Big Data Analytics Clustering and Classification
|
|
|
- Mark Lester
- 6 years ago
- Views:
Transcription

1 E6893 Big Data Analytics Lecture 4: Big Data Analytics Clustering and Classification Ching-Yung Lin, Ph.D. Adjunct Professor, Dept. of Electrical Engineering and Computer Science September 28th, CY Lin, Columbia University
2 Review Key ML Components of Mahout CY Lin, Columbia University

3 Machine Learning example: using SVM to recognize a Toyota Camry Non-ML Rule 1.Symbol has something like bull s head Rule 2.Big black portion in front of car. Rule 3...???? ML Support Vector Machine Feature Space Positive SVs Negative SVs CY Lin, Columbia University

4 Machine Learning example: using SVM to recognize a Toyota Camry ML Support Vector Machine Positive SVs PCamry > 0.95 Feature Space Negative SVs CY Lin, Columbia University

5 Clustering 5
6 Clustering on feature plane 6
7 Clustering example 7

8 Steps on clustering 8
9 Making initial cluster centers 9
10 K-mean clustering 10

11 HelloWorld clustering scenario result 11
12 Parameters to Mahout k-mean clustering algorithm 12
13 HelloWorld clustering scenario 13
14 HelloWorld Clustering scenario - II 14
15 HelloWorld Clustering scenario - III 15
16 Testing difference distance measures 16
17 Manhattan and Cosine distances 17
18 Tanimoto distance and weighted distance 18

19 Results comparison 19

20 Data preparation in Mahout vectors 20

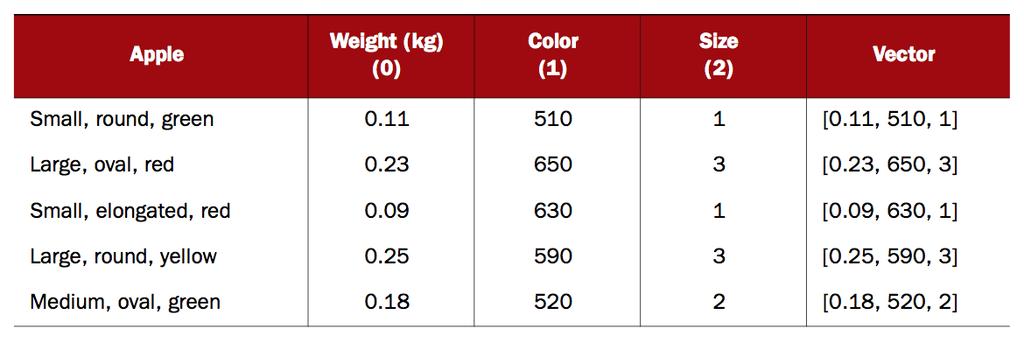
21 vectorization example 0: weight 1: color 2: size 21
22 Mahout codes to create vectors of the apple example 22
23 Mahout codes to create vectors of the apple example II 23
 Stop Words: Stemming:")
24 Vectorization of text Vector Space Model: Term Frequency (TF) Stop Words: Stemming: 24

25 Most Popular Stemming algorithms 25

26 Term Frequency Inverse Document Frequency (TF-IDF) The value of word is reduced more if it is used frequently across all the documents in the dataset. or 26

27 n-gram It was the best of time. it was the worst of times. ==> bigram Mahout provides a log-likelihood test to reduce the dimensions of n-grams 27

28 Examples using a news corpus Reuters dataset: 22 files, each one has 1000 documents except the last one. reuters21578/ Extraction code: 28
29 Mahout dictionary-based vectorizer 29
30 Mahout dictionary-based vectorizer II 30
31 Mahout dictionary-based vectorizer III 31
32 Outputs & Steps 1. Tokenization using Lucene StandardAnalyzer 2. n-gram generation step 3. converts the tokenized documents into vectors using TF 4. count DF and then create TF-IDF 32
33 A practical setting of flags 33
34 normalization Some documents may pop up showing they are similar to all the other documents because it is large. ==> Normalization can help. 34

35 Clustering methods provided by Mahout 35
36 K-mean clustering 36

37 Hadoop k-mean clustering jobs 37

38 K-mean clustering running as MapReduce job 38


39 Hadoop k-mean clustering code 39
40 The output 40

41 Canopy clustering to estimate the number of clusters Tell what size clusters to look for. The algorithm will find the number of clusters that have approximately that size. The algorithm uses two distance thresholds. This method prevents all points close to an already existing canopy from being the center of a new canopy. 41
42 Running canopy clustering Created less than 50 centroids. 42
43 News clustering code 43

44 News clustering example > finding related articles 44
45 News clustering code II 45
46 News clustering code III 46
47 Other clustering algorithms Hierarchical clustering 47
48 Different clustering approaches 48

49 Classification definition 49

50 When to use Mahout for classification? 50
51 The advantage of using Mahout for classification 51
52 How does a classification system work? 52

53 Key terminology for classification 53
54 Input and Output of a classification model 54

55 Four types of values for predictor variables 55

56 Sample data that illustrates all four value types 56

57 Supervised vs. Unsupervised Learning 57

58 Work flow in a typical classification project 58
59 Classification Example 1 Color-Fill 59 Position looks promising, especially the x-axis ==> predictor variable. Shape seems to be irrelevant. Target variable is color-fill label.
60 Classification Example 2 Color-Fill (another feature) 60
61 Mahout classification algorithms Mahout classification algorithms include: Naive Bayesian Complementary Naive Bayesian Stochastic Gradient Descent (SDG) Random Forest 61
62 Comparing two types of Mahout Scalable algorithms 62
63 Step-by-step simple classification example 1.The data and the challenge 2.Training a model to find color-fill: preliminary thinking 3.Choosing a learning algorithm to train the model 4.Improving performance of the classifier 63

64 Choose algorithm via Mahout 64
65 Stochastic Gradient Descent (SGD) 65

66 Characteristic of SGD 66
67 Support Vector Machine (SVM) maximize boundary distances; remembering support vectors 67 nonlinear kernels



68 Naive Bayes Training set: Classifier using Gaussian distribution assumptions: Test Set: 68 ==> female

69 Random Forest Random forest uses a modified tree learning algorithm that selects, at each candidate split in the learning process, a random subset of the features. 69
![Adaboost Example Adaboost [Freund and Schapire 1996] Constructing a strong learner as a linear combination](/docs-images/76/73414090/images/70-0.jpg "of weak learners - Start with a uniform distribution ( weights ) over training examples (The weights tell")

70 Adaboost Example Adaboost [Freund and Schapire 1996] Constructing a strong learner as a linear combination of weak learners - Start with a uniform distribution ( weights ) over training examples (The weights tell the weak learning algorithm which examples are important) - Obtain a weak classifier from the weak learning algorithm, h jt :X {-1,1} - Increase the weights on the training examples that were misclassified - (Repeat) 70
: The final classifier is a linear weighted combination of singlefeature classifiers.")
71 Example User Modeling using Time-Sensitive Adaboost Obtain simple classifier on each feature, e.g., setting threshold on parameters, or binary inference on input parameters. The system classify whether a new document is interested by a person via Adaptive Boosting (Adaboost): The final classifier is a linear weighted combination of singlefeature classifiers. Given the single-feature simple classifiers, assigning weights on the training samples based on whether a sample is correctly or mistakenly classified. <== Boosting. Classifiers are considered sequentially. The selected weights in previous considered classifiers will affect the weights to be selected in the remaining classifiers. <== Adaptive. According to the summed errors of each simple classifier, assign a weight to it. The final classifier is then the weighted linear combination of these simple classifiers. Our new Time-Sensitive Adaboost algorithm: In the AdaBoost algorithm, all samples are regarded equally important at the beginning of the learning process We propose a time-adaptive AdaBoost algorithm that assigns larger weights to the latest training samples People select apples according to their shapes, sizes, other people s interest, etc. Each attribute is a simple classifier used in Adaboost. 71
72 Time-Sensitive Adaboost [Song et al. 2005] 72
: 1 perfect 0")

73 Evaluate the model AUC (0 ~ 1): 1 perfect 0 perfectly wrong 0.5 random confusion matrix 73
74 Average Precision commonly used in sorted results Average Precision is the metric that is used for evaluating sorted results. commonly used for search & retrieval, anomaly detection, etc. Average Precision = average of the precision values of all correct answers up to them, ==> i.e., calculating the precision value up to the Top n correct answers. Average all Pn CY Lin, Columbia University
75 Confusion Matrix 75 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms 2017 CY Lin, Columbia University
76 See Training Results 76 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms

77 Number of Training Examples vs Accuracy 77 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms 2017 CY Lin, Columbia University

78 Classifiers that go bad 78 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms 2017 CY Lin, Columbia University
79 Target leak A target leak is a bug that involves unintentionally providing data about the target variable in the section of the predictor variables. Don t confused with intentionally including the target variable in the record of a training example. Target leaks can seriously affect the accuracy of the classification system. 79
80 Example: Target Leak 80 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms 2017 CY Lin, Columbia University
81 Avoid Target Leaks 81 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms 2017 CY Lin, Columbia University
82 Avoid Target Leaks II 82 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms 2017 CY Lin, Columbia University
83 Imperfect Learning for Autonomous Concept Modeling Learning Reference: C.-Y. Lin et al., SPIE EI West, CY Lin, Columbia University

84 A solution for the scalability issues at training.. Autonomous Learning of Video Concepts through Imperfect Training Labels: Develop theories and algorithms for supervised concept learning from imperfect annotations -- imperfect learning Develop methodologies to obtain imperfect annotation learning from cross-modality information or web links Develop algorithms and systems to generate concept models novel generalized Multiple-Instance Learning algorithm with Uncertain Labeling Density Autonomous Concept Learning Imperfect Learning Cross-Modality Training CY Lin, Columbia University
85 What is Imperfect Learning? Definitions from Machine Learning Encyclopedia: Supervised learning: a machine learning technique for creating a function from training data. The training data consists of pairs of input objects and desired outputs. The output of the function can be a continuous value (called regression), or can predict a class label of the input object (called classification). Predict the value of the function for any valid input object after having seen only a small number of training examples. The learner has to generalize from the presented data to unseen situations in a "reasonable" way. Unsupervised learning: a method of machine learning where a model is fit to observations. It is distinguished from supervised learning by the fact that there is no a priori output. A data set of input objects is gathered. Unsupervised learning then typically treats input objects as a set of random variables. A joint density model is then built for the data set. Proposed Definition of Imperfect Learning: A supervised learning technique with imperfect training data. The training data consists of pairs of input objects and desired outputs. There may be error or noise in the desired output of training data. The input objects are typically treated as a set of random variables CY Lin, Columbia University
86 Why do we need Imperfect Learning? Annotation is a Must for Supervised Learning. All (or almost all?) modeling/fusion techniques in our group used annotation for training However, annotation is time- and cost- consuming. Previous focuses were on improving the annotation efficiency minimum GUI interaction, template matching, active learning, etc. Is there a way to avoid annotation? Use imperfect training examples that are obtained automatically/unsupervisedly from other learning machine(s). These machines can be built based on other modalities or prior machines on related dataset domain. Autonomous Concept Learning Imperfect Learning Cross-Modality Training [Lin 03] CY Lin, Columbia University
87 Proposition Supervised Learning! Time consuming; Spend a lot of time to do the annotation Unsupervised continuous learning! When will it beat the supervised learning? accuracy of Testing Model accuracy of Training Data # of Training Data CY Lin, Columbia University
88 The key objective of this paper can concept models be learned from imperfect labeling? Example: The effect of imperfect labeling on classifiers (left -> right: perfect labeling, imperfect labeling, error classification area) CY Lin, Columbia University
89 False positive Imperfect Learning Assume we have ten positive examples and ten negative examples. if 1 positive example is wrong (false positive), how will it affect SVM? Will the system break down? Will the accuracy decrease significantly? If the ratio change, how is the result? Does it depend on the testing set? If time goes by and we have more and more training data, how will it affect? In what circumstance, the effect of false positive will decrease? In what situation, the effect of false positive will still be there? Assume the distribution of features of testing data is similar to the training data. When will it CY Lin, Columbia University
90 Imperfect Learning If learning example is not perfect, what will be the result? If you teach something wrong, what will be the consequence? Case 1: False positive only Case 2: False positive and false negative Case 3: Learning example has confidence value CY Lin, Columbia University
91 From Hessienberg s Uncertainty Theory From Hessienberg s Uncertainty Theory, everything is random. It is not measurable. Thus, we can assume a random distribution of positive ones and negative ones. Assume there are two Gaussians in the feature space. One is positive. The other one is negative. Let s assume two situations. The first one: every positive is from positive and every negative is from negative. The second one: there may be some random mistake in the negative. Also, let s assume two cases. 1. There are overlap between two Gaussians. 2. There are not. So, maybe these can be derived to become a variable based on mean and sigma. If the training samples of SVM are random, how will be the result? Is it predictable with a closed mathematical form? How about using linear example in the beginning and then use the random examples next? CY Lin, Columbia University
92 False Positive Samples Will false positive examples become support vectors? Very likely. We can also assume a r.v. here. Maybe we can also using partially right data Having more weighting on positive ones. Then for the uncertain ones having fewer chance to become support vector Will it work if, when support vector is picked, we take the uncertainty as a probability? Or, should we compare it to other support vectors? This can be an interesting issue. It s like human brain. The first one you learn, you remember it. The later ones you may forget about it. The more you learn the more it will be picked. The fewer it happens, it will be more easily forgotten. Maybe I can even develop a theory to simulate human memory. Uncertainty can be a time function. Also, maybe the importance of support vector can be a time function. So, sometimes machine will forget things.! This make it possible to adapt and adjustable to outside environment. Maybe I can develop a theory of continuous learning Or, continuous learning based on imperfect memory In this way, the learning machine will be affected mostly by the current data. For those old data, it will put less weighting! may reflect on the distance function. Our goal is to have a very large training set. Remember a lot of things. So, we need to learn to forget CY Lin, Columbia University
93 Imperfect Learning: theoretical feasibility Imperfect learning can be modeled as the issue of noisy training samples on supervised learning. Learnability of concept classifiers can be determined by probably approximation classifier (pac-learnability) theorem. Given a set of fixed type classifiers, the pac-learnability identifies a minimum bound of the number of training samples required for a fixed performance request. If there is noise on the training samples, the above mentioned minimum bound can be modified to reflect this situation. The ratio of required sample is independent of the requirement of classifier performance. Observations: practical simulations using SVM training and detection also verify this theorem. A figure of theoretical requirement of the number of sample needed for noisy and perfect training samples CY Lin, Columbia University
94 PAC-identifiable PAC-identifiable: PAC stands for probably approximate correct. Roughly, it tells us a class of concepts C (defined over an input space with examples of size N) is PAC learnable by a learning algorithm L, if for arbitrary small δ and ε, and for all concepts c in C, and for all distributions D over the input space, there is a 1-δ probability that the hypothesis h selected from space H by learning algorithm L is approximately correct (has error less than ε). Pr (Pr ( h ( x ) c D X ( x )) ε ) δ Based on the PAC learnability, assume we have m independent examples. Then, for a given hypothesis, the probability that m examples have not been misclassified is (1-e) m which we want to be less than δ. In other words, we want (1-e) m <= δ. Since for any 0 <= x <1, (1-x) <= e -x, we then have: 1 1 m ln( ) ε δ CY Lin, Columbia University
95 Sample Size v.s. VC dimension Theorem 2 Let C be a nontrivial, well-behaved concept class. If the VC dimension of C is d, where d <, then for 0 < e < 1 and 4 2 8d 13 m max( log 2, log 2 ) ε δ ε ε any consistent function A: ScC is a learning function for C, and, for 0 < e < 1/2, m has to be larger than or equal to a lower bound, 1 ε 1 m max ln( ), d (1 2 ε (1 δ ) + 2 δ )) ε δ For any m smaller than the lower bound, there is no function A: ScH, for any hypothesis space H, is a learning function for C. The sample space of C, denoted SC, is the set of all CY Lin, Columbia University
96 How many training samples are required? Examples of training samples required in different error bounds for PAC-identifiable hypothesis. This figure shows the upper bounds and lower bounds at Theorem 2. The upper bound is usually refereed as sample capacity, which guarantees the learnability of training samples CY Lin, Columbia University
97 Noisy Samples Theorem 4 Let h < 1/2 be the rate of classification noise and N the number of rules in the class C. Assume 0 < e, h < 1/2. Then the number of examples, m, required is at least and at most m ln(2 δ ) max,log 2 N (1 2 ε (1 δ ) + 2 δ )) ln(1 ε (1 2 η)) ln( N / δ ) ε 1 2 (1 exp( 2 (1 2 η) )) r is the ratio of the required noisy training samples v.s. the noise-free training samples r η = (1 exp( (1 2 η) )) CY Lin, Columbia University
98 Training samples required when learning from noisy examples Ratio of the training samples required to achieve PAC-learnability under the noisy and noise-free sampling environments. This ratio is consistent on different error bounds and VC dimensions of PAC-learnable hypothesis CY Lin, Columbia University
99 Learning from Noisy Examples on SVM For an SVM, we can find the bounded VC dimension: d Λ R + n min( 1, 1) CY Lin, Columbia University
100 Experiments - 1 Examples of the effect of noisy training examples on the model accuracy. Three rounds of testing results are shown in this figure. We can see that model performance does not have significant decrease if the noise probability in the training samples is larger than 60% - 70%. And, we also see the reverse effect of the training samples if the mislabeling probability is larger than CY Lin, Columbia University
101 Experiments 2: Experiments of the effect of noisy training examples on the visual concept model accuracy. Three rounds of testing results are shown in this figure. We simulated annotation noises by randomly change the positive examples in manual annotations to negatives. Because perfect annotation is not available, accuracy is shown as a relative ratio to the manual annotations in [10]. In this figure, we see the model accuracy is not significantly affected for small noises. A similar drop on the training examples is observed at around 60% - 70% of annotation accuracy (i.e., 30% - 40% of missing annotations) CY Lin, Columbia University
102 Conclusion This paper proves that imperfect learning is possible. In general, the performance of SVM classifiers do not degrade too much if the manual annotation accuracy is larger than about 70%. Continuous Imperfect Learning shall have a great impact in autonomous learning scenarios CY Lin, Columbia University
103 Homework #2 (due October 12th) 1. Recommendation: 1-1. Choose any two datasets you can get from any public data set Try various recommendation algorithms provided by Mahout or Spark 2. Clustering: Using datasets from: 1. Online news (e.g., New York Times article in September 2017, or other data sources) 2. Wikipedia articles 3. (optional) gather data from Twitter API, try clustering Do clustering > finding related documents 3. Classification: 3-1: Using two datasets to be provided by TA, try various classification algorithms provided by Mahout or Spark, and discuss their performance 3-2: Do similar experiments on the Wikipedia data that you downloaded. 103 E6893 Big Data Analytics Lecture 5: Big Data Analytics Algorithms
104 Questions? CY Lin, Columbia University
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE. Mingon Kang, PhD Computer Science, Kennesaw State University
 CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE Mingon Kang, PhD Computer Science, Kennesaw State University Self Introduction Mingon Kang, PhD Homepage: http://ksuweb.kennesaw.edu/~mkang9
CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE Mingon Kang, PhD Computer Science, Kennesaw State University Self Introduction Mingon Kang, PhD Homepage: http://ksuweb.kennesaw.edu/~mkang9
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
UMass at TDT Similarity functions 1. BASIC SYSTEM Detection algorithms. set globally and apply to all clusters.
 UMass at TDT James Allan, Victor Lavrenko, David Frey, and Vikas Khandelwal Center for Intelligent Information Retrieval Department of Computer Science University of Massachusetts Amherst, MA 3 We spent
UMass at TDT James Allan, Victor Lavrenko, David Frey, and Vikas Khandelwal Center for Intelligent Information Retrieval Department of Computer Science University of Massachusetts Amherst, MA 3 We spent
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio
 SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
arxiv:cmp-lg/ v1 22 Aug 1994
 arxiv:cmp-lg/94080v 22 Aug 994 DISTRIBUTIONAL CLUSTERING OF ENGLISH WORDS Fernando Pereira AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974 pereira@research.att.com Abstract We describe and
arxiv:cmp-lg/94080v 22 Aug 994 DISTRIBUTIONAL CLUSTERING OF ENGLISH WORDS Fernando Pereira AT&T Bell Laboratories 600 Mountain Ave. Murray Hill, NJ 07974 pereira@research.att.com Abstract We describe and
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Managerial Decision Making
 Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Course Business Managerial Decision Making Session 4 Conditional Probability & Bayesian Updating Surveys in the future... attempt to participate is the important thing Work-load goals Average 6-7 hours,
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011
 Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
HLTCOE at TREC 2013: Temporal Summarization
 HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
AUTOMATED TROUBLESHOOTING OF MOBILE NETWORKS USING BAYESIAN NETWORKS
 AUTOMATED TROUBLESHOOTING OF MOBILE NETWORKS USING BAYESIAN NETWORKS R.Barco 1, R.Guerrero 2, G.Hylander 2, L.Nielsen 3, M.Partanen 2, S.Patel 4 1 Dpt. Ingeniería de Comunicaciones. Universidad de Málaga.
AUTOMATED TROUBLESHOOTING OF MOBILE NETWORKS USING BAYESIAN NETWORKS R.Barco 1, R.Guerrero 2, G.Hylander 2, L.Nielsen 3, M.Partanen 2, S.Patel 4 1 Dpt. Ingeniería de Comunicaciones. Universidad de Málaga.
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Activities, Exercises, Assignments Copyright 2009 Cem Kaner 1
 Patterns of activities, iti exercises and assignments Workshop on Teaching Software Testing January 31, 2009 Cem Kaner, J.D., Ph.D. kaner@kaner.com Professor of Software Engineering Florida Institute of
Patterns of activities, iti exercises and assignments Workshop on Teaching Software Testing January 31, 2009 Cem Kaner, J.D., Ph.D. kaner@kaner.com Professor of Software Engineering Florida Institute of
Stacks Teacher notes. Activity description. Suitability. Time. AMP resources. Equipment. Key mathematical language. Key processes
 Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
ECE-492 SENIOR ADVANCED DESIGN PROJECT
 ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Mathematics process categories
 Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
The Role of String Similarity Metrics in Ontology Alignment
 The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
The Importance of Social Network Structure in the Open Source Software Developer Community
 The Importance of Social Network Structure in the Open Source Software Developer Community Matthew Van Antwerp Department of Computer Science and Engineering University of Notre Dame Notre Dame, IN 46556
The Importance of Social Network Structure in the Open Source Software Developer Community Matthew Van Antwerp Department of Computer Science and Engineering University of Notre Dame Notre Dame, IN 46556
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition
 Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition Tom Y. Ouyang * MIT CSAIL ouyang@csail.mit.edu Yang Li Google Research yangli@acm.org ABSTRACT Personal
Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition Tom Y. Ouyang * MIT CSAIL ouyang@csail.mit.edu Yang Li Google Research yangli@acm.org ABSTRACT Personal
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
CS 1103 Computer Science I Honors. Fall Instructor Muller. Syllabus
 CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence
 Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation
 Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Purdue Data Summit Communication of Big Data Analytics. New SAT Predictive Validity Case Study
 Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Visit us at:
 White Paper Integrating Six Sigma and Software Testing Process for Removal of Wastage & Optimizing Resource Utilization 24 October 2013 With resources working for extended hours and in a pressurized environment,
White Paper Integrating Six Sigma and Software Testing Process for Removal of Wastage & Optimizing Resource Utilization 24 October 2013 With resources working for extended hours and in a pressurized environment,
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial