Bioinformatics II Theoretical Bioinformatics and Machine Learning Part 1. Sepp Hochreiter
|
|
|
- Daniela Barber
- 6 years ago
- Views:
Transcription
1 Bioinformatics II Theoretical Bioinformatics and Machine Learning Part 1 Institute of Bioinformatics Johannes Kepler University, Linz, Austria
2 Course 6 ECTS 4 SWS VO (class) 3 ECTS 2 SWS UE (exercise) Basic Course of Master Bioinformatics Class: Mo 15:30-17:00 (S3 318) and Thu 15:30-17:00 (S3 318) Exercise: Fr 11:00-12:45 (S3 318) VO: final exam (oral if few students subscribe) UE: weekly homework (evaluated) Other Courses of the Masters in Bioinformatics: Struc. BI and Gene Analysis: Fr 08:30-11:00 (SI 048) Infor. Systems: 5./12./ :30-11:45 (S3 047) Exercise: Thu 8:30 10:00 (S3 048) Intro. to R (instead of Math. Modeling I): We 15:30-17:00 (S3 057) Alg. Disc. Meth.: Thu 13:45-15:15 (HS 12) Population Genetics: Thu 10:15-11:45 (S3 318)
3 Outline 1 Introduction 2 Basics of Machine Learning 3 Theoretical Background of Machine Learning 4 Support Vector Machines 5 Error Minimization and Model Selection 6 Neural Networks 7 Bayes Techniques 8 Feature Selection 9 Hidden Markov Models 10 Unsupervised Learning: Projection Methods and Clustering **11 Model Selection **12 Non-parametric methods:decision trees and k-nearest neighbors **13 Graphical Models / Belief networks / Bayes Networks
4 Outline 1 Introduction 2 Basics of Machine Learning 2.1 Machine Learning in Bioinformatics 2.2 Introductory Example 2.3 Supervised and Unsupervised Learning 2.4 Reinforcement Learning 2.5 Feature Extraction, Selection, and Construction 2.6 Parametric vs. Non-Parametric Models 2.7 Generative vs. descriptive Models 2.8 Prior and Domain Knowledge 2.9 Model Selection and Training 2.10 Model Evaluation, Hyperparameter Selection, and Final Model
5 Outline 3 Theoretical Background of Machine Learning Criteria 3.2 Generalization error 3.3 Minimal Risk for a Gaussian Classification Task 3.4 Maximum Likelihood 3.6 Statistical Learning Theory
6 Outline 4 Support Vector Machines 4.1 Support Vector Machines in Bioinformatics 4.2 Linear Separable Problems 4.3 Linear SVM 4.4 Linear SVM for Non-Linear Separable Problems 4.5 Average Error Bounds for SVMs 4.6 nu-svm 4.7 Non-Linear SVM and the Kernel Trick 4.8 Example: Face Recognition 4.9 Multiclass SVM 4.10 Support Vector Regression 4.11 One Class SVM 4.12 Least Square SVM 4.13 Potential Support Vector Machine 4.14 SVM Optimization and SMO 4.15 Designing Kernels for Bioinformatic Applications 4.16 Kernel Principal Component Analysis 4.17 Kernel Discriminant Analysis 4.18 Software
7 Outline 5 Error Minimization and Model Selection 5.1 Search Methods and Evolutionary Approaches 5.2 Gradient Descent 5.3 Step-size Optimization 5.4 Optimization of the Update Direction 5.5 Levenberg-Marquardt Algorithm 5.6 Predictor Corrector Methods for R(w) = Convergence Properties 5.8 On-line Optimization
8 Outline 6 Neural Networks 6.1 Neural Networks in Bioinformatics 6.2 Motivation of Neural Networks 6.3 Linear Neurons and Perceptron 6.4 Multi Layer Perceptron 6.5 Radial Basis Function Networks 6.6 Reccurent Neural Networks
9 Outline 7 Bayes Techniques 7.1 Likelihood, Prior, Posterior, Evidence 7.2 Maximum A Posteriori Approach 7.3 Posterior Approximation 7.4 Error Bars and Confidence Intervals 7.5 Hyper-parameter Selection: Evidence Framework 7.6 Hyper-parameter Selection: Integrate Out 7.7 Model Comparison 7.8 Posterior Sampling
10 Outline 8 Feature Selection 8.1 Feature Selection in Bioinformatics 8.2 Feature Selection Methods 8.3 Microarray Gene Selection Protocol 9 Hidden Markov Models 9.1 Hidden Markov Models in Bioinformatics 9.2 Hidden Markov Model Basics 9.3 Expectation Maximization for HMM: Baum-Welch Algorithm 9.4 Viterby Algorithm 9.5 Input Output Hidden Markov Models 9.6 Factorial Hidden Markov Models 9.7 Memory Input Output Factorial Hidden Markov Models 9.8 Tricks of the Trade 9.9 Profile Hidden Markov Models
11 Outline 10 Unsupervised Learning: Projection Methods and Clustering 10.1 Introduction 10.2 Principal Component Analysis 10.3 Independent Component Analysis 10.4 Factor Analysis 10.5 Projection Pursuit and Multidimensional Scaling 10.6 Clustering
12 Literature ML: Duda, Hart, Stork; Pattern Classification; Wiley & Sons, 2001 NN: C. M. Bishop; Neural Networks for Pattern Recognition, Oxford Univ. Press, 1995 SVM: Schölkopf, Smola; Learning with kernels, MIT Press, 2002 SVM: V. N. Vapnik; Statistical Learning Theory, Wiley & Sons, 1998 Statistics: S. M. Kay; Fundamentals of Statistical Signal Processing, Prent. Hall, 1993 Bayes Nets: M. I. Jordan; Learning in Graphical Models, MIT Press, 1998 ML: T. M. Mitchell; Machine Learning, Mc Graw Hill, 1997 NN: R. M. Neal, Bayesian Learning for Neural Networks, Springer, 1996 Feature Selection: Guyon, Gunn, Nikravesh, Zadeh; Feature Extraction - Foundations and Applications, Springer, 2006 BI: Schölkopf, Tsuda, Vert ; Kernel Methods in Computational Biology, MIT, 2003
13 Chapter 1 Introduction
14 Introduction 1 Introduction part of curriculum master of science in bioinformatics 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation many fields in bioinformatics are based on machine learning - sequencing data: RNA-Seq, copy numbers - microarrays: data preprocessing, gene selection, prediction - DNA data: alternative splicing, nucleosome position, gene regulation methods: neural networks, support vector machines, kernel approaches, projection method, belief networks goals: noise reduction, feature selection, structure extraction, classification / regression, modeling
15 Introduction 1 Introduction Examples: - cancer treatment outcomes / microarrays 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation - classification of novel protein sequences into structural or functional classes - dependencies between DNA markers (SNP - single nucleotide polymorphisms) and diseases (schizophrenia, autism, multiple sclerosis) only the most prominent machine learning techniques Goals: - how to chose appropriate methods from a given pool - understand and evaluate the different approaches - where to obtain and how to use them - adapt and modify standard algorithms
16 Chapter 2 Basics of Machine Learning
17 Basics of Machine Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge deductive: programmer must understand the problem and find a solution and implement it inductive: solution to a problem is found by a machine which learns inductive is data driven: biology, chemistry, biophysics, medicine, and other fields in life sciences possess a huge amount of data learning: automatically finds structures in the data algorithms that automatically improve a solution with more data 2.9 Model Selection 2.10 Model Evaluation
18 Basics of Machine Learning 1 Introduction Machine Learning: 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge classification and regression (prediction) structure extraction (clustering, components) compression (redundancy reduction) visualization filtering (feature selection) data modeling (generative models) 2.9 Model Selection 2.10 Model Evaluation
19 Machine Learning in Bioinformatics 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation gene recognition microarray data: normalization protein structure and function classification alternative splice site recognition prediction of nucleosome positions single nucleotide polymorphism (SNP) and diseases copy numbers and diseases chromatin structure and methylation and diseases
20 Introductionary Example 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge Example from ``Pattern Classification'', Duda, Hart, and Stork, 2001, John Wiley \& Sons, Inc. salmons must be distinguished from sea bass given images automated system to separate fishes in a fish-packing company Given: a set of pictures with known fishes, the training set Goal: in the future, automatically separate images of salmon from images of sea bass, that is generalization 2.9 Model Selection 2.10 Model Evaluation

21 Introductionary Example 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
22 Introductionary Example 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction First step: preprocessing and feature extraction Preprocessing: contrast / brightness correction, segmentation, alignment Features: length of the fish, lightness Length: 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation optimal decision boundary: minimal misclassifications
23 Introductionary Example 1 Introduction Lightness: 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation Different features may be differently suited for the problem Misclassifcations are weighted equally (otherwise new optimal boundary
24 Introductionary Example 1 Introduction Width of the fishes: 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation width may only be suited in combination with other features Hypothesis: Lightness changes with age, width indicates age
25 Introductionary Example 1 Introduction 2 Basics optimal lightness: nonlinear function of the width that is optimal boundary is a nonlinear curve 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation new fish at?, we would guess salmon but system fails: low generalization, one outlier sea bass changed the curve
26 Introductionary Example 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised one sea bass has lightness and width typically for salmon complex boundary curve also catches this outlier and assign surrounding space to sea bass future examples in this region will be wrongly classified 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation decision boundary with high generalization
27 Introductionary Example 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation we selected the features which are best suited bioinformatics applications: number of features is large selecting the best feature by visual inspections is impossible certain cancer type must be chosen from 30,000 human genes feature selection is important: machine selects the features construct new features from the old ones: feature construction question of cost: how expensive is a certain error measurement noise: features classification noise: what errors of human labeling are to expect first example of too complex model overspecialized to training data
28 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation in our fish example an expert characterized the data by labeling them supervised learning : desired output (target) for each object is given unsupervised learning : no desired output per object supervised: error value on each object classification / regression / time series analysis fish example: classification salmon vs. see bass regression predict age of the fish time series prediction growth from past unsupervised: - cumulative error over all objects (entropy, statistical independence, information content, etc.) - probability of model producing the data: likelihood - principal component analysis (PCA), independent component analysis (ICA), factor analysis, projection pursuit, clustering (k-means), mixture models, density estimation, hidden Markov models, belief networks
29 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection projection: representation of objects, down-project feature vectors, PCA: orthogonal maximal data variation components, ICA: statistically mutual independent components, factor analysis: PCA with noise density estimation: density model of observed data clustering: extract clusters regions data accumulation (typical data) clustering and (down-)projection: feature construction, compact representation of the data, non-redundant, noise removal 2.10 Model Evaluation
30 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
31 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation

32 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
33 Supervised and Unsupervised Learning 1 Introduction Isomap: method for down-projecting data 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
34 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
35 Supervised and Unsupervised Learning 3. Basics of Machine Leaning 3.1 Bioinformatics Original: 3.2 Example 3.3 Un-/Supervised 3.4 Reinforcement Mixtures: 3.5 Feature Extract. 3.6 Non-/Parametric 3.7 Generat. / des. 3.8 Prior Knowl. Demixed by ICA: 3.9 Model Selection 3.10 Model Evaluat Error Bounds 3.12 Support Vector Machines SVM / Bioinf Linear Separable Linear SVM Nonli. Sepa Example Software

36 Supervised and Unsupervised Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation

37 Supervised and Unsupervised Learning 1 Introduction ICA: on images 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation

38 Supervised and Unsupervised Learning 1 Introduction ICA: on video components 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
39 Reinforcement Learning 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation Not considered because not relevant for bioinformatics: reinforcement learning: - model produces output sequence - reward or a penalty at sequence end or during the sequence (no target output) neither supervised nor unsupervised learning model: policy learning: world model or value function two learning techniques : direct policy optimization vs. policy / value iteration (world model) exploitation / exploration trade-off: better to learn or to gain reward methods: Q-learning, SARSA, Temporal Difference (TD), Monte Marlo estimation

40 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics our example salmon - sea bass: features must be extracted fmri brain images and EEG measurements: 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation

41 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
42 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation Feature Selection: features are directly measured huge number of features: microarray 30,000 genes other measurements with many features: peptide arrays, protein arrays, mass spectrometry, SNPs many features not related to the task (genes relevant for cancer)
43 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
44 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
45 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
46 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics features without target correlation may be helpful feature with highest target correlation may be a suboptimal selection 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
47 Feature Extraction, Selection, and Construction 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge Feature Construction: combine features to a new features - PCA or ICA - averaging out kernel methods map another space where new features are used example: sequence of amino acids may be presented by - occurrence vector - certain motifs - their similarity to other sequences 2.9 Model Selection 2.10 Model Evaluation
48 Parametric vs. Non-Parametric Models 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation important step in machine learning is to select a model class parametric models: each parameter vector represents a model - neural networks, where the parameter are the synaptic weights - support vector machines learning: paths through the parameter space disadvantages: - different parameterizations of the same function - model complexity and class via the parameters nonparametric models: model is locally constant / superimpositions - k-nearest-neighbor (k is hyperparameter not adjusted) - kernel density estimation - decision tree constant models (rules) must be a priori selected that is hyperparameters must be fixed (k, kernel width, splitting rules)
49 Generative vs. descriptive Models 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised descriptive model: additional description or another representation of the data projection methods (PCA, ICA) 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation generative models: model should produce the distribution observed for the real world data points describing or representing random components which drive the process prior knowledge about the world or desired model predict new states of the data generation process (brain, cell)
50 Prior and Domain Knowledge 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation reasonable distance measures for k-nearest-neighbor construct problem-relevant features extract appropriate features from the raw data bioinformatics: distances based on alignment - string-kernel - Smith-Waterman-kernel - local alignment kernel - motif kernel bioinformatics: secondary structure prediction with recurrent networks 3.7 amino acid period of a helix in the input bioinformatics: knowledge about the microarray noise (log-values) bioinformatics: 3D structure prediction of proteins disulfidbonds
51 Model Selection and Training 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation Goal: select model with highest generalization performance, that is with the best performance on future data, from the model class model selection is training is learning model which best explains or approximates the training set remember: salmon vs. sea bass the model which perfectly explains the training data had low generalization performance overfitting : model is fitted (adapted) to special training characteristics - noisy measurements - outliers - labeling errors
52 Model Selection and Training 1 Introduction 2 Basics underfitting : training data cannot be fitted well enough trade-off between underfitting and overfitting 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
53 Model Selection and Training 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection overfitting bounded: model class (k in k-nearest-neighbor, number of units in neural networks, maximal weights, etc.) model class often chosen a priori Sometimes model class can be adjusted during training structural risk minimization model selection parameters may influence the model complexity - nonlinearity of neural networks is increased during training - model selection procedure cannot find complex models hyperparameters: parameters controlling the model complexity 2.10 Model Evaluation
54 Model Evaluation, Hyperparameter Selection, and Final Model 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation how to select the hyperparameters? ( number of features) kernel density estimation (KDE): best hyperparameter (the kernel width) can be computed under certain assumptions n-fold cross-validation for hyperparameter selection: - training set is divided into n parts - n runs where in the i-th run part i is used for test - average error over all runs for all hyperparameter combinations - chose parameter combination with smallest average error cross-validation error approximates generalization error, but - cross validation training sets are overlapping - points from the withhold fold are predicted with the same model so that an outlier would have multiple influence on the result leave-one-out cross validation: only one data point is removed assumption: trainings size is not important (one fold is removed)
55 Model Evaluation, Hyperparameter Selection, and Final Model 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive How to estimate the performance of a model? n-fold cross validation, but - another k-fold cross validation on each training set to select the hyperparameters - also feature selection and feature ranking must be done for each training set, i.e. for each fold well know error: feature selection on all data and then cross-validation - from equal relevant features the ones which are relevant also on the test fold are ranked higher 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation
56 Model Evaluation, Hyperparameter Selection, and Final Model 1 Introduction 2 Basics 2.1 Bioinformatics 2.2 Example 2.3 Un-/Supervised 2.4 Reinforcement 2.5 Feature Extraction 2.6 Non-/Parametric 2.7 Generative descriptive 2.8 Prior Knowledge 2.9 Model Selection 2.10 Model Evaluation Comparing models type I and type II error: - Type I: wrongly detect a difference - Type II: miss a difference methods for testing the performance: - paired t-test: > multiply dividing the data into test and training set > to many type I errors - k-fold cross-validated paired t-test: fewer type I errors than p. t-test - McNemar's test: type I and type II errors well estimated - 5x2CV (5 times two fold cross-validation): comparable to McNemar > two fold: many test points, no overlapping training other criteria: - space and time complexity - above for training and for testing (practical use) - training time oft not relevant (wait a week to make money) - faster test, then averaging over many runs is possible
57 Chapter 3 Theoretical Background of Machine Learning
58 Theoretical Background of Machine Learning Complexity: quality criteria goal for model selection / learning approximations unsupervised learning: Maximum Likelihood concepts: bias and variance, efficient estimator, Fisher information supervised learning considered in an unsupervised framework: error model
59 Theoretical Background of Machine Learning Complexity: does learning from examples help in the future? empirical risk minimization (ERM) complexity is restricted and dynamics fixed learning helps : more training examples improve the model converges to the best model for all future data convergence is fast complexity of a model class: VC-dimension (Vapnik-Chervonenkis) structural risk minimization (SRM): complexity and model quality bounds on the generalization error
60 Model Quality Criteria Complexity: learning equivalent to model selection quality criteria: future data is optimally processed other concepts: visualization, modeling, data compression Kohonen networks: no scalar quality criterion (potential function) advantage quality criteria: - comparison of different models - quality during learning known supervised quality criteria: rate of misclassifications or squared error unsupervised criteria: - likelihood - ratio of between and within cluster distance - independence of the components - information content - expected reconstruction error
61 Generalization Error Complexity: Now: supervised performance of a model on future data: generalization error error on one example: loss or error expected loss: risk or generalization error
62 Definition of the Generalization Error/Risk Complexity: Training set: Label or target value: Simple: and Training set: Matrix notation for training inputs: Vector notation for labels: Matrix notation for training set:
63 Definition of the Generalization Error/Risk Complexity: The loss function quadratic loss: zero-one loss: Generalization error:
64 Definition of the Generalization Error/Risk Complexity: y is a function of x (target function: y = f(x)) plus noise: Now the risk can be computed as
65 Definition of the Generalization Error/Risk Complexity:
66 Definition of the Generalization Error/Risk Complexity: The noise-free case is simplifies to:
67 Empirical Estimation of the Generalization Error Complexity: p(z) is unknown especially p(y x) risk cannot be computed practical applications: approximation of the risk model performance estimation for the user
68 Test Set Complexity: Test set approximation: expectation can be approximated using with test set:
69 Cross-Validation Complexity: not enough data for test set (needed for training) cross-validation Cross-validation folds:
70 Cross-Validation Complexity: n-fold cross-validation (here 5-fold):
71 Cross-Validation Complexity: cross-validation is an almost unbiased estimator for the generalization error: Generalization error on trainings size without one fold l l/n can be estimated by crossvalidation on training data l by n-fold crossvalidation
72 Cross-Validation Complexity: advantage: test examples only once used (better than multiple dividing the data into training and test set) disadvantage: - training sets are overlapping - one fold on same model test examples dependent - these dependencies cv has high variance (one outlier influences all estimates) special case: leave-one-out cross-validation (LOO-CV) - l-fold cross-validation, where each fold is one example - test examples to not use the same model - training sets are maximal overlapping
73 Minimal Risk for a Gaussian Classification Task Complexity: Class y = 1 data points are drawn according to and class y = -1 according to where the Gaussian has density
74 Minimal Risk for a Gaussian Classification Task Complexity: Linear transformations of Gaussians lead to Gaussians
75 Minimal Risk for a Gaussian Classification Task Complexity: probability of observing a point from class y=1 at x: probability of observing a point from class y=-1 at x: Conditional probability: probability of observing a point at x: y is integrated out - here summed out

76 Minimal Risk for a Gaussian Classification Task Complexity: two-dimensional classification task data for each class from a Gaussian (black: class 1, red: class -1) optimal discriminant functions are two hyperbolas
77 Minimal Risk for a Gaussian Classification Task Complexity: Bayes rule for probability of x belonging to class y = 1:
78 Minimal Risk for a Gaussian Classification Task Complexity: Risk: Loss function contributions:
79 Minimal Risk for a Gaussian Classification Task Complexity: Optimal discriminant (see later) function: at each position x take smallest value The minimal risk is

80 Minimal Risk for a Gaussian Classification Task Complexity:
81 Minimal Risk for a Gaussian Classification Task Complexity:
82 Minimal Risk for a Gaussian Classification Task Complexity: discriminant function g: g(x)>0 then x is assigned to y = 1 g(x)<0 then x is assigned to y = -1 classification functions : optimal discriminant functions (minimal risk): or
83 Minimal Risk for a Gaussian Classification Task Complexity: For Gaussians:


84 Minimal Risk for a Gaussian Classification Task Complexity: 1D 3D 2D


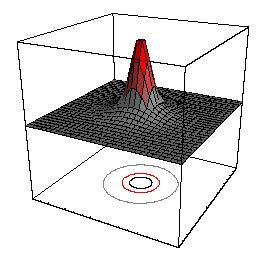
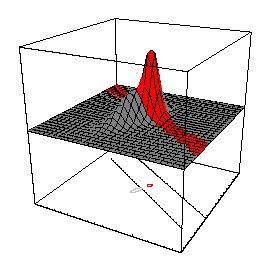
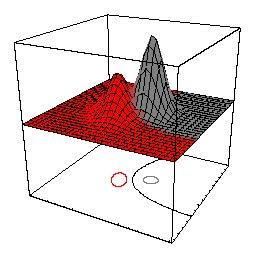
85 Minimal Risk for a Gaussian Classification Task Complexity:
86 Maximum Likelihood Complexity: One of the major objectives if learning generative models It has certain theoretical properties Theoretical concepts like efficient estimator or biased estimator are introduced Even supervised methods can be viewed as special case of maximum likelihood
87 Loss for Unsupervised Learning Complexity: First we consider different loss functions which are used for unsupervised learning Generative approaches maximum likelihood Projection methods Parameter estimation low information loss plus desired property difference of estimated parameter vector to the optimal parameter vector

88 Projection Methods Complexity: data projection into another space with desired requirements
89 Projection Methods Complexity: Principal Component Analysis (PCA): projection to a low dimensional space under maximal information conservation Independent Component Analysis (ICA): projection into a space with statistically indpendent components (factorial code) often characteristics of a factorial distribution are optimized: - maximal entropy (given variance) - cummulants or prototype distributions should be matched: - product of special super-gaussians Projection Pursuit : components are maximally non-gaussian

90 Generative Models Complexity: generative model : model simulates the world and produces the same data as the world
91 Generative Models Complexity: data generation process is probabilistic: underlying distribution generative model attempts at approximation this distribution loss function the distance between model output distribution and the distribution of the data generation process Examples: Factor Analysis, Latent Variable Models, Boltzmann Machines, Hidden Markov Models
92 Parameter Estimation Complexity: parameterized model known task: estimate actual parameters loss: difference between true and estimated parameter evaluate estimator: expected loss
93 Mean Squared Error, Bias, and Variance Complexity: Theoretical concepts of parameter estimation training data: where simply (the matrix of training data) true parameter vector: estimate of :
94 Mean Squared Error, Bias, and Variance Complexity: unbiased estimator: on average (over training set) the true parameter is obtained bias: variance: mean squared error (MSE, different to supervised loss): expected squared error between the estimated and true parameter
95 Mean Squared Error, Bias, and Variance Complexity: Only zero depends on
96 Mean Squared Error, Bias, and Variance Complexity: Averaging reduces variance each of the subsets has examples which gives examples in total Average is where Unbiased: Variance:
97 Mean Squared Error, Bias, and Variance Complexity: averaging: training sets are independent, therefore covariance between them vanishes Minimal Variance Unbiased (MVU) estimator: construct from all unbiased estimators the one with minimal variance MVU estimator does not always exist methods to check whether a given estimator is a MVU
98 Fisher Information Matrix, Cramer-Rao Lower Bound, and Efficiency Complexity: We will find a lower bound for the variance of an unbiased estimator: Cramer-Rao Lower Bound (that is a lower bound for the MSE) We need the Fisher information matrix :
99 Fisher Information Matrix, Cramer-Rao Lower Bound, and Efficiency Complexity: If satisfies then the Fisher information matrix is Fisher information: information of observation about parameter upon which the parameterized density function of depends
100 Fisher Information Matrix, Cramer-Rao Lower Bound, and Efficiency Complexity:
101 Fisher Information Matrix, Cramer-Rao Lower Bound, and Efficiency Complexity: efficient estimator: reaches the CRLB (efficiently uses the data) MVU estimator can be efficient but need not dashed: CRLB
102 Fisher Information Matrix, Cramer-Rao Lower Bound, and Efficiency Complexity: dashed: CRLB
103 Maximum Likelihood Estimator Complexity: MVU estimator is unknown or does not exist Maximum Likelihood Estimator (MLE) MLE can be applied to a broad range of problems MLE approximates the MVU estimator for large data sets MLE is even asymptotically efficient and unbiased MLE does everything right and this efficiently (enough data)
104 Maximum Likelihood Estimator Complexity: The likelihood of the data set : probability of the model to produce the data iid (independent identical distributed) data: Negative log-likelihood:
105 Maximum Likelihood Estimator Complexity: likelihood is based on finite many densities values which have zero measure: problem? assume instead of (region around ) MLE popular: - simple use - properties the volume element
106 Properties of Maximum Likelihood Estimator Complexity: MLE: invariant under parameter change asymptotically unbiased and efficient asymptotically optimal consistent for zero CRLB
107 MLE is Invariant under Parameter Change Complexity:
108 MLE is Asymptotically Unbiased and Efficient Complexity: The maximum likelihood estimator is asymptotically unbiased: The maximum likelihood estimator is asymptotically efficient:
109 MLE is Asymptotically Unbiased and Efficient Complexity:
110 MLE is Asymptotically Unbiased and Efficient Complexity: practical applications: finite examples MLE performance unknown Example: general linear model MLE is which is efficient and MUV Note the noise covariance must be known where
111 MLE is Consistent for Zero CRLB Complexity: consistent: for large training sets the estimator approaches the true value (difference to unbiased variance decreases) Later more formal definition for consistency as Thus, the MLE is consistent if the CRLB is zero
112 Expectation Maximization Complexity: likelihood can be optimized by gradient descent methods likelihood cannot be computed analytically: -- hidden states -- many-to-one output mapping -- non-linearities
113 Expectation Maximization Complexity: hidden variables, latent variables, unobserved variables likelihood is determined by all mapped to
114 Expectation Maximization Complexity: Expectation Maximization (EM) algorithm: -- joint probability is easier to compute than likelihood -- estimate by Jensen's inequality
115 Expectation Maximization Complexity: EM algorithm is an iteration between E -step and M -step:
116 Expectation Maximization Complexity: After E-step: Proof: Kullback-Leibler divergence: Zero for:
117 Expectation Maximization Complexity: EM increases the lower bound in both steps beginning of the M-step: E-step does not change the parameters EM algorithm: -- hidden Markov models -- mixture of Gaussians -- factor analysis -- independent component analysis
118 Noise Models Complexity: connecting unsupervised and supervised learning quality measure noise on the targets apply maximum likelihood
119 Noise Models Complexity: Gaussian target noise linear model log-likelihood:
120 Noise Models Complexity: minimize least square criterion linear least square estimator derivative with respect to : Setting the derivative to zero (Wiener-Hopf equations):
121 Gaussian Noise Complexity: Noise covariance matrix gives the noise for each measure In most cases we have the same noise for each observation: We obtain minimal value: : pseudo inverse or Moore-Penrose inverse
122 Laplace Noise and Minkowski Error Complexity: Laplace noise assumption: More general Minkowski error: gamma function
123 Laplace Noise and Minkowski Error Complexity:
124 Binary Models Complexity: noise considerations do not hold for binary target classification not treated
125 Cross-Entropy Complexity: classification problem with K classes: Likelihood:
126 Cross-Entropy Complexity: The log-likelihood: loss function: cross entropy (Kullback-Leibler)
127 Logistic Regression Complexity: a function g mapping x onto R can be transformed into a probability:
128 Logistic Regression Complexity: If follows: log-likelihood: maximum likelihood maximizes
129 Logistic Regression Complexity: derivative of the log-likelihood: similar to the derivative of the quadratic loss function in the regression: instead of
130 Statistical Learning Theory Complexity: Does learning help for future tasks? Explains a model which explains the training data also new data? Yes, if complexity is bounded VC-dimension as complexity measure statistical learning theory : bounds for the generalization error (future) bounds comprise training error and complexity structural risk minimization minimizes both terms simultaneously
131 Statistical Learning Theory Complexity: statistical learning theory: -- (1) the uniform law of large numbers (empirical risk minimization) -- (2) complexity constrained models (structural risk minimization) error bound on the mean squared error: bias-variance formulation -- bias is training error = empirical risk -- variance is model complexity high complexity more models more solutions large variance
132 Error Bounds for a Gaussian Classification Task Complexity: We revisit the Gaussian classification task
133 Error Bounds for a Gaussian Classification Task Complexity: Gaussian assumption: Chernoff bound: maximizing Bhattacharyya bound: with respect to
134 Empirical Risk Minimization Complexity: empirical risk minimization (ERM) principle states: if the training set is explained by the model then the model generalizes to future examples restrict the complexity of the model class empirical risk minimization (ERM): minimize error on training set
135 Complexity: Finite Number of Functions Complexity intuition why complexity matters complexity is just the number M of functions in model class difference training error (empirical risk) and test error (risk ) empirical risk: finite set of functions worst case (learning chooses unknown function):
136 Complexity: Finite Number of Functions Complexity : union bound distance of average and expectation: Chernoff inequality (for each j ) where is the empirical mean of the true value for trials we obtain complexity term
137 Complexity: Finite Number of Functions Complexity
138 Complexity: Finite Number of Functions Complexity should converge to zero as l increases, therefore
139 Complexity: VC-Dimension Complexity we want apply the previous bound for infinite function classes idea: on training set only finite number of functions is different example: all discriminant functions g giving the same classification function sign g(.) parametric models g(.;w) with parameter vector w Does minimizing the parameter on the training set convergence to the best solution with increasing training set? empirical risk minimization (ERM): consistent or not? do we select better models with larger training sets?
140 Complexity: VC-Dimension Complexity parameter which minimizes the empirical risk for l training examples: ERM is consistent if convergence in probability Empirical risk and expected risk converge to minimal risk
141 Complexity: VC-Dimension Complexity
142 Complexity: VC-Dimension Complexity ERM is strictly consistent if for all holds (convergence in probability) Instead of strictly consistent we write consistent maximum likelihood is consistent for a set of densities if
143 Complexity: VC-Dimension Complexity Under what conditions is the ERM consistent? New concepts and new capacity measures: -- points to be shattered -- annealed entropy -- entropy (new definition) -- growth function -- VC-dimension Possibilities to label the input data shattering the input data by binary labels complexity of a model class: number different labelings how many points can be shattered

144 Complexity: VC-Dimension Complexity Note, that each x is placed in a circle around its position independent of the other x. Therefore each constellation represents a set with non-zero probability mass.
145 Complexity: VC-Dimension Complexity number of points a function class can shatter: VC-dimension (later) function class shattering coefficient: (# labeling class can shatter) entropy of a function class: annealed entropy of a function class: growth function of a function class: Jensen supremum
146 Complexity: VC-Dimension Complexity ERM fast rate of convergence (exponential convergence):
147 Complexity: VC-Dimension Complexity theorems valid for a given probability measure on the observations probability measure enters the formulas via the expectation
148 Complexity: VC-Dimension Complexity VC (Vapnik-Chervonenkis) dimension for which holds If the maximum does not exists: is the largest integer VC-dimension is the maximum number of vectors that can be shattered by the function class
149 Complexity: VC-Dimension Complexity
150 Complexity: VC-Dimension Complexity function class with finite VC-dim.: consistent and converges fast -- Linear functions in d-dimensional of the input space: -- Nondecreasing nonlinear one-dimensional functions -- Nonlinear one-dimensional functions:
151 Complexity: VC-Dimension Complexity -- Neural Networks: M are the number of units, W is the number of weights, e is the base of the natural logarithm (Baum & Haussler 89, Shawe-Taylor & Anthony 91) inputs restricted to Bartlett & Williamson (1996)
152 Error Bounds Complexity idea of deriving the error bounds: set of distinguishable functions cardinality given by trick of two half-samples and their difference ( symmetrization ): therefore in the following we use 2 l l example used for complexity definition and l for empirical error minimal possible risk:
153 Error Bounds Complexity
154 Error Bounds Complexity complexity measure depend on the ratio The bound above is from Anthony and Bartlett whereas an older bound from Vapnik is complexity term decreases with zero empirical risk then the bound on the risk decreases with Later: expected risk decreases with
155 Error Bounds Complexity bound on the risk bound is similar to the bias-variance formulation -- bias corresponds to empirical risk -- variance corresponds to complexity
156 Error Bounds Complexity In many practical cases the bound is not useful: not tight However in many practical cases the minimum of the bound is close to the minimum of the test error
157 Error Bounds Complexity regression: instead of the shattering coefficient covering number ( covering of the functions with distance epsilon) growth function is then: bounds on the generalization error: where
158 Structural Risk Minimization Complexity The Structural Risk Minimization (SRM) principle minimizes the guaranteed risk that is a bound on the risk instead of the empirical risk alone
159 Structural Risk Minimization Complexity nested set of function classes: where class possesses VC-dimension and
160 Structural Risk Minimization Complexity Example for SRM: minimum description length - sender transmits a model (once) and the inputs and errors - receiver has to recover the labels goal: minimize transmission costs (description length) Is the SRM principle consistent? SRM is consistent!! asymptotic rate of convergence: where How fast does it converge? is the minimal risk of the function class
161 Structural Risk Minimization Complexity If the optimal solution belongs to some class convergence rate is then the
162 Margin as Complexity Measure Complexity VC-dimension: restrictions on the class of function most famous: zero isoline of the discriminant function has minimal distance (margin) to all training data points which are contained in a sphere with radius R
163 Margin as Complexity Measure Complexity
164 Margin as Complexity Measure Complexity linear discriminant functions classification function scaling w and b does not change classification function classification function: one representative discriminant function canonical form w.r.t. the training data X:
165 Margin as Complexity Measure Complexity
166 Margin as Complexity Measure Complexity If at least one data point exists for which the discriminant function is positive and at least one data point exists for which it is negative, then we can optimize b and rescale in order to obtain the smallest This gives the tightest bound and smallest VC-dimension After optimizing b and rescaling we have points for which
167 Margin as Complexity Measure Complexity
168 Margin as Complexity Measure Complexity After this optimization: the distance of and to the boundary function is
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Detailed course syllabus
 Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Mathematics. Mathematics
 Mathematics Program Description Successful completion of this major will assure competence in mathematics through differential and integral calculus, providing an adequate background for employment in
Mathematics Program Description Successful completion of this major will assure competence in mathematics through differential and integral calculus, providing an adequate background for employment in
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Edexcel GCSE. Statistics 1389 Paper 1H. June Mark Scheme. Statistics Edexcel GCSE
 Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
AP Calculus AB. Nevada Academic Standards that are assessable at the local level only.
 Calculus AB Priority Keys Aligned with Nevada Standards MA I MI L S MA represents a Major content area. Any concept labeled MA is something of central importance to the entire class/curriculum; it is a
Calculus AB Priority Keys Aligned with Nevada Standards MA I MI L S MA represents a Major content area. Any concept labeled MA is something of central importance to the entire class/curriculum; it is a
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
A Model to Predict 24-Hour Urinary Creatinine Level Using Repeated Measurements
 Virginia Commonwealth University VCU Scholars Compass Theses and Dissertations Graduate School 2006 A Model to Predict 24-Hour Urinary Creatinine Level Using Repeated Measurements Donna S. Kroos Virginia
Virginia Commonwealth University VCU Scholars Compass Theses and Dissertations Graduate School 2006 A Model to Predict 24-Hour Urinary Creatinine Level Using Repeated Measurements Donna S. Kroos Virginia
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
MASTER OF PHILOSOPHY IN STATISTICS
 MASTER OF PHILOSOPHY IN STATISTICS SYLLABUS - 2007-09 ST. JOSEPH S COLLEGE (AUTONOMOUS) (Nationally Reaccredited with A+ Grade / College with Potential for Excellence) TIRUCHIRAPPALLI - 620 002 TAMIL NADU,
MASTER OF PHILOSOPHY IN STATISTICS SYLLABUS - 2007-09 ST. JOSEPH S COLLEGE (AUTONOMOUS) (Nationally Reaccredited with A+ Grade / College with Potential for Excellence) TIRUCHIRAPPALLI - 620 002 TAMIL NADU,
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Multi-Dimensional, Multi-Level, and Multi-Timepoint Item Response Modeling.
 Multi-Dimensional, Multi-Level, and Multi-Timepoint Item Response Modeling. Bengt Muthén & Tihomir Asparouhov In van der Linden, W. J., Handbook of Item Response Theory. Volume One. Models, pp. 527-539.
Multi-Dimensional, Multi-Level, and Multi-Timepoint Item Response Modeling. Bengt Muthén & Tihomir Asparouhov In van der Linden, W. J., Handbook of Item Response Theory. Volume One. Models, pp. 527-539.
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Universityy. The content of
 WORKING PAPER #31 An Evaluation of Empirical Bayes Estimation of Value Added Teacher Performance Measuress Cassandra M. Guarino, Indianaa Universityy Michelle Maxfield, Michigan State Universityy Mark
WORKING PAPER #31 An Evaluation of Empirical Bayes Estimation of Value Added Teacher Performance Measuress Cassandra M. Guarino, Indianaa Universityy Michelle Maxfield, Michigan State Universityy Mark
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
 Math 150 Syllabus Course title and number MATH 150 Term Fall 2017 Class time and location INSTRUCTOR INFORMATION Name Erin K. Fry Phone number Department of Mathematics: 845-3261 e-mail address erinfry@tamu.edu
Math 150 Syllabus Course title and number MATH 150 Term Fall 2017 Class time and location INSTRUCTOR INFORMATION Name Erin K. Fry Phone number Department of Mathematics: 845-3261 e-mail address erinfry@tamu.edu
Digital Fabrication and Aunt Sarah: Enabling Quadratic Explorations via Technology. Michael L. Connell University of Houston - Downtown
 Digital Fabrication and Aunt Sarah: Enabling Quadratic Explorations via Technology Michael L. Connell University of Houston - Downtown Sergei Abramovich State University of New York at Potsdam Introduction
Digital Fabrication and Aunt Sarah: Enabling Quadratic Explorations via Technology Michael L. Connell University of Houston - Downtown Sergei Abramovich State University of New York at Potsdam Introduction
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Mathematics subject curriculum
 Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Mathematics subject curriculum Dette er ei omsetjing av den fastsette læreplanteksten. Læreplanen er fastsett på Nynorsk Established as a Regulation by the Ministry of Education and Research on 24 June
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of EM and Two-Step Cluster Method for Mixed Data: An Application
 International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
An Online Handwriting Recognition System For Turkish
 An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
An Online Handwriting Recognition System For Turkish Esra Vural, Hakan Erdogan, Kemal Oflazer, Berrin Yanikoglu Sabanci University, Tuzla, Istanbul, Turkey 34956 ABSTRACT Despite recent developments in
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING
 BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
BUILDING CONTEXT-DEPENDENT DNN ACOUSTIC MODELS USING KULLBACK-LEIBLER DIVERGENCE-BASED STATE TYING Gábor Gosztolya 1, Tamás Grósz 1, László Tóth 1, David Imseng 2 1 MTA-SZTE Research Group on Artificial
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Mathematics Assessment Plan
 Mathematics Assessment Plan Mission Statement for Academic Unit: Georgia Perimeter College transforms the lives of our students to thrive in a global society. As a diverse, multi campus two year college,
Mathematics Assessment Plan Mission Statement for Academic Unit: Georgia Perimeter College transforms the lives of our students to thrive in a global society. As a diverse, multi campus two year college,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Math 96: Intermediate Algebra in Context
 : Intermediate Algebra in Context Syllabus Spring Quarter 2016 Daily, 9:20 10:30am Instructor: Lauri Lindberg Office Hours@ tutoring: Tutoring Center (CAS-504) 8 9am & 1 2pm daily STEM (Math) Center (RAI-338)
: Intermediate Algebra in Context Syllabus Spring Quarter 2016 Daily, 9:20 10:30am Instructor: Lauri Lindberg Office Hours@ tutoring: Tutoring Center (CAS-504) 8 9am & 1 2pm daily STEM (Math) Center (RAI-338)
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION. Han Shu, I. Lee Hetherington, and James Glass
 BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
BAUM-WELCH TRAINING FOR SEGMENT-BASED SPEECH RECOGNITION Han Shu, I. Lee Hetherington, and James Glass Computer Science and Artificial Intelligence Laboratory Massachusetts Institute of Technology Cambridge,
ABSTRACT. A major goal of human genetics is the discovery and validation of genetic polymorphisms
 ABSTRACT DEODHAR, SUSHAMNA DEODHAR. Using Grammatical Evolution Decision Trees for Detecting Gene-Gene Interactions in Genetic Epidemiology. (Under the direction of Dr. Alison Motsinger-Reif.) A major
ABSTRACT DEODHAR, SUSHAMNA DEODHAR. Using Grammatical Evolution Decision Trees for Detecting Gene-Gene Interactions in Genetic Epidemiology. (Under the direction of Dr. Alison Motsinger-Reif.) A major
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade
 Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade The third grade standards primarily address multiplication and division, which are covered in Math-U-See
Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade The third grade standards primarily address multiplication and division, which are covered in Math-U-See
Honors Mathematics. Introduction and Definition of Honors Mathematics
 Honors Mathematics Introduction and Definition of Honors Mathematics Honors Mathematics courses are intended to be more challenging than standard courses and provide multiple opportunities for students
Honors Mathematics Introduction and Definition of Honors Mathematics Honors Mathematics courses are intended to be more challenging than standard courses and provide multiple opportunities for students