Breakout Group Reinforcement Learning
|
|
|
- Karen Hampton
- 6 years ago
- Views:
Transcription
1 Breakout Group Reinforcement Learning FABIAN RUEHLE (UNIVERSITY OF OXFORD) String_Data 2017, Boston 12/01/2017
2 Outline Theoretical introduction (30 minutes) Discussion of code (30 minutes) Solve version of grid world with SARSA Discussion of RL and its applications to String Theory (30 minutes)
3 How to teach a machine Supervised Learning (SL): provide a set of training tuples [(in 0, out 0 ), (in 1, out 1 ),...,(in n, out n )] after training, machine predicts Unsupervised Learning (UL): out i from in i only provide set training input set [in 0, in 1,...,in n ] give task to machine (e.g. cluster input) without telling it how to do this exactly After training, the machine will perform self-learned action on Reinforcement Learning (RL): in i in between SL and UL Machine acts autonomously, but actions are reinforced / punished


4 Theoretical introduction
5 Reinforcement Learning - Vocabulary Basic textbooks/literature [Barton, Sutton 98 17] The thing that learns is called agent or worker The thing that is explored is called environment The elements of the environment are called states or observations The things that take you from one state to another are called actions The thing that tells you how to select the next action is called policy Actions are executed sequentially in a sequence called (time) steps The reinforcement the agent experiences is called reward The accumulated reward is called return In RL, an agent performs actions in an environment with the goal to maximize its long-term return
6 Reinforcement Learning - Details We focus on discrete state and action spaces State space S = {states in environment} Action space total: A = {actions to transition between states} s 2 S for : A(s) ={possible actions in state s} Policy (s) =a, a2 A(s) : Select next action for given state : S 7! A Reward R(s, a) 2 R: Reward for taking action a in state s R : S A 7! R
7 Reinforcement Learning - Details Return: The accumulated reward from current step G t = 1X k=0 k r t+k+1, 2 (0, 1] State value function v (s): Expected return for s with policy : v (s) =E[ G t s = s t ] Action value function q(s, a) : Expected return for performing action a in state s with policy : q (s, a) =E[ G t s = s t,a= a t ] Prediction problem: Given, predict v (s) or q (s, a) Control problem: Find optimal policy maximizes v (s) or q (s, a) that t
8 Reinforcement Learning - Details Commonly used policies: greedy: Choose the action that maximizes the action value function: 0 (s) = argmax q(s, a) " - greedy: Explore different possibilities 0 Choose greedy in (1 ") cases (s) = Choose random action in cases We take "-greedy policy improvement On-policy: Update policy you are following (e.g. always "- greedy) Off-policy: Use different policy for choosing next action and updating q(s t,a t ) a t+1
9 Reinforcement Learning - SARSA Solving the control problem: v(s t )= [G t v(s t )] =0 v(s t ) : Learning rate ( means no update to ) One step approximation: G t = r + v(s t+1 ) Similar for action value function: q(s t,a t )= [G t q(s t,a t )] = [r + q(s t+1,a t+1 ) q(s t,a t ))] Update depends on tuple (s t,a t,r,s t+1,a t+1 ) a t+1 s t+1 is currently best known action for state Note: SARSA is on-policy
10 Reinforcement Learning - Q-Learning Very similar to SARSA Difference in update: SARSA: q(s t,a t )= [r + q(s t+1,a t+1 ) q(s t,a t )] Q_Learning: q(s t,a t )= [r + max a 0 q(s t+1,a 0 ) q(s t,a t )] Note: This means that Q-Learning is off-policy SARSA is found to perform better Q-Learning is proven to converge to solution Combine with (deep NNs): Deep Q-Learning
 Pitfall Exit Wall")
11 Example - Gridworld Worker ( Explorer ) Pitfall Exit Wall
12 Example - Gridworld We will look at a version of grid world: Gridworld is a grid-like maze with walls, pitfalls, and an exit Each state is a point on the grid of the maze The actions are A = {up, down, left, right} Goal: Find the exit (strongly rewarded) Each step is punished mildly (solve maze quickly) Pitfalls should be avoided (strongly punished) Running into a wall does not change the state
13 Gridworld vs String Landscape Walls = Boundaries of landscape (negative number of branes) Empty square = Consistent point in the landscape which does not correspond to our Universe Pitfalls = Mathematically / Physically inconsistent states (anomalies, tadpoles, ) Exit = Standard Model of Particle Physics
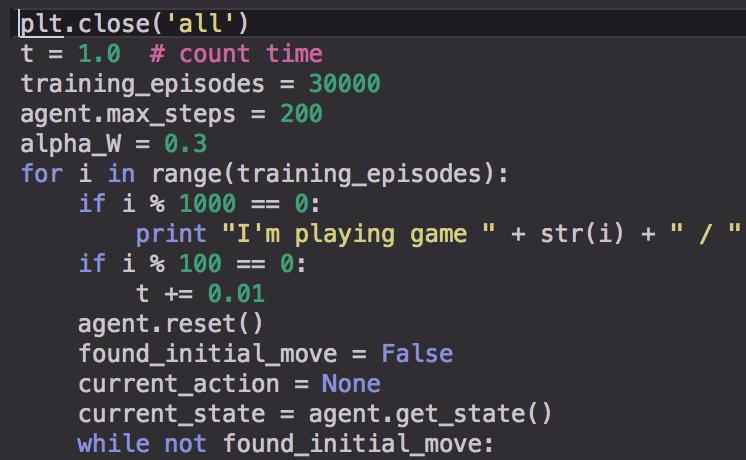
14 Coding


15 Discussion
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design
 Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses
 Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
CAFE ESSENTIAL ELEMENTS O S E P P C E A. 1 Framework 2 CAFE Menu. 3 Classroom Design 4 Materials 5 Record Keeping
 CAFE RE P SU C 3 Classroom Design 4 Materials 5 Record Keeping P H ND 1 Framework 2 CAFE Menu R E P 6 Assessment 7 Choice 8 Whole-Group Instruction 9 Small-Group Instruction 10 One-on-one Instruction 11
CAFE RE P SU C 3 Classroom Design 4 Materials 5 Record Keeping P H ND 1 Framework 2 CAFE Menu R E P 6 Assessment 7 Choice 8 Whole-Group Instruction 9 Small-Group Instruction 10 One-on-one Instruction 11
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Self Study Report Computer Science
 Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
PLCs - From Understanding to Action Handouts
 PLCs - From Understanding to Action Handouts PLC s From Understanding to Action! Gavin Grift That s Me! I have to have coffee as soon as I wake. I was the naughty kid at school. I have been in education
PLCs - From Understanding to Action Handouts PLC s From Understanding to Action! Gavin Grift That s Me! I have to have coffee as soon as I wake. I was the naughty kid at school. I have been in education
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Level 1 Mathematics and Statistics, 2015
 91037 910370 1SUPERVISOR S Level 1 Mathematics and Statistics, 2015 91037 Demonstrate understanding of chance and data 9.30 a.m. Monday 9 November 2015 Credits: Four Achievement Achievement with Merit
91037 910370 1SUPERVISOR S Level 1 Mathematics and Statistics, 2015 91037 Demonstrate understanding of chance and data 9.30 a.m. Monday 9 November 2015 Credits: Four Achievement Achievement with Merit
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Surprise-Based Learning for Autonomous Systems
 Surprise-Based Learning for Autonomous Systems Nadeesha Ranasinghe and Wei-Min Shen ABSTRACT Dealing with unexpected situations is a key challenge faced by autonomous robots. This paper describes a promising
Surprise-Based Learning for Autonomous Systems Nadeesha Ranasinghe and Wei-Min Shen ABSTRACT Dealing with unexpected situations is a key challenge faced by autonomous robots. This paper describes a promising
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Tutor s Guide TARGET AUDIENCES. "Qualitative survey methods applied to natural resource management"
 Tutor s Guide "Qualitative survey methods applied to natural resource management" This document is the complement to the student's guide, "Welcome to the training". It provides you, as the teacher, trainer,
Tutor s Guide "Qualitative survey methods applied to natural resource management" This document is the complement to the student's guide, "Welcome to the training". It provides you, as the teacher, trainer,
Firms and Markets Saturdays Summer I 2014
 PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING. Calendar Description Units: 1.
 University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
DOCTOR OF PHILOSOPHY HANDBOOK
 University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Certified Six Sigma - Black Belt VS-1104
 Certified Six Sigma - Black Belt VS-1104 Certified Six Sigma - Black Belt Professional Certified Six Sigma - Black Belt Professional Certification Code VS-1104 Vskills certification for Six Sigma - Black
Certified Six Sigma - Black Belt VS-1104 Certified Six Sigma - Black Belt Professional Certified Six Sigma - Black Belt Professional Certification Code VS-1104 Vskills certification for Six Sigma - Black
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Carter M. Mast. Participants: Peter Mackenzie-Helnwein, Pedro Arduino, and Greg Miller. 6 th MPM Workshop Albuquerque, New Mexico August 9-10, 2010
 Representing Arbitrary Bounding Surfaces in the Material Point Method Carter M. Mast 6 th MPM Workshop Albuquerque, New Mexico August 9-10, 2010 Participants: Peter Mackenzie-Helnwein, Pedro Arduino, and
Representing Arbitrary Bounding Surfaces in the Material Point Method Carter M. Mast 6 th MPM Workshop Albuquerque, New Mexico August 9-10, 2010 Participants: Peter Mackenzie-Helnwein, Pedro Arduino, and
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
What is Research? A Reconstruction from 15 Snapshots. Charlie Van Loan
 What is Research? A Reconstruction from 15 Snapshots Charlie Van Loan Warm-Up Question How do you evaluate the quality of a PhD Dissertation? The Skyline Factor It depends on the eye of the beholder. The
What is Research? A Reconstruction from 15 Snapshots Charlie Van Loan Warm-Up Question How do you evaluate the quality of a PhD Dissertation? The Skyline Factor It depends on the eye of the beholder. The
Week 01. MS&E 273: Technology Venture Formation
 Week 01 MS&E 273: Technology Venture Formation Key Facts School of Engineering, Stanford University Fall 2016, 3-4 units Tuesdays, 4:30 7:20 PM, Thornton 110 2 Teaching team MIKE LYONS ADJUNCT PROFESSOR
Week 01 MS&E 273: Technology Venture Formation Key Facts School of Engineering, Stanford University Fall 2016, 3-4 units Tuesdays, 4:30 7:20 PM, Thornton 110 2 Teaching team MIKE LYONS ADJUNCT PROFESSOR
EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS
 EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS by Robert Smith Submitted in partial fulfillment of the requirements for the degree of Master of
EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS by Robert Smith Submitted in partial fulfillment of the requirements for the degree of Master of
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
Welcome to ACT Brain Boot Camp
 Welcome to ACT Brain Boot Camp 9:30 am - 9:45 am Basics (in every room) 9:45 am - 10:15 am Breakout Session #1 ACT Math: Adame ACT Science: Moreno ACT Reading: Campbell ACT English: Lee 10:20 am - 10:50
Welcome to ACT Brain Boot Camp 9:30 am - 9:45 am Basics (in every room) 9:45 am - 10:15 am Breakout Session #1 ACT Math: Adame ACT Science: Moreno ACT Reading: Campbell ACT English: Lee 10:20 am - 10:50
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR
 COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR ROLAND HAUSSER Institut für Deutsche Philologie Ludwig-Maximilians Universität München München, West Germany 1. CHOICE OF A PRIMITIVE OPERATION The
COMPUTATIONAL COMPLEXITY OF LEFT-ASSOCIATIVE GRAMMAR ROLAND HAUSSER Institut für Deutsche Philologie Ludwig-Maximilians Universität München München, West Germany 1. CHOICE OF A PRIMITIVE OPERATION The
Kindergarten Lessons for Unit 7: On The Move Me on the Map By Joan Sweeney
 Kindergarten Lessons for Unit 7: On The Move Me on the Map By Joan Sweeney Aligned with the Common Core State Standards in Reading, Speaking & Listening, and Language Written & Prepared for: Baltimore
Kindergarten Lessons for Unit 7: On The Move Me on the Map By Joan Sweeney Aligned with the Common Core State Standards in Reading, Speaking & Listening, and Language Written & Prepared for: Baltimore
Prince2 Foundation and Practitioner Training Exam Preparation
 Prince2 Foundation and Practitioner Training Exam Preparation Prince2 is the UK Government Best Practice standard and is widely recognized and used for effective Project management methodology and tools.
Prince2 Foundation and Practitioner Training Exam Preparation Prince2 is the UK Government Best Practice standard and is widely recognized and used for effective Project management methodology and tools.
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Pitching Accounts & Advertising Sales ADV /PR
 Pitching Accounts & Advertising Sales ADV 378 05816/PR 378 06233 Fall 2011 UTC 3.110 Fridays 9 am to 12 pm Instructor: Office: Office Hours: TA & Off. Hours: Fran Harris CMA A7.154B By appointment, Thursdays
Pitching Accounts & Advertising Sales ADV 378 05816/PR 378 06233 Fall 2011 UTC 3.110 Fridays 9 am to 12 pm Instructor: Office: Office Hours: TA & Off. Hours: Fran Harris CMA A7.154B By appointment, Thursdays
Hentai High School A Game Guide
 Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Learning to Think Mathematically with the Rekenrek Supplemental Activities
 Learning to Think Mathematically with the Rekenrek Supplemental Activities Jeffrey Frykholm, Ph.D. Learning to Think Mathematically with the Rekenrek, Supplemental Activities A complementary resource to
Learning to Think Mathematically with the Rekenrek Supplemental Activities Jeffrey Frykholm, Ph.D. Learning to Think Mathematically with the Rekenrek, Supplemental Activities A complementary resource to
Validation Requirements and Error Codes for Submitting Common Completion Metrics
 Validation Requirements and s for Submitting Common Completion s March 2015 Overview To ensure accurate reporting and quality data, Complete College America is committed to helping data submitters ensure
Validation Requirements and s for Submitting Common Completion s March 2015 Overview To ensure accurate reporting and quality data, Complete College America is committed to helping data submitters ensure
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
A General Class of Noncontext Free Grammars Generating Context Free Languages
 INFORMATION AND CONTROL 43, 187-194 (1979) A General Class of Noncontext Free Grammars Generating Context Free Languages SARWAN K. AGGARWAL Boeing Wichita Company, Wichita, Kansas 67210 AND JAMES A. HEINEN
INFORMATION AND CONTROL 43, 187-194 (1979) A General Class of Noncontext Free Grammars Generating Context Free Languages SARWAN K. AGGARWAL Boeing Wichita Company, Wichita, Kansas 67210 AND JAMES A. HEINEN
Millersville University Testing Library Complete Archive (2016)
") Assessment Test Full Test Name Edition Type Personality AAC -White Adolescent Apperception Cards - White Version 1993 Kit Behavioral ABAS-II Adaptive Behavior Assessment System Parent Form Teacher Form
Assessment Test Full Test Name Edition Type Personality AAC -White Adolescent Apperception Cards - White Version 1993 Kit Behavioral ABAS-II Adaptive Behavior Assessment System Parent Form Teacher Form
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
Holy Family Catholic Primary School SPELLING POLICY
 Holy Family Catholic Primary School SPELLING POLICY 1. The aim of the spelling policy at Holy Family Catholic Primary School is to ensure that the children are encouraged to develop spelling accuracy in
Holy Family Catholic Primary School SPELLING POLICY 1. The aim of the spelling policy at Holy Family Catholic Primary School is to ensure that the children are encouraged to develop spelling accuracy in
Improving Conceptual Understanding of Physics with Technology
 INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
GERM 3040 GERMAN GRAMMAR AND COMPOSITION SPRING 2017
 GERM 3040 GERMAN GRAMMAR AND COMPOSITION SPRING 2017 Instructor: Dr. Claudia Schwabe Class hours: TR 9:00-10:15 p.m. claudia.schwabe@usu.edu Class room: Old Main 301 Office: Old Main 002D Office hours:
GERM 3040 GERMAN GRAMMAR AND COMPOSITION SPRING 2017 Instructor: Dr. Claudia Schwabe Class hours: TR 9:00-10:15 p.m. claudia.schwabe@usu.edu Class room: Old Main 301 Office: Old Main 002D Office hours:
Backwards Numbers: A Study of Place Value. Catherine Perez
 Backwards Numbers: A Study of Place Value Catherine Perez Introduction I was reaching for my daily math sheet that my school has elected to use and in big bold letters in a box it said: TO ADD NUMBERS
Backwards Numbers: A Study of Place Value Catherine Perez Introduction I was reaching for my daily math sheet that my school has elected to use and in big bold letters in a box it said: TO ADD NUMBERS
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
CS 101 Computer Science I Fall Instructor Muller. Syllabus
 CS 101 Computer Science I Fall 2013 Instructor Muller Syllabus Welcome to CS101. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts of
CS 101 Computer Science I Fall 2013 Instructor Muller Syllabus Welcome to CS101. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts of
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Coaching Others for Top Performance 16 Hour Workshop
 Coaching Others for Top Performance 16 Hour Workshop Content & Outcomes The Coaching Others for Top Performance workshop explores The Principles and Qualities of Genuine Leadership and focuses on developing
Coaching Others for Top Performance 16 Hour Workshop Content & Outcomes The Coaching Others for Top Performance workshop explores The Principles and Qualities of Genuine Leadership and focuses on developing
An Introduction to Simulation Optimization
 An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Executive Guide to Simulation for Health
 Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
Executive Guide to Simulation for Health Simulation is used by Healthcare and Human Service organizations across the World to improve their systems of care and reduce costs. Simulation offers evidence
ESL Curriculum and Assessment
 ESL Curriculum and Assessment Terms Syllabus Content of a course How it is organized How it will be tested Curriculum Broader term, process Describes what will be taught, in what order will it be taught,
ESL Curriculum and Assessment Terms Syllabus Content of a course How it is organized How it will be tested Curriculum Broader term, process Describes what will be taught, in what order will it be taught,
A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization
 A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization Stefan Henß TU Darmstadt, Germany stefan.henss@gmail.com Margot Mieskes h da Darmstadt & AIPHES Germany margot.mieskes@h-da.de
A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization Stefan Henß TU Darmstadt, Germany stefan.henss@gmail.com Margot Mieskes h da Darmstadt & AIPHES Germany margot.mieskes@h-da.de
IMPACT INSTITUTE BEHAVIOR MANAGEMENT. Krissy Matthaei Gina Schutt
 IMPACT INSTITUTE BEHAVIOR MANAGEMENT Krissy Matthaei kmatthaei@usd259.net Gina Schutt rschutt@usd259.net Summer 2015 Voice Level 0 while facilitator or others are speaking Voice Level 1 for partner work
IMPACT INSTITUTE BEHAVIOR MANAGEMENT Krissy Matthaei kmatthaei@usd259.net Gina Schutt rschutt@usd259.net Summer 2015 Voice Level 0 while facilitator or others are speaking Voice Level 1 for partner work
JAMAICA TEST PAPERS GRADE 4 PDF
 JAMAICA TEST PAPERS GRADE 4 PDF ==> Download: JAMAICA TEST PAPERS GRADE 4 PDF JAMAICA TEST PAPERS GRADE 4 PDF - Are you searching for Jamaica Test Papers Grade 4 Books? Now, you will be happy that at this
JAMAICA TEST PAPERS GRADE 4 PDF ==> Download: JAMAICA TEST PAPERS GRADE 4 PDF JAMAICA TEST PAPERS GRADE 4 PDF - Are you searching for Jamaica Test Papers Grade 4 Books? Now, you will be happy that at this
Reducing Spoon-Feeding to Promote Independent Thinking
 Reducing Spoon-Feeding to Promote Independent Thinking Janice T. Blane This paper was completed and submitted in partial fulfillment of the Master Teacher Program, a 2-year faculty professional development
Reducing Spoon-Feeding to Promote Independent Thinking Janice T. Blane This paper was completed and submitted in partial fulfillment of the Master Teacher Program, a 2-year faculty professional development
Welcome to SAT Brain Boot Camp (AJH, HJH, FJH)
") Welcome to SAT Brain Boot Camp (AJH, HJH, FJH) 9:30 am - 9:45 am ALL STUDENTS: Basics: Moreno Multipurpose Room 9:45 am - 10:15 am Breakout Session #1 RED GROUP: SAT Math: Adame Multipurpose Room BLUE
Welcome to SAT Brain Boot Camp (AJH, HJH, FJH) 9:30 am - 9:45 am ALL STUDENTS: Basics: Moreno Multipurpose Room 9:45 am - 10:15 am Breakout Session #1 RED GROUP: SAT Math: Adame Multipurpose Room BLUE
Making the ELPS-TELPAS Connection Grades K 12 Overview
 Making the ELPS-TELPAS Connection Grades K 12 Overview 2017-2018 Texas Education Agency Student Assessment Division. Disclaimer These slides have been prepared by the Student Assessment Division of the
Making the ELPS-TELPAS Connection Grades K 12 Overview 2017-2018 Texas Education Agency Student Assessment Division. Disclaimer These slides have been prepared by the Student Assessment Division of the
Express, an International Journal of Multi Disciplinary Research ISSN: , Vol. 1, Issue 3, March 2014 Available at: journal.
 The Role of Teacher in the Postmethod Era by Mahshad Tasnimi Department of English, Qazvin Branch, Islamic Azad University, Tehran, Iran E-mail: mtasnimi@yahoo.com Abstract In the postmethod era, the role
The Role of Teacher in the Postmethod Era by Mahshad Tasnimi Department of English, Qazvin Branch, Islamic Azad University, Tehran, Iran E-mail: mtasnimi@yahoo.com Abstract In the postmethod era, the role
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
Universal Design for Learning Lesson Plan
 Universal Design for Learning Lesson Plan Teacher(s): Alexandra Romano Date: April 9 th, 2014 Subject: English Language Arts NYS Common Core Standard: RL.5 Reading Standards for Literature Cluster Key
Universal Design for Learning Lesson Plan Teacher(s): Alexandra Romano Date: April 9 th, 2014 Subject: English Language Arts NYS Common Core Standard: RL.5 Reading Standards for Literature Cluster Key