Reinforcement Learning I
|
|
|
- Vanessa Patterson
- 6 years ago
- Views:
Transcription
1 CSC411 Fall 2014 Machine Learning & Data Mining Reinforcement Learning I Slides from Rich Zemel
2 Reinforcement Learning Learning classes differ in information available to learner Supervised: correct outputs Unsupervised: no feedback, must construct measure of good output Reinforcement learning More realistic learning scenario: Continuous stream of input information, and actions Effects of action depend on state of the world Obtain reward that depends on world state and actions not correct response, just some feedback
3 Formula2ng Reinforcement Learning World described by a discrete, Einite set of states and actions At every time step t, we are in a state s t, and we: Take an action a t (possibly null action) Receive some reward r t+1 Move into a new state s t+1 Decisions can be described by a policy a selection of which action to take, based on the current state Aim is to maximize the total reward we receive over time Sometimes a future reward is discounted by γ k- 1, where k is the number of time- steps in the future when it is received
4 Tic- Tac- Toe Make this concrete by considering specieic example Consider the game tic- tac- toe: reward: win/lose/tie the game (+1/- 1/0) [only at Einal move in given game] state: positions of Xs and Os on the board policy: mapping from states to actions based on rules of game: choice of one open position value function: prediction of reward in future, based on current state In tic- tac- toe, since state space is tractable, can use a table to represent value function

5 RL & Tic- Tac- Toe Each board position (taking into account symmetry) has associated probability Simple learning process: start with all values = 0.5 policy: choose move with highest probability of winning given current legal moves from current state update entries in table based on outcome of each game After many games value function will represent true probability of winning from each state Can try alternative policy: sometimes select moves randomly (exploration)
6 Ac2ng Under Uncertainty The world and the actor may not be deterministic, or our model of the world may be incomplete We assume the Markov property: the future depends on the past only through the current state We describe the environment by a distribution over rewards and state transitions: The policy can also be non- deterministic: Policy is not a Eixed sequence of actions, but instead a conditional plan
7 Basic Problems Markov Decision Problem (MDP): tuple <S,A,P,γ> where P is Standard MDP problems: 1. Planning: given complete Markov decision problem as input, compute policy with optimal expected return 2. Learning: Only have access to experience in the MDP, learn a near- optimal strategy
8 Example of Standard MDP Problem 1. Planning: given complete Markov decision problem as input, compute policy with optimal expected return 2. Learning: Only have access to experience in the MDP, learn a near- optimal strategy We will focus on learning, but discuss planning along the way
9 Explora2on vs. Exploita2on If we knew how world works (embodied in P), then the policy should be deterministic just select optimal action in each state. But if we do not have complete knowledge of the world, taking what appears to be the optimal action may prevent us from Einding better states/actions Interesting trade- off: immediate reward (exploitation) vs. gaining knowledge that might enable higher future reward (exploration)
10 Bellman Equa2on Decision theory: maximize expected utility (related to rewards) DeEine the value function V(s): measures accumulated future rewards (value) from state s The relationship between a current state and its successor state is deeined by the Bellman equation: Discount factor γ: controls whether care only about immediate reward, or can appreciate delayed gratieication Can show that if value functions updated via Bellman equation, and γ < 1, V() will converge to optimal (estimate of expected reward given best policy)
11 Expected value of a policy Key recursive relationship between value function at successive states If we Eix some policy, π (deeines the distribution over actions for each state), then the value of a state is the expected discounted reward for following that policy from that state on: This value function will satisfy the following consistency equation (generalized Bellman equation):
12 RL: Some Examples Many natural problems have structure required for RL: 1. Game playing: know win/lose but not specieic moves (TD- gammon) 2. Control: for trafeic lights, can measure delay of cars, but not how to decrease it 3. Robot juggling 4. Robot path planning: can tell distance traveled, but not how to minimize
13 MDP formula2on Goal: Eind policy π that maximizes expected accumulated future rewards V π (s t ), obtained by following π from state s t : Game show example: assume series of questions, increasingly difeicult, but increasing payoff choice: accept accumulated earnings and quit; or continue and risk losing everything
14 We might try to learn the value function V (which we write as V*) We could then do a lookahead search to choose best action from any state s: where What to Learn V *(s) = max a [r(s, a)+γv *(δ(s, a))] π *(s) = argmax a [r(s,a)+γv *(δ(s,a))] P(s t +1 = s',r t +1 = r' s t = s,a t = a) = P(s t +1 = s' s t = s,a t = a)p(r t +1 = r' s t = s,a t = a) = δ(s,a)r(s,a) But there s a problem: This works well if we know δ() and r() But when we don t, we cannot choose actions this way
15 What to Learn Let us Eirst assume that δ() and r() are deterministic: V *(s) = max a [r(s, a)+γv *(δ(s, a))] π *(s) = argmax a [r(s,a)+γv *(δ(s,a))] Remember: Reward function At every time step t, we are in a state s t, and we: Take an action a t (possibly null action) Receive some reward r t+1 r : (s,a) r Move into a new state s t+1 δ : (s,a) s How can we do learning? Transition function
16 Q Learning DeEine a new function very similar to V* Q(s, a) r(s, a)+γv *(δ(s, a)) If we learn Q, we can choose the optimal action even without knowing δ! π *(s) = argmax a [r(s, a)+γv *(δ(s, a))] Q is then the evaluation function we will learn
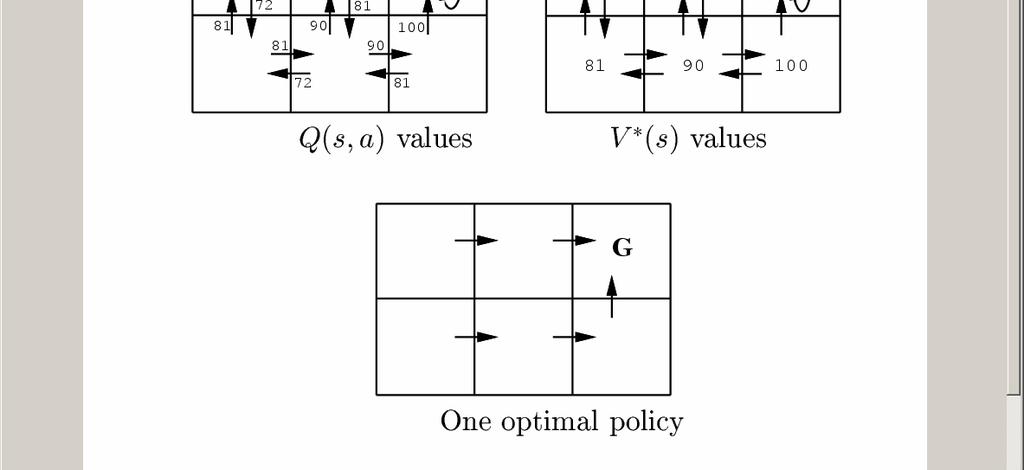
17
18 Q and V* are closely related: So we can write Q recursively: Training Rule to Learn Q Let Q^ denote the learner s current approximation to Q Consider training rule ˆQ(s, a) r(s, a)+γ max a' ˆQ(s', a') where s is state resulting from applying action a in state s
19 Q Learning for Determinis2c World For each s,a initialize table entry Q^(s,a) ß 0 Start in some initial state s Do forever: Select an action a and execute it Receive immediate reward r Observe the new state s Update the table entry for Q^(s,a) using Q learning rule: s ß s ˆQ(s, a) r(s, a)+γ max a' ˆQ(s', a') If get to absorbing state, restart to initial state, and run thru Do forever loop until reach absorbing state

20 Upda2ng Es2mated Q Assume Robot is in state s 1 ; some of its current estimates of Q are as shown; executes rightward move Notice that if rewards are non- negative, then Q^ values only increase from 0, approach true Q
21 Q Learning: Summary training set consists of series of intervals (episodes): sequence of (state, action, reward) triples, end at absorbing state Each executed action a results in transition from state s i to s j ; algorithm updates Q^(s i,a) using the learning rule Intuition for simple grid world, reward only upon entering goal state à Q estimates improve from goal state back 1. All Q^(s,a) start at 0 2. First episode only update Q^(s,a) for transition leading to goal state 3. Next episode if go thru this next- to- last transition, will update Q^(s,a) another step back 4. Eventually propagate information from transitions with non- zero reward throughout state- action space
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
How long did... Who did... Where was... When did... How did... Which did...
 (Past Tense) Who did... Where was... How long did... When did... How did... 1 2 How were... What did... Which did... What time did... Where did... What were... Where were... Why did... Who was... How many
(Past Tense) Who did... Where was... How long did... When did... How did... 1 2 How were... What did... Which did... What time did... Where did... What were... Where were... Why did... Who was... How many
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Transfer Learning Action Models by Measuring the Similarity of Different Domains
 Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
Transfer Learning Action Models by Measuring the Similarity of Different Domains Hankui Zhuo 1, Qiang Yang 2, and Lei Li 1 1 Software Research Institute, Sun Yat-sen University, Guangzhou, China. zhuohank@gmail.com,lnslilei@mail.sysu.edu.cn
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
College Pricing. Ben Johnson. April 30, Abstract. Colleges in the United States price discriminate based on student characteristics
 College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Planning with External Events
 94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design
 Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
Session 2B From understanding perspectives to informing public policy the potential and challenges for Q findings to inform survey design Paper #3 Five Q-to-survey approaches: did they work? Job van Exel
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games
 Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
Proceedings of the Twenty-Fifth International Florida Artificial Intelligence Research Society Conference Case Acquisition Strategies for Case-Based Reasoning in Real-Time Strategy Games Santiago Ontañón
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Grade 5 + DIGITAL. EL Strategies. DOK 1-4 RTI Tiers 1-3. Flexible Supplemental K-8 ELA & Math Online & Print
 Standards PLUS Flexible Supplemental K-8 ELA & Math Online & Print Grade 5 SAMPLER Mathematics EL Strategies DOK 1-4 RTI Tiers 1-3 15-20 Minute Lessons Assessments Consistent with CA Testing Technology
Standards PLUS Flexible Supplemental K-8 ELA & Math Online & Print Grade 5 SAMPLER Mathematics EL Strategies DOK 1-4 RTI Tiers 1-3 15-20 Minute Lessons Assessments Consistent with CA Testing Technology
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
An Introduction to Simulation Optimization
 An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
An Introduction to Simulation Optimization Nanjing Jian Shane G. Henderson Introductory Tutorials Winter Simulation Conference December 7, 2015 Thanks: NSF CMMI1200315 1 Contents 1. Introduction 2. Common
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling
 Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
An Effective Framework for Fast Expert Mining in Collaboration Networks: A Group-Oriented and Cost-Based Method
 Farhadi F, Sorkhi M, Hashemi S et al. An effective framework for fast expert mining in collaboration networks: A grouporiented and cost-based method. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(3): 577
Farhadi F, Sorkhi M, Hashemi S et al. An effective framework for fast expert mining in collaboration networks: A grouporiented and cost-based method. JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 27(3): 577
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Computer Science 1015F ~ 2016 ~ Notes to Students
 Computer Science 1015F ~ 2016 ~ Notes to Students Course Description Computer Science 1015F and 1016S together constitute a complete Computer Science curriculum for first year students, offering an introduction
Computer Science 1015F ~ 2016 ~ Notes to Students Course Description Computer Science 1015F and 1016S together constitute a complete Computer Science curriculum for first year students, offering an introduction
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
ALL-IN-ONE MEETING GUIDE THE ECONOMICS OF WELL-BEING
 ALL-IN-ONE MEETING GUIDE THE ECONOMICS OF WELL-BEING LeanIn.0rg, 2016 1 Overview Do we limit our thinking and focus only on short-term goals when we make trade-offs between career and family? This final
ALL-IN-ONE MEETING GUIDE THE ECONOMICS OF WELL-BEING LeanIn.0rg, 2016 1 Overview Do we limit our thinking and focus only on short-term goals when we make trade-offs between career and family? This final
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Finding Your Friends and Following Them to Where You Are
 Finding Your Friends and Following Them to Where You Are Adam Sadilek Dept. of Computer Science University of Rochester Rochester, NY, USA sadilek@cs.rochester.edu Henry Kautz Dept. of Computer Science
Finding Your Friends and Following Them to Where You Are Adam Sadilek Dept. of Computer Science University of Rochester Rochester, NY, USA sadilek@cs.rochester.edu Henry Kautz Dept. of Computer Science
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming
 Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Data Mining VI 205 Rule discovery in Web-based educational systems using Grammar-Based Genetic Programming C. Romero, S. Ventura, C. Hervás & P. González Universidad de Córdoba, Campus Universitario de
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization
 A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization Stefan Henß TU Darmstadt, Germany stefan.henss@gmail.com Margot Mieskes h da Darmstadt & AIPHES Germany margot.mieskes@h-da.de
A Reinforcement Learning Approach for Adaptive Single- and Multi-Document Summarization Stefan Henß TU Darmstadt, Germany stefan.henss@gmail.com Margot Mieskes h da Darmstadt & AIPHES Germany margot.mieskes@h-da.de
Using AMT & SNOMED CT-AU to support clinical research
 Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
1.11 I Know What Do You Know?
 50 SECONDARY MATH 1 // MODULE 1 1.11 I Know What Do You Know? A Practice Understanding Task CC BY Jim Larrison https://flic.kr/p/9mp2c9 In each of the problems below I share some of the information that
50 SECONDARY MATH 1 // MODULE 1 1.11 I Know What Do You Know? A Practice Understanding Task CC BY Jim Larrison https://flic.kr/p/9mp2c9 In each of the problems below I share some of the information that
Go fishing! Responsibility judgments when cooperation breaks down
 Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
Go fishing! Responsibility judgments when cooperation breaks down Kelsey Allen (krallen@mit.edu), Julian Jara-Ettinger (jjara@mit.edu), Tobias Gerstenberg (tger@mit.edu), Max Kleiman-Weiner (maxkw@mit.edu)
DIDACTIC MODEL BRIDGING A CONCEPT WITH PHENOMENA
 DIDACTIC MODEL BRIDGING A CONCEPT WITH PHENOMENA Beba Shternberg, Center for Educational Technology, Israel Michal Yerushalmy University of Haifa, Israel The article focuses on a specific method of constructing
DIDACTIC MODEL BRIDGING A CONCEPT WITH PHENOMENA Beba Shternberg, Center for Educational Technology, Israel Michal Yerushalmy University of Haifa, Israel The article focuses on a specific method of constructing
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Extending Learning Across Time & Space: The Power of Generalization
 Extending Learning: The Power of Generalization 1 Extending Learning Across Time & Space: The Power of Generalization Teachers have every right to celebrate when they finally succeed in teaching struggling
Extending Learning: The Power of Generalization 1 Extending Learning Across Time & Space: The Power of Generalization Teachers have every right to celebrate when they finally succeed in teaching struggling
TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION. by Yang Xu PhD of Information Sciences
 TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION by Yang Xu PhD of Information Sciences Submitted to the Graduate Faculty of in partial fulfillment of the requirements for the degree of Doctor of Philosophy
TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION by Yang Xu PhD of Information Sciences Submitted to the Graduate Faculty of in partial fulfillment of the requirements for the degree of Doctor of Philosophy
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Team Formation for Generalized Tasks in Expertise Social Networks
 IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust Team Formation for Generalized Tasks in Expertise Social Networks Cheng-Te Li Graduate
IEEE International Conference on Social Computing / IEEE International Conference on Privacy, Security, Risk and Trust Team Formation for Generalized Tasks in Expertise Social Networks Cheng-Te Li Graduate
P a g e 1. Grade 4. Grant funded by: MS Exemplar Unit English Language Arts Grade 4 Edition 1
 P a g e 1 Grade 4 Grant funded by: P a g e 2 Lesson 1: Understanding Themes Focus Standard(s): RL.4.2 Additional Standard(s): RL.4.1 Estimated Time: 1-2 days Resources and Materials: Handout 1.1: Details,
P a g e 1 Grade 4 Grant funded by: P a g e 2 Lesson 1: Understanding Themes Focus Standard(s): RL.4.2 Additional Standard(s): RL.4.1 Estimated Time: 1-2 days Resources and Materials: Handout 1.1: Details,
Generating Test Cases From Use Cases
 1 of 13 1/10/2007 10:41 AM Generating Test Cases From Use Cases by Jim Heumann Requirements Management Evangelist Rational Software pdf (155 K) In many organizations, software testing accounts for 30 to
1 of 13 1/10/2007 10:41 AM Generating Test Cases From Use Cases by Jim Heumann Requirements Management Evangelist Rational Software pdf (155 K) In many organizations, software testing accounts for 30 to
White Paper. The Art of Learning
 The Art of Learning Based upon years of observation of adult learners in both our face-to-face classroom courses and using our Mentored Email 1 distance learning methodology, it is fascinating to see how
The Art of Learning Based upon years of observation of adult learners in both our face-to-face classroom courses and using our Mentored Email 1 distance learning methodology, it is fascinating to see how
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS
 EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS by Robert Smith Submitted in partial fulfillment of the requirements for the degree of Master of
EVOLVING POLICIES TO SOLVE THE RUBIK S CUBE: EXPERIMENTS WITH IDEAL AND APPROXIMATE PERFORMANCE FUNCTIONS by Robert Smith Submitted in partial fulfillment of the requirements for the degree of Master of