Exploration (Part 2) and Transfer Learning. CS : Deep Reinforcement Learning Sergey Levine
|
|
|
- Byron Augustine Gregory
- 6 years ago
- Views:
Transcription
1 Exploration (Part 2) and Transfer Learning CS : Deep Reinforcement Learning Sergey Levine
2 Class Notes 1. Homework 4 due today! Last one!
3 Recap: classes of exploration methods in deep RL Optimistic exploration: new state = good state requires estimating state visitation frequencies or novelty typically realized by means of exploration bonuses Thompson sampling style algorithms: learn distribution over Q-functions or policies sample and act according to sample Information gain style algorithms reason about information gain from visiting new states


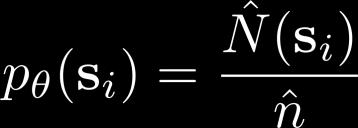
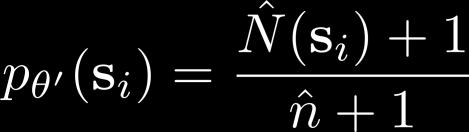
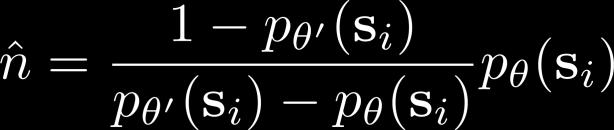
4 Recap: exploring with pseudo-counts Bellemare et al. Unifying Count-Based Exploration
5 Posterior sampling in deep RL Thompson sampling: What do we sample? How do we represent the distribution? since Q-learning is off-policy, we don t care which Q-function was used to collect data Osband et al. Deep Exploration via Bootstrapped DQN


6 Bootstrap Osband et al. Deep Exploration via Bootstrapped DQN



7 Why does this work? Exploring with random actions (e.g., epsilon-greedy): oscillate back and forth, might not go to a coherent or interesting place Exploring with random Q-functions: commit to a randomized but internally consistent strategy for an entire episode + no change to original reward function - very good bonuses often do better Osband et al. Deep Exploration via Bootstrapped DQN
8 Reasoning about information gain (approximately) Info gain: Generally intractable to use exactly, regardless of what is being estimated!
9 Reasoning about information gain (approximately) Generally intractable to use exactly, regardless of what is being estimated A few approximations: (Schmidhuber 91, Bellemare 16) intuition: if density changed a lot, the state was novel (Houthooft et al. VIME )
10 Reasoning about information gain (approximately) VIME implementation: Houthooft et al. VIME

11 Reasoning about information gain (approximately) VIME implementation: Approximate IG: + appealing mathematical formalism - models are more complex, generally harder to use effectively Houthooft et al. VIME
12 Exploration with model errors Stadie et al. 2015: encode image observations using auto-encoder build predictive model on auto-encoder latent states use model error as exploration bonus Schmidhuber et al. (see, e.g. Formal Theory of Creativity, Fun, and Intrinsic Motivation): exploration bonus for model error exploration bonus for model gradient many other variations Many others!
13 Suggested readings Schmidhuber. (1992). A Possibility for Implementing Curiosity and Boredom in Model-Building Neural Controllers. Stadie, Levine, Abbeel (2015). Incentivizing Exploration in Reinforcement Learning with Deep Predictive Models. Osband, Blundell, Pritzel, Van Roy. (2016). Deep Exploration via Bootstrapped DQN. Houthooft, Chen, Duan, Schulman, De Turck, Abbeel. (2016). VIME: Variational Information Maximizing Exploration. Bellemare, Srinivasan, Ostroviski, Schaul, Saxton, Munos. (2016). Unifying Count-Based Exploration and Intrinsic Motivation. Tang, Houthooft, Foote, Stooke, Chen, Duan, Schulman, De Turck, Abbeel. (2016). #Exploration: A Study of Count-Based Exploration for Deep Reinforcement Learning. Fu, Co-Reyes, Levine. (2017). EX2: Exploration with Exemplar Models for Deep Reinforcement Learning.
14 Next: transfer learning and meta-learning 1. The benefits of sharing knowledge across tasks 2. The transfer learning problem in RL 3. The meta-learning problem statement, algorithms Goals: Understand how reinforcement learning algorithms can benefit from structure learned on prior tasks Understand prior work on transfer learning Understand meta-learning, how it differs from transfer learning
15 Back to Montezuma s Revenge We know what to do because we understand what these sprites mean! Key: we know it opens doors! Ladders: we know we can climb them! Skull: we don t know what it does, but we know it can t be good! Prior understanding of problem structure can help us solve complex tasks quickly!
16 Can RL use the same prior knowledge as us? If we ve solved prior tasks, we might acquire useful knowledge for solving a new task How is the knowledge stored? Q-function: tells us which actions or states are good Policy: tells us which actions are potentially useful some actions are never useful! Features/hidden states: provide us with a good representation Don t underestimate this!

17 Aside: the representation bottleneck slide adapted from E. Schelhamer, Loss is its own reward
18 Transfer learning terminology transfer learning: using experience from one set of tasks for faster learning and better performance on a new task in RL, task = MDP! source domain target domain shot : number of attempts in the target domain 0-shot: just run a policy trained in the source domain 1-shot: try the task once few shot: try the task a few times slide adapted from C. Finn
19 How can we frame transfer learning problems? No single solution! Survey of various recent research papers 1. Forward transfer: train on one task, transfer to a new task a) Just try it and hope for the best b) Architectures for transfer: progressive networks c) Finetune on the new task d) Randomize source task domain 2. Multi-task transfer: train on many tasks, transfer to a new task a) Model-based reinforcement learning b) Model distillation c) Contextual policies d) Modular policy networks 3. Multi-task meta-learning: learn to learn from many tasks a) RNN-based meta-learning b) Gradient-based meta-learning
20 Break
21 How can we frame transfer learning problems? 1. Forward transfer: train on one task, transfer to a new task a) Just try it and hope for the best b) Finetune on the new task c) Architectures for transfer: progressive networks d) Randomize source task domain 2. Multi-task transfer: train on many tasks, transfer to a new task a) Model-based reinforcement learning b) Model distillation c) Contextual policies d) Modular policy networks 3. Multi-task meta-learning: learn to learn from many tasks a) RNN-based meta-learning b) Gradient-based meta-learning
22 Try it and hope for the best Policies trained for one set of circumstances might just work in a new domain, but no promises or guarantees



23 Try it and hope for the best Policies trained for one set of circumstances might just work in a new domain, but no promises or guarantees Levine*, Finn*, et al. 16 Devin et al. 17




24 Finetuning The most popular transfer learning method in (supervised) deep learning! Where are the ImageNet features of RL?

25 Challenges with finetuning in RL 1. RL tasks are generally much less diverse Features are less general Policies & value functions become overly specialized 2. Optimal policies in deterministic MDPs are deterministic Loss of exploration at convergence Low-entropy policies adapt very slowly to new settings
26 Finetuning with maximum-entropy policies How can we increase diversity and entropy? policy entropy Act as randomly as possible while collecting high rewards!


27 Example: pre-training for robustness Learning to solve a task in all possible ways provides for more robust transfer!



28 Example: pre-training for diversity Haarnoja*, Tang*, et al. Reinforcement Learning with Deep Energy-Based Policies
29 Architectures for transfer: progressive networks An issue with finetuning Deep networks work best when they are big When we finetune, we typically want to use a little bit of experience Little bit of experience + big network = overfitting Can we somehow finetune a small network, but still pretrain a big network? Idea 1: finetune just a few layers Limited expressiveness Big error gradients can wipe out initialization finetune only this? (comparatively) small FC layer big FC layer big convolutional tower
30 Architectures for transfer: progressive networks An issue with finetuning Deep networks work best when they are big When we finetune, we typically want to use a little bit of experience Little bit of experience + big network = overfitting Can we somehow finetune a small network, but still pretrain a big network? Idea 1: finetune just a few layers Limited expressiveness Big error gradients can wipe out initialization Idea 2: add new layers for the new task Freeze the old layers, so no forgetting Rusu et al. Progressive Neural Networks
31 Architectures for transfer: progressive networks An issue with finetuning Deep networks work best when they are big When we finetune, we typically want to use a little bit of experience Little bit of experience + big network = overfitting Can we somehow finetune a small network, but still pretrain a big network? Idea 1: finetune just a few layers Limited expressiveness Big error gradients can wipe out initialization Idea 2: add new layers for the new task Freeze the old layers, so no forgetting Rusu et al. Progressive Neural Networks

32 Architectures for transfer: progressive networks Does it work? sort of Rusu et al. Progressive Neural Networks

33 Architectures for transfer: progressive networks Does it work? sort of + alleviates some issues with finetuning - not obvious how serious these issues are Rusu et al. Progressive Neural Networks
34 Finetuning summary Try and hope for the best Sometimes there is enough variability during training to generalize Finetuning A few issues with finetuning in RL Maximum entropy training can help Architectures for finetuning: progressive networks Addresses some overfitting and expressivity problems by construction
35 What if we can manipulate the source domain? So far: source domain (e.g., empty room) and target domain (e.g., corridor) are fixed What if we can design the source domain, and we have a difficult target domain? Often the case for simulation to real world transfer Same idea: the more diversity we see at training time, the better we will transfer!



36 EPOpt: randomizing physical parameters training on single torso mass training on model ensemble train test ensemble adaptation unmodeled effects adapt Rajeswaran et al., EPOpt: Learning robust neural network policies

37 Preparing for the unknown: explicit system ID system identification RNN model parameters (e.g., mass) policy Yu et al., Preparing for the Unknown: Learning a Universal Policy with Online System Identification
38 CAD2RL: randomization for real-world control Sadeghi et al., CAD2RL: Real Single-Image Flight without a Single Real Image


39 CAD2RL: randomization for real-world control Sadeghi et al., CAD2RL: Real Single-Image Flight without a Single Real Image

40 Sadeghi et al., CAD2RL: Real Single-Image Flight without a Single Real Image


41 Randomization for manipulation Tobin, Fong, Ray, Schneider, Zaremba, Abbeel James, Davison, Johns
42 What if we can peek at the target domain? So far: pure 0-shot transfer: learn in source domain so that we can succeed in unknown target domain Not possible in general: if we know nothing about the target domain, the best we can do is be as robust as possible What if we saw a few images of the target domain?



43 Better transfer through domain adaptation simulated images real images adversarial loss causes internal CNN features to be indistinguishable for sim and real Tzeng*, Devin*, et al., Adapting Visuomotor Representations with Weak Pairwise Constraints

44 Domain adaptation at the pixel level can we learn to turn synthetic images into realistic ones? Bousmalis et al., Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
45 Bousmalis et al., Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping
46 Forward transfer summary Pretraining and finetuning Standard finetuning with RL is hard Maximum entropy formulation can help How can we modify the source domain for transfer? Randomization can help a lot: the more diverse the better! How can we use modest amounts of target domain data? Domain adaptation: make the network unable to distinguish observations from the two domains or modify the source domain observations to look like target domain Only provides invariance assumes all differences are functionally irrelevant; this is not always enough!
47 Forward transfer suggested readings Haarnoja*, Tang*, Abbeel, Levine. (2017). Reinforcement Learning with Deep Energy-Based Policies. Rusu et al. (2016). Progress Neural Networks. Rajeswaran, Ghotra, Levine, Ravindran. (2017). EPOpt: Learning Robust Neural Network Policies Using Model Ensembles. Sadeghi, Levine. (2017). CAD2RL: Real Single Image Flight without a Single Real Image. Tobin, Fong, Ray, Schneider, Zaremba, Abbeel. (2017). Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World. Tzeng*, Devin*, et al. (2016). Adapting Deep Visuomotor Representations with Weak Pairwise Constraints. Bousmalis et al. (2017). Using Simulation and Domain Adaptation to Improve Efficiency of Deep Robotic Grasping.
48 How can we frame transfer learning problems? 1. Forward transfer: train on one task, transfer to a new task a) Just try it and hope for the best b) Finetune on the new task more on this next time! c) Architectures for transfer: progressive networks d) Randomize source task domain 2. Multi-task transfer: train on many tasks, transfer to a new task a) Model-based reinforcement learning b) Model distillation c) Contextual policies d) Modular policy networks 3. Multi-task meta-learning: learn to learn from many tasks a) RNN-based meta-learning b) Gradient-based meta-learning
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task
 Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
arxiv: v1 [cs.lg] 8 Mar 2017
![arxiv: v1 [cs.lg] 8 Mar 2017](/thumbs/71/66141350.jpg "arxiv: v1 [cs.lg] 8 Mar 2017") Lerrel Pinto 1 James Davidson 2 Rahul Sukthankar 3 Abhinav Gupta 1 3 arxiv:173.272v1 [cs.lg] 8 Mar 217 Abstract Deep neural networks coupled with fast simulation and improved computation have led to recent
Lerrel Pinto 1 James Davidson 2 Rahul Sukthankar 3 Abhinav Gupta 1 3 arxiv:173.272v1 [cs.lg] 8 Mar 217 Abstract Deep neural networks coupled with fast simulation and improved computation have led to recent
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Improving Conceptual Understanding of Physics with Technology
 INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
INTRODUCTION Improving Conceptual Understanding of Physics with Technology Heidi Jackman Research Experience for Undergraduates, 1999 Michigan State University Advisors: Edwin Kashy and Michael Thoennessen
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
arxiv: v1 [cs.cv] 10 May 2017
![arxiv: v1 [cs.cv] 10 May 2017](/thumbs/71/66178677.jpg "arxiv: v1 [cs.cv] 10 May 2017") Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Inferring and Executing Programs for Visual Reasoning Justin Johnson 1 Bharath Hariharan 2 Laurens van der Maaten 2 Judy Hoffman 1 Li Fei-Fei 1 C. Lawrence Zitnick 2 Ross Girshick 2 1 Stanford University
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Cognitive Thinking Style Sample Report
 Cognitive Thinking Style Sample Report Goldisc Limited Authorised Agent for IML, PeopleKeys & StudentKeys DISC Profiles Online Reports Training Courses Consultations sales@goldisc.co.uk Telephone: +44
Cognitive Thinking Style Sample Report Goldisc Limited Authorised Agent for IML, PeopleKeys & StudentKeys DISC Profiles Online Reports Training Courses Consultations sales@goldisc.co.uk Telephone: +44
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
arxiv: v2 [cs.ro] 3 Mar 2017
![arxiv: v2 [cs.ro] 3 Mar 2017](/thumbs/71/66179626.jpg "arxiv: v2 [cs.ro] 3 Mar 2017") Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
How People Learn Physics
 How People Learn Physics Edward F. (Joe) Redish Dept. Of Physics University Of Maryland AAPM, Houston TX, Work supported in part by NSF grants DUE #04-4-0113 and #05-2-4987 Teaching complex subjects 2
How People Learn Physics Edward F. (Joe) Redish Dept. Of Physics University Of Maryland AAPM, Houston TX, Work supported in part by NSF grants DUE #04-4-0113 and #05-2-4987 Teaching complex subjects 2
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Full text of O L O W Science As Inquiry conference. Science as Inquiry
 Page 1 of 5 Full text of O L O W Science As Inquiry conference Reception Meeting Room Resources Oceanside Unifying Concepts and Processes Science As Inquiry Physical Science Life Science Earth & Space
Page 1 of 5 Full text of O L O W Science As Inquiry conference Reception Meeting Room Resources Oceanside Unifying Concepts and Processes Science As Inquiry Physical Science Life Science Earth & Space
K5 Math Practice. Free Pilot Proposal Jan -Jun Boost Confidence Increase Scores Get Ahead. Studypad, Inc.
 K5 Math Practice Boost Confidence Increase Scores Get Ahead Free Pilot Proposal Jan -Jun 2017 Studypad, Inc. 100 W El Camino Real, Ste 72 Mountain View, CA 94040 Table of Contents I. Splash Math Pilot
K5 Math Practice Boost Confidence Increase Scores Get Ahead Free Pilot Proposal Jan -Jun 2017 Studypad, Inc. 100 W El Camino Real, Ste 72 Mountain View, CA 94040 Table of Contents I. Splash Math Pilot
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Experience Corps. Mentor Toolkit
 Experience Corps Mentor Toolkit 2 AARP Foundation Experience Corps Mentor Toolkit June 2015 Christian Rummell Ed. D., Senior Researcher, AIR 3 4 Contents Introduction and Overview...6 Tool 1: Definitions...8
Experience Corps Mentor Toolkit 2 AARP Foundation Experience Corps Mentor Toolkit June 2015 Christian Rummell Ed. D., Senior Researcher, AIR 3 4 Contents Introduction and Overview...6 Tool 1: Definitions...8
Practice Examination IREB
 IREB Examination Requirements Engineering Advanced Level Elicitation and Consolidation Practice Examination Questionnaire: Set_EN_2013_Public_1.2 Syllabus: Version 1.0 Passed Failed Total number of points
IREB Examination Requirements Engineering Advanced Level Elicitation and Consolidation Practice Examination Questionnaire: Set_EN_2013_Public_1.2 Syllabus: Version 1.0 Passed Failed Total number of points
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Course Content Concepts
 CS 1371 SYLLABUS, Fall, 2017 Revised 8/6/17 Computing for Engineers Course Content Concepts The students will be expected to be familiar with the following concepts, either by writing code to solve problems,
CS 1371 SYLLABUS, Fall, 2017 Revised 8/6/17 Computing for Engineers Course Content Concepts The students will be expected to be familiar with the following concepts, either by writing code to solve problems,
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
ECE-492 SENIOR ADVANCED DESIGN PROJECT
 ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Accelerated Learning Course Outline
 Accelerated Learning Course Outline Course Description The purpose of this course is to make the advances in the field of brain research more accessible to educators. The techniques and strategies of Accelerated
Accelerated Learning Course Outline Course Description The purpose of this course is to make the advances in the field of brain research more accessible to educators. The techniques and strategies of Accelerated
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
A Bootstrapping Model of Frequency and Context Effects in Word Learning
 Cognitive Science 41 (2017) 590 622 Copyright 2016 Cognitive Science Society, Inc. All rights reserved. ISSN: 0364-0213 print / 1551-6709 online DOI: 10.1111/cogs.12353 A Bootstrapping Model of Frequency
Cognitive Science 41 (2017) 590 622 Copyright 2016 Cognitive Science Society, Inc. All rights reserved. ISSN: 0364-0213 print / 1551-6709 online DOI: 10.1111/cogs.12353 A Bootstrapping Model of Frequency
Litterature review of Soft Systems Methodology
 Thomas Schmidt nimrod@mip.sdu.dk October 31, 2006 The primary ressource for this reivew is Peter Checklands article Soft Systems Metodology, secondary ressources are the book Soft Systems Methodology in
Thomas Schmidt nimrod@mip.sdu.dk October 31, 2006 The primary ressource for this reivew is Peter Checklands article Soft Systems Metodology, secondary ressources are the book Soft Systems Methodology in
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Learning and Teaching
 Learning and Teaching Set Induction and Closure: Key Teaching Skills John Dallat March 2013 The best kind of teacher is one who helps you do what you couldn t do yourself, but doesn t do it for you (Child,
Learning and Teaching Set Induction and Closure: Key Teaching Skills John Dallat March 2013 The best kind of teacher is one who helps you do what you couldn t do yourself, but doesn t do it for you (Child,
P-4: Differentiate your plans to fit your students
 Putting It All Together: Middle School Examples 7 th Grade Math 7 th Grade Science SAM REHEARD, DC 99 7th Grade Math DIFFERENTATION AROUND THE WORLD My first teaching experience was actually not as a Teach
Putting It All Together: Middle School Examples 7 th Grade Math 7 th Grade Science SAM REHEARD, DC 99 7th Grade Math DIFFERENTATION AROUND THE WORLD My first teaching experience was actually not as a Teach
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Possibilities in engaging partnerships: What happens when we work together?
 Rhode Island College Digital Commons @ RIC Innovation Lab 11-2-2013 Possibilities in engaging partnerships: What happens when we work together? Julie Horwitz Rhode Island College, jhorwitz@ric.edu Gerri
Rhode Island College Digital Commons @ RIC Innovation Lab 11-2-2013 Possibilities in engaging partnerships: What happens when we work together? Julie Horwitz Rhode Island College, jhorwitz@ric.edu Gerri
arxiv: v1 [cs.dc] 19 May 2017
![arxiv: v1 [cs.dc] 19 May 2017](/thumbs/71/66085786.jpg "arxiv: v1 [cs.dc] 19 May 2017") Atari games and Intel processors Robert Adamski, Tomasz Grel, Maciej Klimek and Henryk Michalewski arxiv:1705.06936v1 [cs.dc] 19 May 2017 Intel, deepsense.io, University of Warsaw Robert.Adamski@intel.com,
Atari games and Intel processors Robert Adamski, Tomasz Grel, Maciej Klimek and Henryk Michalewski arxiv:1705.06936v1 [cs.dc] 19 May 2017 Intel, deepsense.io, University of Warsaw Robert.Adamski@intel.com,
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
arxiv:submit/ [cs.cv] 2 Aug 2017
![arxiv:submit/ [cs.cv] 2 Aug 2017](/thumbs/71/66192871.jpg "arxiv:submit/ [cs.cv] 2 Aug 2017") Associative Domain Adaptation Philip Haeusser 1,2 haeusser@in.tum.de Thomas Frerix 1 Alexander Mordvintsev 2 thomas.frerix@tum.de moralex@google.com 1 Dept. of Informatics, TU Munich 2 Google, Inc. Daniel
Associative Domain Adaptation Philip Haeusser 1,2 haeusser@in.tum.de Thomas Frerix 1 Alexander Mordvintsev 2 thomas.frerix@tum.de moralex@google.com 1 Dept. of Informatics, TU Munich 2 Google, Inc. Daniel
Accelerated Learning Online. Course Outline
 Accelerated Learning Online Course Outline Course Description The purpose of this course is to make the advances in the field of brain research more accessible to educators. The techniques and strategies
Accelerated Learning Online Course Outline Course Description The purpose of this course is to make the advances in the field of brain research more accessible to educators. The techniques and strategies
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX,
 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH AND LANGUAGE PROCESSING, VOL XXX, NO. XXX, 2017 1 Small-footprint Highway Deep Neural Networks for Speech Recognition Liang Lu Member, IEEE, Steve Renals Fellow,
prehending general textbooks, but are unable to compensate these problems on the micro level in comprehending mathematical texts.
 Summary Chapter 1 of this thesis shows that language plays an important role in education. Students are expected to learn from textbooks on their own, to listen actively to the instruction of the teacher,
Summary Chapter 1 of this thesis shows that language plays an important role in education. Students are expected to learn from textbooks on their own, to listen actively to the instruction of the teacher,
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING. Calendar Description Units: 1.
 University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
Navigating the PhD Options in CMS
 Navigating the PhD Options in CMS This document gives an overview of the typical student path through the four Ph.D. programs in the CMS department ACM, CDS, CS, and CMS. Note that it is not a replacement
Navigating the PhD Options in CMS This document gives an overview of the typical student path through the four Ph.D. programs in the CMS department ACM, CDS, CS, and CMS. Note that it is not a replacement
PREP S SPEAKER LISTENER TECHNIQUE COACHING MANUAL
 1 PREP S SPEAKER LISTENER TECHNIQUE COACHING MANUAL IMPORTANCE OF THE SPEAKER LISTENER TECHNIQUE The Speaker Listener Technique (SLT) is a structured communication strategy that promotes clarity, understanding,
1 PREP S SPEAKER LISTENER TECHNIQUE COACHING MANUAL IMPORTANCE OF THE SPEAKER LISTENER TECHNIQUE The Speaker Listener Technique (SLT) is a structured communication strategy that promotes clarity, understanding,
Algorithms and Data Structures (NWI-IBC027)
") Algorithms and Data Structures (NWI-IBC027) Frits Vaandrager F.Vaandrager@cs.ru.nl Institute for Computing and Information Sciences 7th September 2017 Frits Vaandrager 7th September 2017 Lecture 1 1 /
Algorithms and Data Structures (NWI-IBC027) Frits Vaandrager F.Vaandrager@cs.ru.nl Institute for Computing and Information Sciences 7th September 2017 Frits Vaandrager 7th September 2017 Lecture 1 1 /
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma
 Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semantic Segmentation with Histological Image Data: Cancer Cell vs. Stroma Adam Abdulhamid Stanford University 450 Serra Mall, Stanford, CA 94305 adama94@cs.stanford.edu Abstract With the introduction
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
District Advisory Committee. October 27, 2015
 District Advisory Committee October 27, 2015 Outcomes for Today Understanding and awareness of needs for the 21 st century workforce and how these skills are changing education Deeper understanding of
District Advisory Committee October 27, 2015 Outcomes for Today Understanding and awareness of needs for the 21 st century workforce and how these skills are changing education Deeper understanding of
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
ENG 111 Achievement Requirements Fall Semester 2007 MWF 10:30-11: OLSC
 Fleitz/ENG 111 1 Contact Information ENG 111 Achievement Requirements Fall Semester 2007 MWF 10:30-11:20 227 OLSC Instructor: Elizabeth Fleitz Email: efleitz@bgsu.edu AIM: bluetea26 (I m usually available
Fleitz/ENG 111 1 Contact Information ENG 111 Achievement Requirements Fall Semester 2007 MWF 10:30-11:20 227 OLSC Instructor: Elizabeth Fleitz Email: efleitz@bgsu.edu AIM: bluetea26 (I m usually available
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer