CLASSIFICATION. CS5604 Information Storage and Retrieval - Fall Virginia Polytechnic Institute and State University. Blacksburg, Virginia 24061
|
|
|
- Constance McGee
- 6 years ago
- Views:
Transcription
1 CLASSIFICATION CS5604 Information Storage and Retrieval - Fall 2016 Virginia Polytechnic Institute and State University Blacksburg, Virginia Professor: E. Fox Presenters: Saurabh Chakravarty, Eric Williamson December 1, 2016
2 TABLE OF CONTENTS Problem Definition High-Level Architecture Data-Retrieval and Processing Classification Experimental Results Conclusion and Future work
3 PROBLEM STATEMENT Given the tweets in the GETAR and IDEAL collections and a set of real world events, determine which tweets belong to each real world event.
4 PROBLEM STATEMENT Tweet Collection 20: hurricane sandy Hurricane Sandy 27: hurricane Hurricane 188: #Arthur Arthur Fairdale 182: #tornado Tornado 632: fairdale 174: #Manhattan Real world event Manhattan Explosion
5 HIGH LEVEL ARCHITECTURE Classification pipeline
6 Training data TRAINING PIPELINE
7 TRAINING PIPELINE Pre-processing (clean/lemmatize/remove stop words) Training data
8 TRAINING PIPELINE Pre-processing (clean/lemmatize/remove stop words) Training data Train word vectors
9 TRAINING PIPELINE Pre-processing (clean/lemmatize/remove stop words) Training data Train word vectors Word2Vec Model
10 TRAINING PIPELINE Pre-processing (clean/lemmatize/remove stop words) Training data Train word vectors Word2Vec Model Train Classifier
11 TRAINING PIPELINE Pre-processing (clean/lemmatize/remove stop words) Training data Train word vectors Word2Vec Model Classifier Model Train Classifier
12 PREDICTION PIPELINE Pre-processing (clean/lemmatize/remove stop words) <<table>> idealcs5604f16 Word2Vec Model Classifier Model
13 PREDICTION PIPELINE Pre-processing (clean/lemmatize/remove stop words) <<table>> idealcs5604f16 Load Word2Vec & Classifier model Word2Vec Model Classifier Model
14 PREDICTION PIPELINE Pre-processing (clean/lemmatize/remove stop words) <<table>> idealcs5604f16 Load Word2Vec & Classifier model Word2Vec Model Classifier Model Predict Tweet Event

15 PREDICTION PIPELINE Pre-processing (clean/lemmatize/remove stop words) <<table>> idealcs5604f16 Load Word2Vec & Classifier model Word2Vec Model Classifier Model Predict Tweet Event
16 DATA RETRIEVAL CHALLENGES Large amounts of data (1.5 billion tweets) Have to avoid serial execution Cannot fit into memory Prevent reprocessing data unnecessarily
17 DATA RETRIEVAL FROM HBASE Retrieval Method Description Smaller collection performance Larger collection performance Spark HadoopRDD Load data into driver and parallelize across the cluster. Seamless reading from HBase. Hangs and does not complete reading on collections > one million. Batch Processing Load one batch at a time onto the drive and parallelize across the cluster. Slower reading due to batch overhead. Allows classification or arbitrarily large collections.
18 CHALLENGES WITH TWEETS Abbreviations and Slang (u,omg) Non English URLs and characters Misspellings A Year After Texas Explosion Federal Repourt Outlines Progress on Fertilize... #meetingprofs
19 TEXT-PREPROCESSING Remove URLs Remove the # characters Lemmatization using StanfordNLP Stopword removal
20 CLEANING EXAMPLE Raw: A Year After Texas Explosion Federal Report Outlines Progress on Fertilize... #meetingprofs Clean: year texas explosion federal report outline progress fertilize meetingprof
21 TRAINING DATA GENERATION Random samples of collections corresponding to real world events. Tweet assigned a number with the class it belongs to most. Hand Labeled 1000 Tweets
22 Number of Tweets CLASS DISTRIBUTION FOR TRAINING AND TEST DATA Class distribution of manually labeled data Class Number Class distribution of manually labeled data
23 TEXT CLASSIFICATION Feature selection Feature representation Choice of classifier
24 A COMPARISON OF FEATURE SELECTION TECHNIQUES Technique Advantages Disadvantages Tf-idf Superior for small feature. High term removal capability. Accuracy suffers for large datasets. Mutual information Simple to implement. Inferior accuracy performance. Association rules Chi-square statistic Within class popularity Word2Vec Fast execution. Very good accuracy for multiclass scenarios. Easy to interpret the rules Robust accuracy and performance with large sample sets with fewer classes. Identifies words that are most discriminative. Captures relationships of a word with neighbors. Prone to discovering too many rules or poorly understandable rules that hurt performance and interpretation. Difficulty in interpretation of when there are a large number of classes. Ignores the sequence of words. High computational complexity. Long training time for large sample size. For more details, please refer the appendix section.
25 COMMON FEATURE REPRESENTATION TECHNIQUES One-hot encoding Bag of words Challenges Large number of dimensions Word relationships with neighbors are not captured
26 WORD2VEC A feature selection technique. Captures the semantic context of a word s relation with neighbors. For more details, refer the appendix.
27 WORD2VEC Similar words are grouped together and closer to one another. Slide courtesy -
28 WORD2VEC Word displacements are relationships between the words.
29 WORD2VEC Slide courtesy -
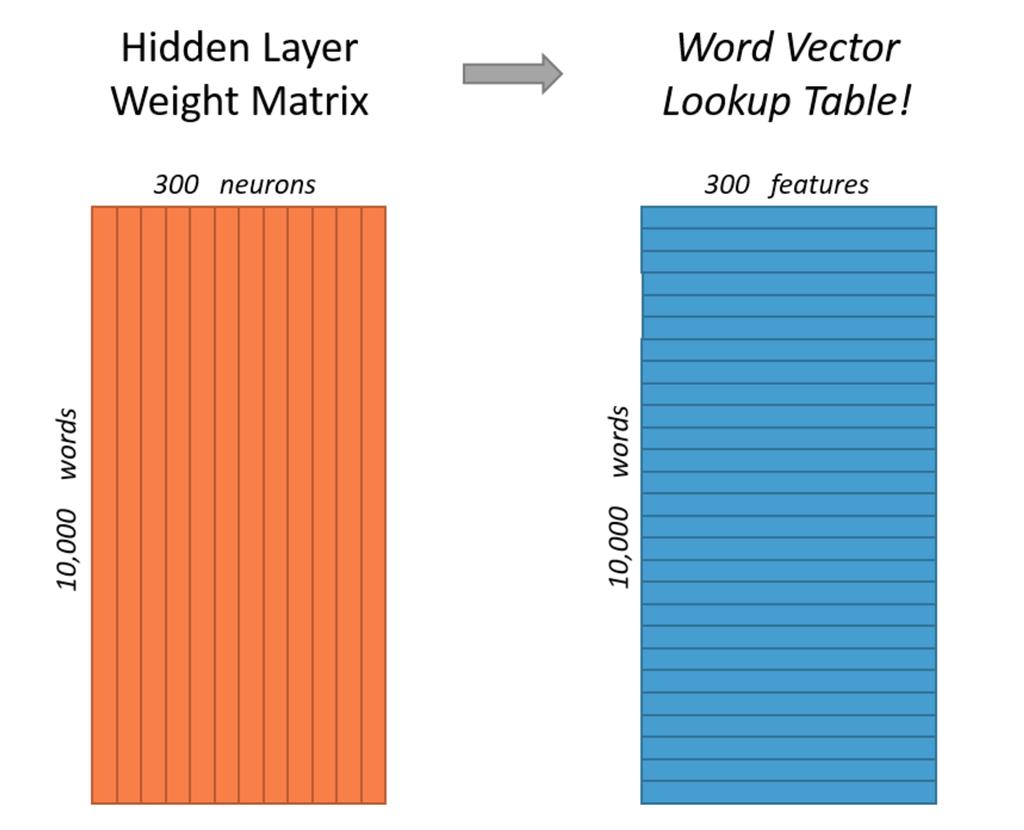
30 WORD2VEC Slide courtesy -
31 CLASSIFIER IMPLEMENTATION DETAILS A word feature is an average of the word vectors generated by the Word2Vec model. We used a vector representation with a default of 100 values. We chose the multi-class logistic regression in the Spark framework to perform classification. The classifier labels the predicted class along with the normalized probabilities of the other classes.
32 EXPERIMENTS Effect of preprocessing Accuracy performance Runtime performance Probability distribution Class assignment
33 CLEANING EXPERIMENT Determine how cleaning the data influences accuracy Cleaning: Lemmatization Stopword removal Hashtag removal Experimental setup: Split hand-labeled data: 70% train 30% test
34 F1 Score CLEANING IMPROVES ACCURACY! Without Cleaning Training and Testing Data With Cleaning Word2Vec with logistic regression Association Rules Word2Vec with logistic regression: 29% fewer misclassifications Association Rules: 51% fewer misclassifications
35 ACCURACY EXPERIMENT Determine which classifier gives better results on labeled data Experimental setup: Generate 10 different breakups of the labeled data Calculate metrics for each classifier on same breakup 9 different classes
36 ACCURACY EXPERIMENTAL SETUP Labeled Data Divided into 10 sets Training Test 7 sets Rotate 3 sets sets Generate 10 different training and test sets
37 WORD2VEC OUTPERFORMS ASSOCIATION RULES Accuracy Comparison Weighted F1 Weighted Precision Weighted Recall Word2Vec With Logistic Regression Association Rules Word2Vec with logistic regression had a 6.7% increase in F1 score over association rules.
38 CLASSIFIER RUNTIME PERFORMANCE Need to be able to handle large collections efficiently to classify all of the tweets Classify at a rate faster than the tweets coming in Allow reruns as more classes are added to the training set
39 Seconds to predict CLASSIFICATION RUNTIME PERFORMANCE 60 Classifier prediction performance ,000 40,000 80, , , ,000 Number of tweets to predict Word2Vec with logistic regression Association Rules
40 OPTIMIZATION Broadcast models to each partition Word2Vec Model Clean Clean HBase Read Partition and distribute Partition 1 Partition 2 Partition 3 Clean Logistic Regression Model Classify Write Classify Write Classify Write
41 Seconds to Predict PROCESSING ACROSS PARTITIONS INCREASES RUNTIME PERFORMANCE! ,000 40,000 80, , , ,000 Number of tweets to predict Word2Vec with logistic regression Association Rules Optimized Word2Vec 57% faster than original Word2Vec 14% faster than Association Rules
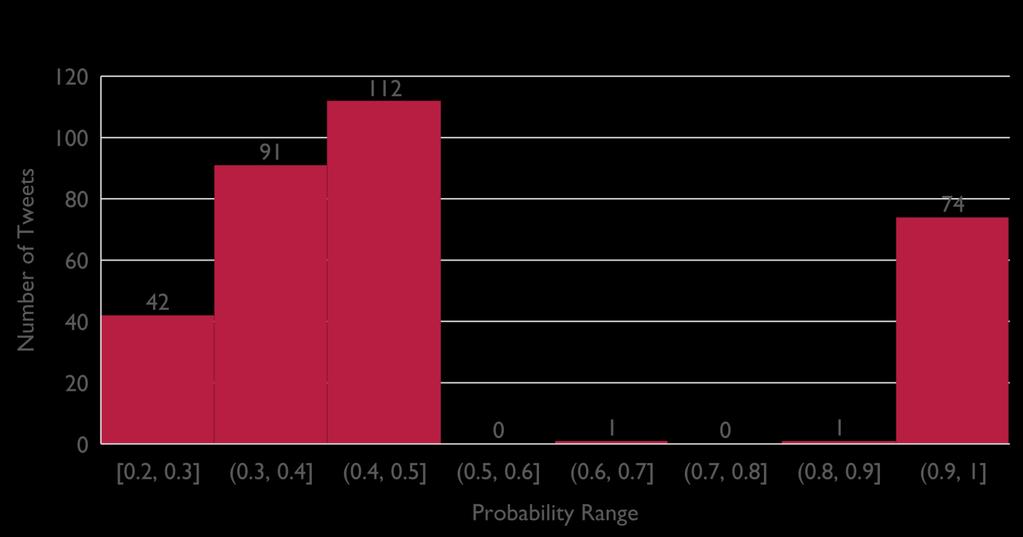
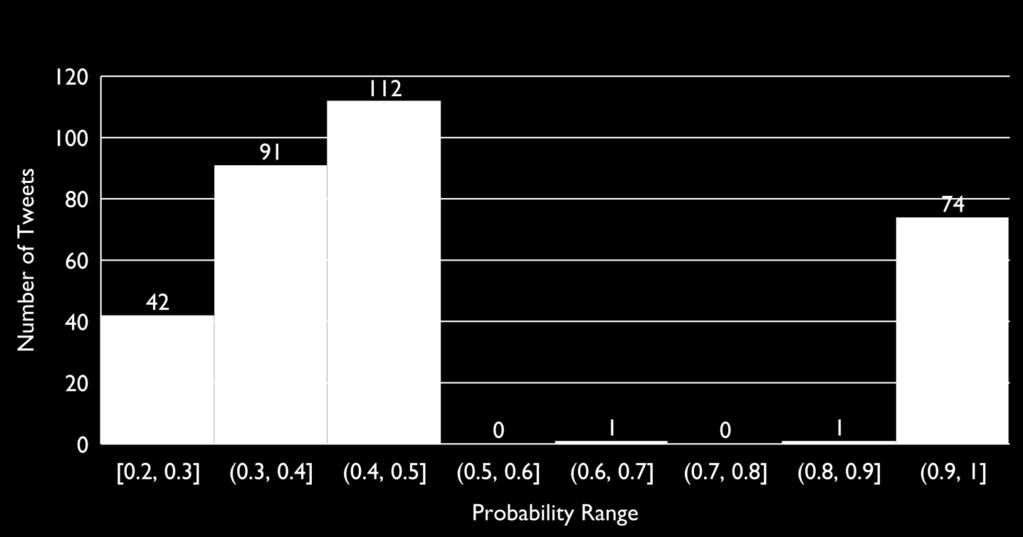
42 PROBABILITY DISTRIBUTION FOR TEST DATA




43 MULTI-CLASS ASSIGNMENT DISTRIBUTION FOR TEST DATA 1 23% 4 13% 3 29% 2 35%
44 CONCLUSION Reading data in blocks from HBase and then partitioning it into parallel tasks results in huge run time performance efficiency and predictability. Cleaning text based on the English usage nuances in the Twitter universe results in better accuracy. Feature selection methods like Word2Vec that capture richer word semantics and context result in better accuracy than traditional ones for text classification. It is natural for a Tweet to be classified in multiple classes and the tradeoff between precision and recall is dependent on the user/product requirements.
45 FUTURE WORK The system can be retrained using a bigger corpus to generate a newer set of word vectors. Training on a text corpus like Google News can help generate word vectors that have richer word relationships encoded within. These can help improve the classification accuracy. The Logistic Regression classifier can be retrained on new classes. The system will be configured to run via a cron job periodically. In addition to classifying a tweet, the system also emits probabilities of all the classes that could be saved in HBase and can be used by SOLR or the front-end team to use as a criterion for customizing the indexing or user experience. Comparisons can be performed with the results of the developed classifier with the AR classifier or a few more classifiers and a inter-classifier agreement analysis can throw further light on the efficacy of the developed classifier.
46 ACKNOWLEDGEMENTS We would like to acknowledge and thank the following for assisting and supporting us throughout this project. Dr. Edward Fox, Dr. Denilson Alves Pereira NSF grant IIS , III: Small: Collaborative Research: Global Event and Trend Archive Research (GETAR) NSF grant IIS , III: Small: Integrated Digital Event Archiving and Library (IDEAL) Digital Library Research Laboratory Graduate Research Assistant Sunshin Lee Other teams in CS 5604
47
48 APPENDIX
49 FEATURE SELECTION TECHNIQUES Technique Advantages Disadvantages Tf-idf Superior for small feature sets that have a large scatter of features among the classes. High term removal capability. Accuracy suffers for large data sets where a term distribution alone does not suffice in class discrimination. Mutual information Simple to implement. Inferior performance in estimation of probabilities because of bias. Association rules Fast execution. Very good accuracy for multi-class scenarios. Rule based classifier helps understand the classification decision easily. Prone to discovering too many rules or poorly understandable rules that hurt performance and interpretation. Chi-square statistic Robust accuracy and performance with large sample sets with fewer classes. Difficulty in interpretation of when there are a large number of classes. Within class popularity Word2Vec Identifies words that are most discriminative. Captures relationships of a word with neighbors. Ignores the sequence of words. High computation complexity. Long training time for large sample size.
50 WORD2VEC Slide courtesy -
51 WORD2VEC Can learn the word vectors via two forms. CBOW Predict the word, given the context. Slide courtesy -
52 WORD2VEC Skip-gram Inverse objective of CBOW. Predict the context, given a word. Slide courtesy -
53 REAL WORLD EVENTS USED FOR EXPERIMENTS The real world event along with the amount of tweets labeled as that class for our experimental sets. Hurricane Sandy (108 tweets) Hurricane Isaac (83 tweets) New York Firefighter Shooting (58 tweets) Kentucky Accidental Child Shooting (16 tweets) Newtown School Shooting (157 tweets) Manhattan Building Explosion (189 tweets) China Factory Explosion (178 tweets) Texas Fertilizer Explosion (120 tweets) Hurricane Arthur (169 tweets)
54 REAL WORLD EVENTS CLASSIFIED The real world events classified along with some collections tweets of that event are found. Real World Event Collections Real World Event Collections Hurricane Sandy 23,27,375 Hurricane Isaac 27,28,375 New York Firefighter Shooting Newtown School Shooting China Factory Explosion 43,46 Kentucky Accidental Child Shooting 41,42,46 Manhattan Building Explosion 231,232 Texas Fertilizer Explosion Hurricane Arthur 27,187,188,375 Quebec Train Derailment 45,46 173,174,399,400 77,381 96,98,381 Fairdale Tornado 406,632 Oklahoma Tornado 406,84 Mississippi Tornado 406,528 Alabama Tornado 406,407
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio
 SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand
 Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Finding Translations in Scanned Book Collections
 Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Finding Translations in Scanned Book Collections Ismet Zeki Yalniz Dept. of Computer Science University of Massachusetts Amherst, MA, 01003 zeki@cs.umass.edu R. Manmatha Dept. of Computer Science University
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2
 1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
1 CROSS-LANGUAGE INFORMATION RETRIEVAL USING PARAFAC2 Peter A. Chew, Brett W. Bader, Ahmed Abdelali Proceedings of the 13 th SIGKDD, 2007 Tiago Luís Outline 2 Cross-Language IR (CLIR) Latent Semantic Analysis
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski
 Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Training a Neural Network to Answer 8th Grade Science Questions Steven Hewitt, An Ju, Katherine Stasaski Problem Statement and Background Given a collection of 8th grade science questions, possible answer
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Using Blackboard.com Software to Reach Beyond the Classroom: Intermediate
 Using Blackboard.com Software to Reach Beyond the Classroom: Intermediate NESA Conference 2007 Presenter: Barbara Dent Educational Technology Training Specialist Thomas Jefferson High School for Science
Using Blackboard.com Software to Reach Beyond the Classroom: Intermediate NESA Conference 2007 Presenter: Barbara Dent Educational Technology Training Specialist Thomas Jefferson High School for Science
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Language Independent Passage Retrieval for Question Answering
 Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
Language Independent Passage Retrieval for Question Answering José Manuel Gómez-Soriano 1, Manuel Montes-y-Gómez 2, Emilio Sanchis-Arnal 1, Luis Villaseñor-Pineda 2, Paolo Rosso 1 1 Polytechnic University
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE. Mingon Kang, PhD Computer Science, Kennesaw State University
 CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE Mingon Kang, PhD Computer Science, Kennesaw State University Self Introduction Mingon Kang, PhD Homepage: http://ksuweb.kennesaw.edu/~mkang9
CS4491/CS 7265 BIG DATA ANALYTICS INTRODUCTION TO THE COURSE Mingon Kang, PhD Computer Science, Kennesaw State University Self Introduction Mingon Kang, PhD Homepage: http://ksuweb.kennesaw.edu/~mkang9
HLTCOE at TREC 2013: Temporal Summarization
 HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
HLTCOE at TREC 2013: Temporal Summarization Tan Xu University of Maryland College Park Paul McNamee Johns Hopkins University HLTCOE Douglas W. Oard University of Maryland College Park Abstract Our team
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Houghton Mifflin Online Assessment System Walkthrough Guide
 Houghton Mifflin Online Assessment System Walkthrough Guide Page 1 Copyright 2007 by Houghton Mifflin Company. All Rights Reserved. No part of this document may be reproduced or transmitted in any form
Houghton Mifflin Online Assessment System Walkthrough Guide Page 1 Copyright 2007 by Houghton Mifflin Company. All Rights Reserved. No part of this document may be reproduced or transmitted in any form
READY TO WORK PROGRAM INSTRUCTOR GUIDE PART I. LESSON TITLE: Precision Measurement Guided Discussion
 READY TO WORK PROGRAM INSTRUCTOR GUIDE PART I LESSON TITLE: Precision Measurement METHOD: Lecture, Guided Discussion EDUCATIONAL OBJECTIVE: Given different precision measurement tool names and drawings,
READY TO WORK PROGRAM INSTRUCTOR GUIDE PART I LESSON TITLE: Precision Measurement METHOD: Lecture, Guided Discussion EDUCATIONAL OBJECTIVE: Given different precision measurement tool names and drawings,
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
As a high-quality international conference in the field
 The New Automated IEEE INFOCOM Review Assignment System Baochun Li and Y. Thomas Hou Abstract In academic conferences, the structure of the review process has always been considered a critical aspect of
The New Automated IEEE INFOCOM Review Assignment System Baochun Li and Y. Thomas Hou Abstract In academic conferences, the structure of the review process has always been considered a critical aspect of
Teaching Architecture Metamodel-First
 Teaching Architecture Metamodel-First George Fairbanks SATURN 2014 7 May 2014 Rhino Research Software Architecture Consulting and Training http://rhinoresearch.com Introduction About me I ve been teaching
Teaching Architecture Metamodel-First George Fairbanks SATURN 2014 7 May 2014 Rhino Research Software Architecture Consulting and Training http://rhinoresearch.com Introduction About me I ve been teaching
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition
 Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition Tom Y. Ouyang * MIT CSAIL ouyang@csail.mit.edu Yang Li Google Research yangli@acm.org ABSTRACT Personal
Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition Tom Y. Ouyang * MIT CSAIL ouyang@csail.mit.edu Yang Li Google Research yangli@acm.org ABSTRACT Personal
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
From Self Hosted to SaaS Our Journey (LEC107648)
") From Self Hosted to SaaS Our Journey (LEC107648) Kathy Saville Director of Instructional Technology Saint Mary s College, Notre Dame Saint Mary s College, Notre Dame, Indiana Founded 1844 Premier Women
From Self Hosted to SaaS Our Journey (LEC107648) Kathy Saville Director of Instructional Technology Saint Mary s College, Notre Dame Saint Mary s College, Notre Dame, Indiana Founded 1844 Premier Women
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Distant Supervised Relation Extraction with Wikipedia and Freebase
 Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Distant Supervised Relation Extraction with Wikipedia and Freebase Marcel Ackermann TU Darmstadt ackermann@tk.informatik.tu-darmstadt.de Abstract In this paper we discuss a new approach to extract relational
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Detecting Online Harassment in Social Networks
 Detecting Online Harassment in Social Networks Completed Research Paper Uwe Bretschneider Martin-Luther-University Halle-Wittenberg Universitätsring 3 D-06108 Halle (Saale) uwe.bretschneider@wiwi.uni-halle.de
Detecting Online Harassment in Social Networks Completed Research Paper Uwe Bretschneider Martin-Luther-University Halle-Wittenberg Universitätsring 3 D-06108 Halle (Saale) uwe.bretschneider@wiwi.uni-halle.de
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C
 Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Term Weighting based on Document Revision History
 Term Weighting based on Document Revision History Sérgio Nunes, Cristina Ribeiro, and Gabriel David INESC Porto, DEI, Faculdade de Engenharia, Universidade do Porto. Rua Dr. Roberto Frias, s/n. 4200-465
Term Weighting based on Document Revision History Sérgio Nunes, Cristina Ribeiro, and Gabriel David INESC Porto, DEI, Faculdade de Engenharia, Universidade do Porto. Rua Dr. Roberto Frias, s/n. 4200-465
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Activities, Exercises, Assignments Copyright 2009 Cem Kaner 1
 Patterns of activities, iti exercises and assignments Workshop on Teaching Software Testing January 31, 2009 Cem Kaner, J.D., Ph.D. kaner@kaner.com Professor of Software Engineering Florida Institute of
Patterns of activities, iti exercises and assignments Workshop on Teaching Software Testing January 31, 2009 Cem Kaner, J.D., Ph.D. kaner@kaner.com Professor of Software Engineering Florida Institute of
On-the-Fly Customization of Automated Essay Scoring
 Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Outreach Connect User Manual
 Outreach Connect A Product of CAA Software, Inc. Outreach Connect User Manual Church Growth Strategies Through Sunday School, Care Groups, & Outreach Involving Members, Guests, & Prospects PREPARED FOR:
Outreach Connect A Product of CAA Software, Inc. Outreach Connect User Manual Church Growth Strategies Through Sunday School, Care Groups, & Outreach Involving Members, Guests, & Prospects PREPARED FOR:
Postprint.
 http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
http://www.diva-portal.org Postprint This is the accepted version of a paper presented at CLEF 2013 Conference and Labs of the Evaluation Forum Information Access Evaluation meets Multilinguality, Multimodality,
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
What is a Mental Model?
 Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
Introduction to Causal Inference. Problem Set 1. Required Problems
 Introduction to Causal Inference Problem Set 1 Professor: Teppei Yamamoto Due Friday, July 15 (at beginning of class) Only the required problems are due on the above date. The optional problems will not
Introduction to Causal Inference Problem Set 1 Professor: Teppei Yamamoto Due Friday, July 15 (at beginning of class) Only the required problems are due on the above date. The optional problems will not
Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter
 ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
ESUKA JEFUL 2017, 8 2: 93 125 Autoencoder and selectional preference Aki-Juhani Kyröläinen, Juhani Luotolahti, Filip Ginter AN AUTOENCODER-BASED NEURAL NETWORK MODEL FOR SELECTIONAL PREFERENCE: EVIDENCE
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Measurement. When Smaller Is Better. Activity:
 Measurement Activity: TEKS: When Smaller Is Better (6.8) Measurement. The student solves application problems involving estimation and measurement of length, area, time, temperature, volume, weight, and
Measurement Activity: TEKS: When Smaller Is Better (6.8) Measurement. The student solves application problems involving estimation and measurement of length, area, time, temperature, volume, weight, and
Schoology Getting Started Guide for Teachers
 Schoology Getting Started Guide for Teachers (Latest Revision: December 2014) Before you start, please go over the Beginner s Guide to Using Schoology. The guide will show you in detail how to accomplish
Schoology Getting Started Guide for Teachers (Latest Revision: December 2014) Before you start, please go over the Beginner s Guide to Using Schoology. The guide will show you in detail how to accomplish
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees
 Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Optimizing to Arbitrary NLP Metrics using Ensemble Selection
 Optimizing to Arbitrary NLP Metrics using Ensemble Selection Art Munson, Claire Cardie, Rich Caruana Department of Computer Science Cornell University Ithaca, NY 14850 {mmunson, cardie, caruana}@cs.cornell.edu
Optimizing to Arbitrary NLP Metrics using Ensemble Selection Art Munson, Claire Cardie, Rich Caruana Department of Computer Science Cornell University Ithaca, NY 14850 {mmunson, cardie, caruana}@cs.cornell.edu
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
A Note on Structuring Employability Skills for Accounting Students
 A Note on Structuring Employability Skills for Accounting Students Jon Warwick and Anna Howard School of Business, London South Bank University Correspondence Address Jon Warwick, School of Business, London
A Note on Structuring Employability Skills for Accounting Students Jon Warwick and Anna Howard School of Business, London South Bank University Correspondence Address Jon Warwick, School of Business, London
Multi-label classification via multi-target regression on data streams
 Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing
 Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing Jan C. Scholtes Tim H.W. van Cann University of Maastricht, Department of Knowledge Engineering.
Improving Machine Learning Input for Automatic Document Classification with Natural Language Processing Jan C. Scholtes Tim H.W. van Cann University of Maastricht, Department of Knowledge Engineering.
Lahore University of Management Sciences. FINN 321 Econometrics Fall Semester 2017
 Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Instructor Syed Zahid Ali Room No. 247 Economics Wing First Floor Office Hours Email szahid@lums.edu.pk Telephone Ext. 8074 Secretary/TA TA Office Hours Course URL (if any) Suraj.lums.edu.pk FINN 321 Econometrics
Alignment of Australian Curriculum Year Levels to the Scope and Sequence of Math-U-See Program
 Alignment of s to the Scope and Sequence of Math-U-See Program This table provides guidance to educators when aligning levels/resources to the Australian Curriculum (AC). The Math-U-See levels do not address
Alignment of s to the Scope and Sequence of Math-U-See Program This table provides guidance to educators when aligning levels/resources to the Australian Curriculum (AC). The Math-U-See levels do not address
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Ryerson University Sociology SOC 483: Advanced Research and Statistics
 Ryerson University Sociology SOC 483: Advanced Research and Statistics Prerequisites: SOC 481 Instructor: Paul S. Moore E-mail: psmoore@ryerson.ca Office: Sociology Department Jorgenson JOR 306 Phone:
Ryerson University Sociology SOC 483: Advanced Research and Statistics Prerequisites: SOC 481 Instructor: Paul S. Moore E-mail: psmoore@ryerson.ca Office: Sociology Department Jorgenson JOR 306 Phone: