessary to model underlying brain architecture for AI In contrast to encoded symbolic knowledge (best represented by expert systems) Hebb - learning is altering strength of synaptic connections
4 Neural Networks Attempt to build a computation system based on the parallel architecture of brains Characteristics: Many simple processing elements Many connections Simple messages Adaptive interaction
5 Brains neurons of > 20 types, synapses, 1ms 10ms cycle time Signals are noisy spike trains of electrical potential Axonal arborization Synapse Axon from another cell Dendrite Axon Nucleus Synapses Cell body or Soma Chapter 20, Section 5 3
6 Benefits of NN User friendly (well, reasonably) Non-linear Noise tolerant Many applications Credit fraud/assignment Robotic Control
7 Neurons Inputs (either from outside or other neurons ) Weighted connections that correspond to synaptic efficiency Threshold values to weight the inputs Passed through activation function to determine output
8 Example Unit Binary input/output Rule 1 if w0*i0 + w1*i1 +wb > 0 0 if w0*i0 + w1*i1 +wb <= 0
9 Activation functions g(in i ) g(in i ) (a) in i (b) in i (a) is a step function or threshold function (b) is a sigmoid function 1/(1 + e x ) Changing the bias weight W 0,i moves the threshold location Note similarity to logistic regression... Chapter 20, Section 5 5
 W3")
10 -0.06 W1-2.5 W2 f(x) W3 1.4
11 f(x) x = =
12 How to Adapt? Perceptron Learning Rule change the weight by an amount proportional to the difference between the desired output and the actual output. As an equation: ΔWi = η * (D - Y)Ii, where D is desired output and Y is actual output Stop when converges
13 Limits of Perceptrons Minsky and Papert 1969 Fails on linearly inseparable instances XOR linearly separable - pattern space can be separated by single hyperplane
14 Perceptrons vs Decision Trees

15 Multilayer Perceptrons (MLP)
16 Back Propagation Start with a set of known examples (supervised approach) Assign random initial weights Run examples through and calculate the mean-squared error Propagate the error by making small changes to the weights at each level Use chain rule to calculate the gradient efficiently Lather, rinse, repeat

17 Gradient Descent Algorithm Have some function Want Outline: Start with some Keep changing to reduce until we hopefully end up at a minimum
 If J is an error function we want to move downhill - opposite to the")
18 The gradient of J ( J) at a point can be thought of as a vector indicating which way is uphill J(θ 0,θ 1 ) If J is an error function we want to move downhill - opposite to the gradient
19 Gradient descent algorithm Have function J Want to produce vectors s.t. J(θ1)>J(θ2)>... start w/ θ0 θi+1 = θi - ɑi J(θi) ɑ(alpha) is the learning rate
20 Stochastic Gradient Descent Update J every time you look at a training example
21 Some non-linear activation functions
22 Most common activation function
23 A dataset Fields class etc
24 Training the neural network Fields class etc
25 Training data Fields class etc Initialise with random weights
26 Training data Fields class etc Present a training pattern
27 Training data Fields class etc 1.4 Feed it through to get output
28 Training data Fields class etc 1.4 Compare with target output error 0.8
29 Training data Fields class etc 1.4 Adjust weights based on error error 0.8
30 Training data Fields class etc Present a training pattern
31 Training data Fields class etc 6.4 Feed it through to get output
32 Training data Fields class etc 6.4 Compare with target output error -0.1
33 Training data Fields class etc 6.4 Adjust weights based on error error -0.1


34 Training data Fields class etc 6.4 And so on error -0.1 Repeat this thousands, maybe millions of times each time taking a random training instance, and making slight weight adjustments Algorithms for weight adjustment are designed to make changes that will reduce the error
35 The decision boundary perspective Initial random weights
36 The decision boundary perspective Present a training instance / adjust the weights
37 The decision boundary perspective Present a training instance / adjust the weights
38 The decision boundary perspective Present a training instance / adjust the weights
39 The decision boundary perspective Present a training instance / adjust the weights
40 The decision boundary perspective Eventually.


41 The point I am trying to make weight-learning algorithms for NNs are dumb they work by making thousands and thousands of tiny adjustments, each making the network do better at the most recent pattern, but perhaps a little worse on many others but, by dumb luck, eventually this tends to be good enough to learn effective classifiers for many real applications
42 Some other points Detail of a standard NN weight learning algorithm later If f(x) is non-linear, a network with 1 hidden layer can, in theory, learn perfectly any classification problem. A set of weights exists that can produce the targets from the inputs. The problem is finding them.
43 Some other by the way points If f(x) is linear, the NN can only draw straight decision boundaries (even if there are many layers of units)
44 Some other by the way points NNs use nonlinear f(x) so they can draw complex boundaries, but keep the data unchanged
45 Some other by the way points NNs use nonlinear f(x) so they can draw complex boundaries, but keep the data unchanged SVMs only draw straight lines, but they transform the data first in a way that makes that OK
46 Neural network vocabulary Neuron = logistic regression or similar function Input layer = input training/test vector Bias unit = intercept term/always on feature Activation = response Activation function is a logistic (or similar sigmoid nonlinearity) Backpropagation = running stochastic gradient descent across a multilayer network Weight decay - regularization or Bayesian prior
47 Deep Learning Most current machine learning works well because of human-designed representations and input features Machine learning becomes just optimizing weights to best make a final prediction Representation learning attempts to automatically learn good features or representations Deep learning algorithms attempt to learn multiple levels of representation of increasing complexity/abstraction
48 Deep Architecture
49 Deep Learning Overview Train networks with many layers (vs. shallow nets with just a couple of layers) Multiple layers work to build an improved feature space First layer learns 1st order features (e.g. edges ) 2nd layer learns higher order features (combinations of first layer features, combinations of edges, etc.) In current models layers often learn in an unsupervised mode and discover general features of the input space serving multiple tasks related to the unsupervised instances (image recognition, etc.) Then final layer features are fed into supervised layer(s) And entire network is often subsequently tuned using supervised training of the entire net, using the initial weightings learned in the unsupervised phase Could also do fully supervised versions, etc. (early BP attempts)
50 Why Deep Learning?
51 Learning Representations Handcrafting features is time-consuming incomplete domain/... The features are often both over-specified and The work has to be done again for each task/ We must move beyond handcrafted features and simple ML Humans develop representations for learning and reasoning Our computers should do the same
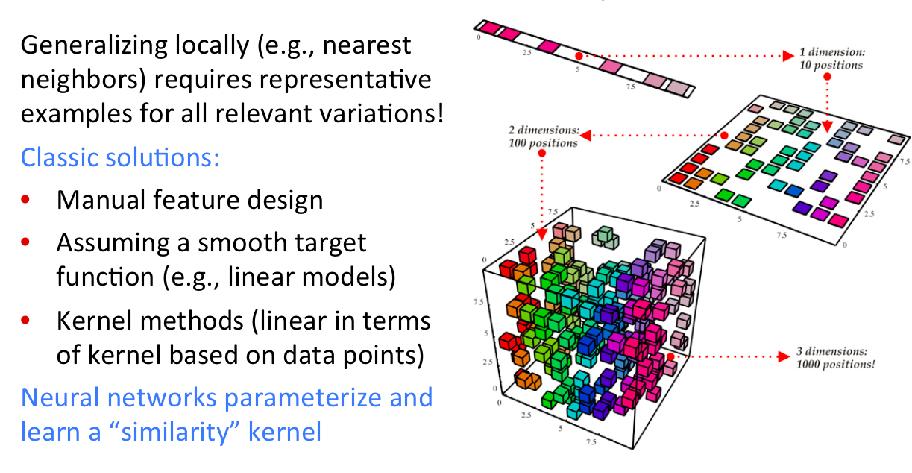
52 The Curse of Dimensionality
53 Unsupervised Feature and Weight Learning Today, most practical, good NLP& ML methods require labeled training data (i.e., supervised learning) But almost all data is unlabeled Most information must be acquired unsupervised Fortunately, a good model of observed data can really help you learn classification decisions

54 Learning Multiple Levels of Representation




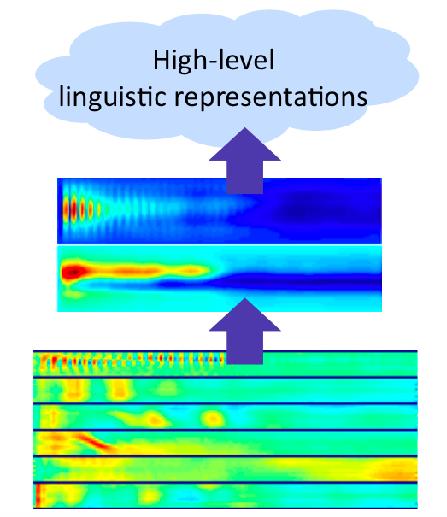
55 Successive Layers Learn Deeper Representations object models object parts (combination of edges) edges pixels
56 Impressive Results Especially on Large Datasets Object Recognition - better than anything out there Speech Recognition (google voice search) Many other perceptual tasks in vision and NLP
57 Why now? Bigger Data - deep learning works best Better Hardware - multicore CPUs and GPUs Better Algorithms - autoencoders, deep belief networks, etc Let us train multiple inner layers well
58 Breakthrough: Unsupervised Pre-training
59 Difficulties with Supervised Networks Early layers of MLP do not get trained well Diffusion of Gradient error attenuates as it propagates to earlier layers Leads to very slow training Exacerbated since top couple layers can usually learn any task "pretty well" and thus the error to earlier layers drops quickly as the top layers "mostly" solve the task lower layers never get the opportunity to use their capacity to improve results, they just do a random feature map Need a way for early layers to do effective work Often not enough labeled data available while lots of unlabeled data Can we use unsupervised/semi-supervised approaches to take advantage of the unlabeled data Deep networks tend to have more local minima problems than shallow networks during supervised training
60 Semi-supervised Learning
61 Semi-supervised Learning
62 Training Deep Networks Build a feature space Note that this is what we do with SVM kernels, or trained hidden layers in BP, etc., but now we will build the feature space using deep architectures Unsupervised training between layers can decompose the problem into distributed subproblems (with higher levels of abstraction) to be further decomposed at subsequent layers
63 Greedy Layer-wise Training Train first layer using your data without the labels (unsupervised) Since there are no targets at this level, labels don't help. Could also use the more abundant unlabeled data which is not part of the training set (i.e. self-taught learning). Freeze the first layer parameters and start training the second layer using the output of the first layer as the unsupervised input to the second layer Repeat this for as many layers as desired This builds our set of robust features Use the outputs of the final layer as inputs to a supervised layer/model and train the last supervised layer(s) (leave early weights frozen) Unfreeze all weights and fine tune the full network by training with a supervised approach, given the pre-processed weight settings
64 Greedy Layer-wise Training Greedy layer-wise training avoids many of the problems of trying to train a deep net in a supervised fashion Each layer gets full learning focus in its turn since it is the only current "top" layer Can take advantage of the unlabeled data When you finally tune the entire network with supervised training the network weights have already been adjusted so that you are in a good error basin and just need fine tuning. This helps with problems of Ineffective early layer learning Deep network local minima We will discuss the two most common approaches Stacked Auto-Encoders Deep Belief Networks
65 The new way to train multi-layer NNs Train this layer first
66 The new way to train multi-layer NNs Train this layer first then this layer
67 The new way to train multi-layer NNs Train this layer first then this layer then this layer
68 The new way to train multi-layer NNs Train this layer first then this layer then this layer then this layer
69 The new way to train multi-layer NNs Train this layer first then this layer then this layer then this layer finally this layer
 layers is trained to be an")

70 The new way to train multi-layer NNs EACH of the (non-output) layers is trained to be an auto-encoder Basically, it is forced to learn good features that describe what comes from the previous layer
71 an auto-encoder is trained, with an absolutely standard weight-adjustment algorithm to reproduce the input
 fewer units than the inputs, this forces the hidden layer units to become good feature")
72 an auto-encoder is trained, with an absolutely standard weight-adjustment algorithm to reproduce the input By making this happen with (many) fewer units than the inputs, this forces the hidden layer units to become good feature detectors
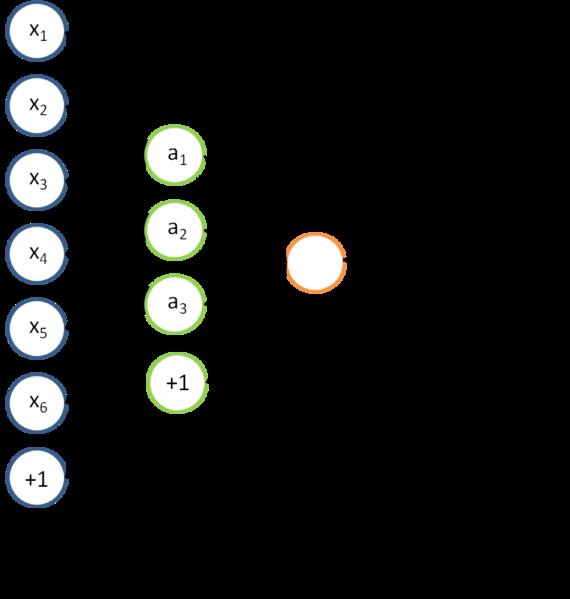
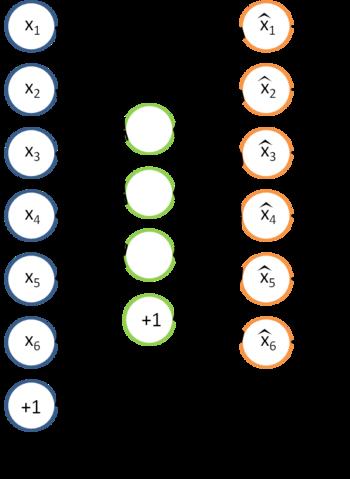
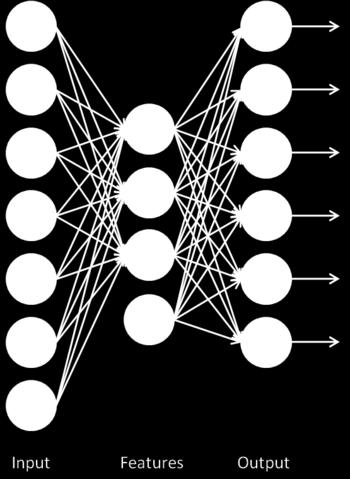
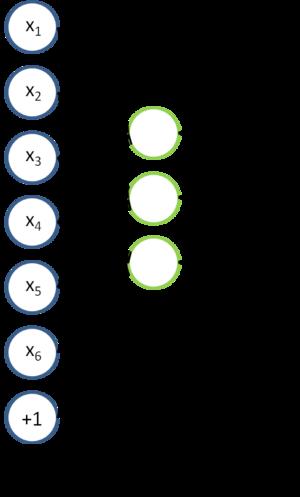
73 One Auto-encoder 73


74 Stacked Auto-encoders Stack sparse auto-encoders on top of each other, drop decode layer each time 74




75 Stacked auto-encoders Do supervised training on last layer Then do supervised training on whole network to fine tune the weights 75
76 Manifold Learning Hypothesis 76
77 Caveats Prevent the layers from just learning the identity (learn Features instead) Undercomplete - middle layer smaller than input Sparsity - penalize hidden unit activations Use regularization to keep most nodes at or near 0 Denoising - Stochastically corrupt training instance, but train encoder to decode uncorrupted instance Contractive - force encoder to have small derivatives (stay on manifold) 77
78 Fairness and Learning Going to show video of Aylin Link on course website to her talk (may be easier for online students if there is feedback). 78
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Artificial Neural Networks
 Artificial Neural Networks Andres Chavez Math 382/L T/Th 2:00-3:40 April 13, 2010 Chavez2 Abstract The main interest of this paper is Artificial Neural Networks (ANNs). A brief history of the development
Artificial Neural Networks Andres Chavez Math 382/L T/Th 2:00-3:40 April 13, 2010 Chavez2 Abstract The main interest of this paper is Artificial Neural Networks (ANNs). A brief history of the development
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Time series prediction
 Chapter 13 Time series prediction Amaury Lendasse, Timo Honkela, Federico Pouzols, Antti Sorjamaa, Yoan Miche, Qi Yu, Eric Severin, Mark van Heeswijk, Erkki Oja, Francesco Corona, Elia Liitiäinen, Zhanxing
Chapter 13 Time series prediction Amaury Lendasse, Timo Honkela, Federico Pouzols, Antti Sorjamaa, Yoan Miche, Qi Yu, Eric Severin, Mark van Heeswijk, Erkki Oja, Francesco Corona, Elia Liitiäinen, Zhanxing
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
CS 1103 Computer Science I Honors. Fall Instructor Muller. Syllabus
 CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Distributed Learning of Multilingual DNN Feature Extractors using GPUs
 Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Distributed Learning of Multilingual DNN Feature Extractors using GPUs Yajie Miao, Hao Zhang, Florian Metze Language Technologies Institute, School of Computer Science, Carnegie Mellon University Pittsburgh,
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
*** * * * COUNCIL * * CONSEIL OFEUROPE * * * DE L'EUROPE. Proceedings of the 9th Symposium on Legal Data Processing in Europe
 *** * * * COUNCIL * * CONSEIL OFEUROPE * * * DE L'EUROPE Proceedings of the 9th Symposium on Legal Data Processing in Europe Bonn, 10-12 October 1989 Systems based on artificial intelligence in the legal
*** * * * COUNCIL * * CONSEIL OFEUROPE * * * DE L'EUROPE Proceedings of the 9th Symposium on Legal Data Processing in Europe Bonn, 10-12 October 1989 Systems based on artificial intelligence in the legal
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Knowledge-Based - Systems
 Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Natural Language Processing: Interpretation, Reasoning and Machine Learning
 Natural Language Processing: Interpretation, Reasoning and Machine Learning Roberto Basili (Università di Roma, Tor Vergata) dblp: http://dblp.uni-trier.de/pers/hd/b/basili:roberto.html Google scholar:
Natural Language Processing: Interpretation, Reasoning and Machine Learning Roberto Basili (Università di Roma, Tor Vergata) dblp: http://dblp.uni-trier.de/pers/hd/b/basili:roberto.html Google scholar:
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE
 2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
2014 IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP) DIRECT ADAPTATION OF HYBRID DNN/HMM MODEL FOR FAST SPEAKER ADAPTATION IN LVCSR BASED ON SPEAKER CODE Shaofei Xue 1
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
A Deep Bag-of-Features Model for Music Auto-Tagging
 1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
1 A Deep Bag-of-Features Model for Music Auto-Tagging Juhan Nam, Member, IEEE, Jorge Herrera, and Kyogu Lee, Senior Member, IEEE latter is often referred to as music annotation and retrieval, or simply
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS
 DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS Jonas Gehring 1 Quoc Bao Nguyen 1 Florian Metze 2 Alex Waibel 1,2 1 Interactive Systems Lab, Karlsruhe Institute of Technology;
DNN ACOUSTIC MODELING WITH MODULAR MULTI-LINGUAL FEATURE EXTRACTION NETWORKS Jonas Gehring 1 Quoc Bao Nguyen 1 Florian Metze 2 Alex Waibel 1,2 1 Interactive Systems Lab, Karlsruhe Institute of Technology;
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO. Aleksandr Diment, Tuomas Virtanen
 TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
TRANSFER LEARNING OF WEAKLY LABELLED AUDIO Aleksandr Diment, Tuomas Virtanen Tampere University of Technology Laboratory of Signal Processing Korkeakoulunkatu 1, 33720, Tampere, Finland firstname.lastname@tut.fi
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
I-COMPETERE: Using Applied Intelligence in search of competency gaps in software project managers.
 Information Systems Frontiers manuscript No. (will be inserted by the editor) I-COMPETERE: Using Applied Intelligence in search of competency gaps in software project managers. Ricardo Colomo-Palacios
Information Systems Frontiers manuscript No. (will be inserted by the editor) I-COMPETERE: Using Applied Intelligence in search of competency gaps in software project managers. Ricardo Colomo-Palacios
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Mathematics process categories
 Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts