What is wrong with apps and web models? Conversation as an emerging paradigm for mobile UI Bots as intelligent conversational interface agents
|
|
|
- Lee Watkins
- 6 years ago
- Views:
Transcription

1
2
3
4
 Etc. Bots Technology Overview: three generations; latest deep RL 5 http://venturebeat.com/2016/08/01/how-deep-reinforcement-learning-can-help-chatbots/")
5 What is wrong with apps and web models? Conversation as an emerging paradigm for mobile UI Bots as intelligent conversational interface agents Major types of conversational bots: ChatBots (e.g. XiaoIce) InfoBots TaskCompletion Bots (goal-oriented) Personal Assistant Bots (above + recommd.) Etc. Bots Technology Overview: three generations; latest deep RL 5
6 Consumer 1st Party Bots Head Enterprise 3rd Party Bots Long Tail Specific Knowledge (IQ) Form/Slot Filling; SQL Retrieval Multi-turn Often Needed Dialog Management Intelligent Search Single-turn Mostly Session Modeling General Knowledge (EQ) Chit-chat Emotion/Sentiment Analysis Personality
7 Generation I: Symbolic Rule/Template Based Centered on grammatical rule & ontological design by human experts (early AI approach) Easy interpretation, debugging, and system update Popular before late 90 s Still in use in commercial systems and by bots startups Limitations: reliance on experts hard to scale over domains data used only to help design rules, not for learning Example system next 7
8
9 9 Generation II: Data Driven (shallow) Learning Data used not to design rules for NLU and action, but to learn statistical parameters in dialogue systems Reduce cost of hand-crafting complex dialogue manager Robustness against speech recog errors in noisy environment MDP/POMDP & reinforcement learning for dialogue policy Discriminative (CRF) & generative (HMM) methods for NLU Popular in academic research (before deep learning arrived at the dialogue world) Limitations: Not easy to interpret, debug, and update systems Still hard to scale over domains Models & representations not powerful enough; no end-2-end, hard to scale up Remained academic until deep learning arrived Example system next
10

11 Components of a state-based spoken dialogue system
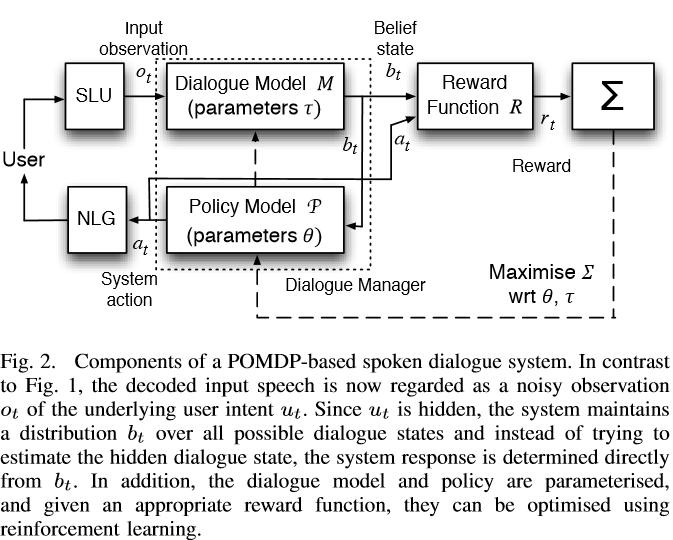
12
13 13 Generation III: Data-Driven Deep Learning Like Generation-II, data used learn everything in dialogue systems Reduce cost of hand-crafting complex dialogue manager Robustness against speech recog errors in noisy environment & against NLU errors MDP/POMDP & reinforcement learning for dialogue policy (same) But, neural models & representations are much more powerful End-to-End learning becomes feasible Attracted huge research efforts since 2015 (after deep learning s in vision/speech and in deep RL shown success in Atari games) Limitations: Still not easy to interpret, debug, and update systems Lack interface btw cont. neural learning and symbolic NL structure to human users Active research in scaling over domains via deep transfer learning & RL No clear success reported yet Deep RL & example research next
14 What is reinforcement learning (RL)? RL in Generation-II ---> not working! (with unnecessarily complex POMDP) RL in Generation-III ---> working! due to deep learning -- like NN vs DNN in ASR) RL is learning what to do so as to maximize a numerical reward signal What to do means mapping from a situation in a given environment to an action Takes inspiration from biology / psychology RL is a characterization of a problem class Doesn t refer to a specific solution There are many methods for solving RL problems In its most general form, RL problems: Have a stateful environment, where actions can change the state of the environment Learn by trial and error, not by being shown examples of the right action Have delayed rewards, where an action s value may not be clear until some time after it is taken
15 Stateful Model for RL s t Agent r t a t State estimator o t Environment s t = Summary o 0, a 0, o 1, a 1, o t 1, a t 1, o t Trajectory: a 0, r 1, s 1, a 1, r 2, s 2, a 2, Return: σ τ=t+1 γ τ 1 r τ, 1 γ 0 Policy: π s t a t Objective: π = arg max π E σ τ=t+1 γ τ 1 r τ π, s t
16 SCENARIOS ACTIONS (size of action space) MDP-STATES (size of state space) RL HORIZON REWARDS AlphaGo (DeepMind) Stone placement (max 19x19) Board configuration (max 2^{19x19}) Very long, >100 moves Win/loss: +1/-1 at end of game; local r_t uninformative (value of winning unclear, unlike chess) Atari agent (DeepMind) Joystick/button Control (12) Windowed screen shots (~infinite) Shorter (~10-50) Game score r_t at each action, very clean, no noise DeepCRM1 (Microsoft) What salesforce should do with specific customers (~20) Ensemble of customer business status over time (>10,000) Short (~2-10) Close deal: +1 or $ amount at the end of sale cycle; Otherwise 0 DeepCRM2 Cross/Up sales (Microsoft) What product/sku to sell (~1M) Existing SKUs & customer business status over time (>100,000) Short (~2-10) $ amount of SKU sales at the end of sale cycle; $0 before sales DeepCRM3 Tele-sale calls (Microsoft) Which tenant to call (~600K) Posterior distribution of reward by calling tenants (~infinite) Long (200 / week) +1 if tenant is saved, or 0 if lost
17 User input (o) Response Language understanding Language (response) generation s a Dialogue Policy a = π(s) Collect rewards (s, a, r, s ) Optimize Q(s, a) Type pf Bots State Action Reward Social ChatBots Chat history System Response # of turns maximized; Intrinsically motivated reward InfoBots (interactive Q/A) User current question + Context/history Task-Oriented Bots User current input + Context/history Answers to current question by system DialogAct w. SlotValue in current turn Relevance of answer; # of turns minimized Task success rate; # of turns minimized
18 Function Approximation In many tasks, (s, a) is too large for tabular representation Estimate the action-value function approximately as θ: a linear function (baseline) θ: a DNN, aka Deep Q-Network (DQN) Optimize θ using SGD w.r.t loss
19 Q-Learning for DQN [DeepMind 15] Learning becomes unstable Correlations present in the sequence of states Small updates to Q leads to significant change of policy and data distribution Correlations btw the to-be-learned Q and the target value r + max a Q(s, a ) Solution Experience replay: randomize training samples (s, a, r, s ) Use a separate Q function to compute targets y
20 Q-Learning [Sutton & Barto 98] Assume Q(s, a) for all s, a can be represented in a table 1. Initialize an array Q(s, a) arbitrarily 2. Choose actions based on Q such that all actions are taken in all states (infinitely often in the limit) 3. On each time step, update one element of the array: Q s t, a t = αr t+1 + γ(max a Q(s t+1, a )) Model-free learning: Learning long-term optimal behavior without model of the environment
21 Explore via ε-greedy Experience replay Use a separate Q func to compute targets y Within C steps, the For loop is a regression step with the targets determined using the fixed Q.


22 Deep Q Learning for Games --- optimizing long-term values Short-term Long-term Playing the Breakout game Optimizing Business Decision Making Maximize immediate reward Optimize life-time revenue, service usages, and customer satisfaction Self play to improve skills
23 User goal Two tickets for Deadpool tomorrow 9PM at AMC Pacific Place 11 theater, Seattle. RULE BASED SYSTEM User: Do you have any ticket for movie Deadpool at 9:00 pm? Agent: Which theater do you want? User: AMC pacific place 11 theater, please! Agent: How many tickets do you want? User: Two! Agent: What date? User: Tomorrow! Agent: Which city do you want? User: Seattle! Agent: Do you have any specification for zip code? User: No, I do not care. Agent: Do you have any distance constraint? User: No, I do not care. Agent: How about video format? 2d? Imax 3d? User: Any kind is okay. Agent: Do you have any constraint to price? User: No! Wasteful! (Very likely the user does not care.) Agent: Okay, I will issue 2 tickets for you, tomorrow 9:00 pm at AMC pacific place 11 theater, Seattle, movie Deadpool. User: Okay, thanks. Agent: Thanks! REINFORCEMENT LEARNING SYSTEM User: I want two tickets for movie Deadpool. Agent: What is the starttime you prefer? User: 9:00 PM Agent: Which day? User: Tomorrow Agent: Which city? User: Seattle Agent: Which theater do you prefer? User: AMC Pacific Place 11 theater. Agent: Okay, I will issue 2 tickets for you, tomorrow 9:00 pm at AMC pacific place 11 theater, Seattle, movie Deadpool. User: Okay, thanks. Agent: Thanks!
24 User goal Two tickets for Hail Caesar tomorrow 7:15PM at AMC Lowes Oak tree 6, Seattle. RULE BASED SYSTEM User: Do you any ticket for movie Hail Caesar at theater AMC Lowes Oak Tree 6? Agent: What start time do you prefer? User: 7:15 pm Tomorrow Agent: Which city you are looking for? User: Seattle Agent: How many tickets do you want? User: Two Agent: Okay, I have issued two tickets for movie Hail Caeser tomorrow 7:50 pm at theater AMC Lowes Oak Tree 6, Seattle. User: Oh, no. Agent: Thanks! Task failed! (Cannot correct the LU mistake.) REINFORCEMENT LEARNING SYSTEM Agent: What start time do you prefer? User: 7:15 pm Tomorrow Agent: Which city you are looking for? User: Seattle Agent: Okay, I will issue you tickets for movie Hail Caeser tomorrow 7:50 pm at theater AMC Lowes Oak Tree 6, Seattle. User: Oh, no. Agent: It is 7:50 pm, right? User: Two tickets for 7:15 pm, please. Agent: Okay, I will issue you two tickets for movie Hail Caeser tomorrow 7:15 pm at theater AMC Lowes Oak Tree 6, Seattle. User: Thanks! Agent: Thanks!
25 Extrinsically / Intrinsically motivated RL Extrinsic motivation do sth for specific reward RL is driven by task-specific reward Learning task-specific skills, don t cope flexibly with new problems Intrinsic motivation do sth inherently enjoyable RL is driven by curiosity w/o explicit reward Developing board competence, which makes learning task-specific skill more easily Task Completion Bots InfoBots Social Bots
26 integrated design

27 27
 from the major")


28 This joint paper (2012) from the major speech recognition laboratories details the first major industrial application of deep learning. 28
29 Achieving Human Parity in Conversational Speech Recognition (CNN + LSTM)HMM hybrid attentional layer-wise context expansion LACE spatial smoothing letter trigrams Lowest ASR error rate on SWBD: 5.9% human SR 5.9% 29

30 5 areas of potential new breakthrough 1. better modeling for end-to-end and other specialized architectures capable of disentangling mixed acoustic variability factors (e.g. sequential GAN) 2. better integrated signal processing and neural learning to combat difficult far-field acoustic environments especially with mixed speakers 3. use of neural language understanding to model long-span dependency for semantic and syntactic consistency in speech recognition outputs, use of semantic understanding in spoken dialogue systems to provide feedbacks to make acoustic speech recognition easier 4. use of naturally available multimodal labels such as images, printed text, and handwriting to supplement the current way of providing text labels to synchronize with the corresponding acoustic utterances (NIPS Multimodality Workshop) 5. development of ground-breaking deep unsupervised learning methods for exploitation of potentially unlimited amounts of naturally found acoustic data of speech without the otherwise prohibitively high cost of labeling based on the current deep supervised learning paradigm
31
32
33 Speech-based vs text-based Errors in speech recog treated as noise in text as input to text-based bots Solving robustness: huge opportunity for integrated design
34
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE. Junior Year. Summer (Bridge Quarter) Fall Winter Spring GAME Credits.
 Fall Winter Spring GAME Credits.") DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
DIGITAL GAMING & INTERACTIVE MEDIA BACHELOR S DEGREE Sample 2-Year Academic Plan DRAFT Junior Year Summer (Bridge Quarter) Fall Winter Spring MMDP/GAME 124 GAME 310 GAME 318 GAME 330 Introduction to Maya
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition
 Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Segmental Conditional Random Fields with Deep Neural Networks as Acoustic Models for First-Pass Word Recognition Yanzhang He, Eric Fosler-Lussier Department of Computer Science and Engineering The hio
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction
 INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
INTERSPEECH 2015 Robust Speech Recognition using DNN-HMM Acoustic Model Combining Noise-aware training with Spectral Subtraction Akihiro Abe, Kazumasa Yamamoto, Seiichi Nakagawa Department of Computer
AI Agent for Ice Hockey Atari 2600
 AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
AI Agent for Ice Hockey Atari 2600 Emman Kabaghe (emmank@stanford.edu) Rajarshi Roy (rroy@stanford.edu) 1 Introduction In the reinforcement learning (RL) problem an agent autonomously learns a behavior
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
On Human Computer Interaction, HCI. Dr. Saif al Zahir Electrical and Computer Engineering Department UBC
 On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
On Human Computer Interaction, HCI Dr. Saif al Zahir Electrical and Computer Engineering Department UBC Human Computer Interaction HCI HCI is the study of people, computer technology, and the ways these
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
SOFTWARE EVALUATION TOOL
 SOFTWARE EVALUATION TOOL Kyle Higgins Randall Boone University of Nevada Las Vegas rboone@unlv.nevada.edu Higgins@unlv.nevada.edu N.B. This form has not been fully validated and is still in development.
SOFTWARE EVALUATION TOOL Kyle Higgins Randall Boone University of Nevada Las Vegas rboone@unlv.nevada.edu Higgins@unlv.nevada.edu N.B. This form has not been fully validated and is still in development.
College Pricing and Income Inequality
 College Pricing and Income Inequality Zhifeng Cai U of Minnesota, Rutgers University, and FRB Minneapolis Jonathan Heathcote FRB Minneapolis NBER Income Distribution, July 20, 2017 The views expressed
College Pricing and Income Inequality Zhifeng Cai U of Minnesota, Rutgers University, and FRB Minneapolis Jonathan Heathcote FRB Minneapolis NBER Income Distribution, July 20, 2017 The views expressed
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Grammar Lesson Plan: Yes/No Questions with No Overt Auxiliary Verbs
 Grammar Lesson Plan: Yes/No Questions with No Overt Auxiliary Verbs DIALOGUE: Hi Armando. Did you get a new job? No, not yet. Are you still looking? Yes, I am. Have you had any interviews? Yes. At the
Grammar Lesson Plan: Yes/No Questions with No Overt Auxiliary Verbs DIALOGUE: Hi Armando. Did you get a new job? No, not yet. Are you still looking? Yes, I am. Have you had any interviews? Yes. At the
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Deep Neural Network Language Models
 Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Deep Neural Network Language Models Ebru Arısoy, Tara N. Sainath, Brian Kingsbury, Bhuvana Ramabhadran IBM T.J. Watson Research Center Yorktown Heights, NY, 10598, USA {earisoy, tsainath, bedk, bhuvana}@us.ibm.com
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling
 Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
November 17, 2017 ARIZONA STATE UNIVERSITY. ADDENDUM 3 RFP Digital Integrated Enrollment Support for Students
 November 17, 2017 ARIZONA STATE UNIVERSITY ADDENDUM 3 RFP 331801 Digital Integrated Enrollment Support for Students Please note the following answers to questions that were asked prior to the deadline
November 17, 2017 ARIZONA STATE UNIVERSITY ADDENDUM 3 RFP 331801 Digital Integrated Enrollment Support for Students Please note the following answers to questions that were asked prior to the deadline
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
A Review: Speech Recognition with Deep Learning Methods
 Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Available Online at www.ijcsmc.com International Journal of Computer Science and Mobile Computing A Monthly Journal of Computer Science and Information Technology IJCSMC, Vol. 4, Issue. 5, May 2015, pg.1017
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners
 Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
Teachable Robots: Understanding Human Teaching Behavior to Build More Effective Robot Learners Andrea L. Thomaz and Cynthia Breazeal Abstract While Reinforcement Learning (RL) is not traditionally designed
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
College Pricing and Income Inequality
 College Pricing and Income Inequality Zhifeng Cai U of Minnesota and FRB Minneapolis Jonathan Heathcote FRB Minneapolis OSU, November 15 2016 The views expressed herein are those of the authors and not
College Pricing and Income Inequality Zhifeng Cai U of Minnesota and FRB Minneapolis Jonathan Heathcote FRB Minneapolis OSU, November 15 2016 The views expressed herein are those of the authors and not
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Top US Tech Talent for the Top China Tech Company
 THE FALL 2017 US RECRUITING TOUR Top US Tech Talent for the Top China Tech Company INTERVIEWS IN 7 CITIES Tour Schedule CITY Boston, MA New York, NY Pittsburgh, PA Urbana-Champaign, IL Ann Arbor, MI Los
THE FALL 2017 US RECRUITING TOUR Top US Tech Talent for the Top China Tech Company INTERVIEWS IN 7 CITIES Tour Schedule CITY Boston, MA New York, NY Pittsburgh, PA Urbana-Champaign, IL Ann Arbor, MI Los
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
10 Tips For Using Your Ipad as An AAC Device. A practical guide for parents and professionals
 10 Tips For Using Your Ipad as An AAC Device A practical guide for parents and professionals Introduction The ipad continues to provide innovative ways to make communication and language skill development
10 Tips For Using Your Ipad as An AAC Device A practical guide for parents and professionals Introduction The ipad continues to provide innovative ways to make communication and language skill development
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT
 INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
INVESTIGATION OF UNSUPERVISED ADAPTATION OF DNN ACOUSTIC MODELS WITH FILTER BANK INPUT Takuya Yoshioka,, Anton Ragni, Mark J. F. Gales Cambridge University Engineering Department, Cambridge, UK NTT Communication
Degeneracy results in canalisation of language structure: A computational model of word learning
 Degeneracy results in canalisation of language structure: A computational model of word learning Padraic Monaghan (p.monaghan@lancaster.ac.uk) Department of Psychology, Lancaster University Lancaster LA1
Degeneracy results in canalisation of language structure: A computational model of word learning Padraic Monaghan (p.monaghan@lancaster.ac.uk) Department of Psychology, Lancaster University Lancaster LA1
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Applications of memory-based natural language processing
 Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Applications of memory-based natural language processing Antal van den Bosch and Roser Morante ILK Research Group Tilburg University Prague, June 24, 2007 Current ILK members Principal investigator: Antal
Five Challenges for the Collaborative Classroom and How to Solve Them
 An white paper sponsored by ELMO Five Challenges for the Collaborative Classroom and How to Solve Them CONTENTS 2 Why Create a Collaborative Classroom? 3 Key Challenges to Digital Collaboration 5 How Huddle
An white paper sponsored by ELMO Five Challenges for the Collaborative Classroom and How to Solve Them CONTENTS 2 Why Create a Collaborative Classroom? 3 Key Challenges to Digital Collaboration 5 How Huddle
Android App Development for Beginners
 Description Android App Development for Beginners DEVELOP ANDROID APPLICATIONS Learning basics skills and all you need to know to make successful Android Apps. This course is designed for students who
Description Android App Development for Beginners DEVELOP ANDROID APPLICATIONS Learning basics skills and all you need to know to make successful Android Apps. This course is designed for students who
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Likelihood-Maximizing Beamforming for Robust Hands-Free Speech Recognition Seltzer, M.L.; Raj, B.; Stern, R.M. TR2004-088 December 2004 Abstract
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Automating the E-learning Personalization
 Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
DICTE PLATFORM: AN INPUT TO COLLABORATION AND KNOWLEDGE SHARING
 DICTE PLATFORM: AN INPUT TO COLLABORATION AND KNOWLEDGE SHARING Annalisa Terracina, Stefano Beco ElsagDatamat Spa Via Laurentina, 760, 00143 Rome, Italy Adrian Grenham, Iain Le Duc SciSys Ltd Methuen Park
DICTE PLATFORM: AN INPUT TO COLLABORATION AND KNOWLEDGE SHARING Annalisa Terracina, Stefano Beco ElsagDatamat Spa Via Laurentina, 760, 00143 Rome, Italy Adrian Grenham, Iain Le Duc SciSys Ltd Methuen Park
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
A Game-based Assessment of Children s Choices to Seek Feedback and to Revise
 A Game-based Assessment of Children s Choices to Seek Feedback and to Revise Maria Cutumisu, Kristen P. Blair, Daniel L. Schwartz, Doris B. Chin Stanford Graduate School of Education Please address all
A Game-based Assessment of Children s Choices to Seek Feedback and to Revise Maria Cutumisu, Kristen P. Blair, Daniel L. Schwartz, Doris B. Chin Stanford Graduate School of Education Please address all
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation
 Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
Role of Pausing in Text-to-Speech Synthesis for Simultaneous Interpretation Vivek Kumar Rangarajan Sridhar, John Chen, Srinivas Bangalore, Alistair Conkie AT&T abs - Research 180 Park Avenue, Florham Park,
An Example of an E-learning Solution for an International Curriculum in Manufacturing Strategy
 An Example of an E-learning Solution for an International Curriculum in Manufacturing Strategy Asbjørn ROLSTADÅS Norwegian University of Science and Technology, NO-7491 Trondheim, Norway Tel: +47-73593785;
An Example of an E-learning Solution for an International Curriculum in Manufacturing Strategy Asbjørn ROLSTADÅS Norwegian University of Science and Technology, NO-7491 Trondheim, Norway Tel: +47-73593785;
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
K5 Math Practice. Free Pilot Proposal Jan -Jun Boost Confidence Increase Scores Get Ahead. Studypad, Inc.
 K5 Math Practice Boost Confidence Increase Scores Get Ahead Free Pilot Proposal Jan -Jun 2017 Studypad, Inc. 100 W El Camino Real, Ste 72 Mountain View, CA 94040 Table of Contents I. Splash Math Pilot
K5 Math Practice Boost Confidence Increase Scores Get Ahead Free Pilot Proposal Jan -Jun 2017 Studypad, Inc. 100 W El Camino Real, Ste 72 Mountain View, CA 94040 Table of Contents I. Splash Math Pilot