Course 395: Machine Learning - Lectures
|
|
|
- Laureen Floyd
- 6 years ago
- Views:
Transcription
1 Course 395: Machine Learning - Lectures Lecture 1-2: Concept Learning (M. Pantic) Lecture 3-4: Decision Trees & CBC Intro (M. Pantic & S. Petridis) Lecture 5-6: Evaluating Hypotheses (S. Petridis) Lecture 7-8: Artificial Neural Networks I (S. Petridis) Lecture 9-10: Artificial Neural Networks II (S. Petridis) Lecture 11-12: Instance Based Learning (M. Pantic) Lecture 13-14: Genetic Algorithms (M. Pantic)
2 Evaluating Hypotheses Lecture Overview Measures of classification performance Classification Error Rate UAR Recall, Precision, Confusion Matrix Imbalanced Datasets Overfitting Cross-validation Estimating hypothesis accuracy Sample Error vs. True Error Confidence Intervals Binomial and Normal Distributions Comparing Learning Algorithms t-test
3 Classification Measures Confusion Matrix : Positive : Negative TP FP FN TN TP: True Positive FN: False Negative FP: False Positive TN: True Negative Visualisation of the performance of an algorithm Allows easy identification of confusion between between classes e.g. one class is commonly mislabelled as the other Most performance measures are computed from the confusion matrix

4 Classification Measures Classification Rate : Positive : Negative TP FP FN TN TP: True Positive FN: False Negative FP: False Positive TN: True Negative Classification Rate / Accuracy: Number of correctly classified examples divided by the total number of examples Classification Error = 1 Classification Rate Classification Rate = Pr(correct classification)
5 Classification Measures Recall : Positive : Negative TP FP FN TN TP: True Positive FN: False Negative FP: False Positive TN: True Negative Recall: Number of correctly classified positive examples divided by the total number of positive examples High recall: The class is correctly recognised (small number of FN) Recall = Pr(correctly classified positive example)
6 Classification Measures Precision Precision: TP FP TP TP + FP FN TN : Positive : Negative TP: True Positive FN: False Negative FP: False Positive TN: True Negative Number of correctly classified positive examples divided by the total number of predicted positive examples High precision: An example labeled as positive is indeed positive (small number of FP) Precision = Pr(positive example example is classified as positive)
7 Classification Measures Recall/Precision : Positive : Negative TP FP FN TN TP: True Positive FN: False Negative FP: False Positive TN: True Negative High recall, low precision: Most of the positive examples are correctly recognised (low FN) but there are a lot of false positives. Low recall, high precision: We miss a lot of positive examples (high FN) but those we predict as positive are indeed positive (low FP).
8 Classification Measures F1 Measure/Score
9 Classification Measures UAR : Positive : Negative TP FP FN TN TP: True Positive FN: False Negative FP: False Positive TN: True Negative We compute recall for class1 (R1) and for class2 (R2). Unweighted Average Recall (UAR) = mean(r1, R2)
10 Classification Measures Extension to Multiple Classes Class 3 TP FN FN FP TN? FP? TN Class 3 In the multiclass case it is still very useful to compute the confusion matrix. We can define one class as positive and the other as negative. We can compute the performance measures in exactly the same way. CR = number of correctly classified examples (trace) divided by the total number of examples. Recall and precision and F1 are still computed for each class. UAR = mean(r1, R2, R3,, RN)
11 Classification Measures Balanced Dataset CR: 80% Recall (cl.1): 70% Precision (cl.1): 87.5% F1 (cl.1): 77.8% UAR: 80% Recall (cl.2): 90% Precision (cl.2): 75% F1 (cl.2): 81.8% Balanced Dataset: The number of examples in each class are similar All measures result in similar performance
12 Classification Measures Imbalanced Dataset Case 1: Both classifiers are good CR: 71.8% Recall (cl.1): 70% Precision (cl.1): 98.6% F1 (cl.1): 81.9% UAR: 80% Recall (cl.2): 90% Precision (cl.2): 23.1% F1 (cl.2): 36.8% Imbalanced Dataset: Classes are not equally represented CR goes down, is affected a lot by the majority class Precision (and F1) for is significantly affected - 30% of class1 examples are misclassified leads to a higher number of FP than TN due to imbalance
13 Classification Measures Imbalanced Dataset Case 2: One classifier is useless CR: 70% Recall (cl.1): 70% Precision (cl.1): 87.5% F1 (cl.1): 77.8% UAR: 35% Recall (cl.2): 0% Precision (cl.2): 0% F1 (cl.2): Not defined CR is misleading, one classifier is useless. F1 for class2 and UAR tell us that something is wrong. UAR also detects that there is a problem.
14 Classification Measures Imbalanced Dataset Conclusions CR can be misleading, simply follows the performance of the majority class UAR is useful and can help to detect that one or more classifiers are not good but it does not give us any information about FP F1 is useful as well but is also affected by the class imbalance problem - We are not sure if the low score is due to one/more classifiers being useless or class imbalance That s why we should always have a look at the confusion matrix
15 Classification Measures Imbalanced Dataset Some solutions Divide by the total number of examples per class Report performance ALSO on the normalised matrix CR: 71.8% Recall (cl.1): 70% Precision (cl.1): 98.6% F1 (cl.1): 81.9% UAR: 80% Recall (cl.2): 90% Precision (cl.2): 23.1% F1 (cl.2): 36.8% CR: 80% Recall (cl.1): 70% Precision (cl.1): 87.5% F1 (cl.1): 77.8% UAR: 80% Recall (cl.2): 90% Precision (cl.2): 75% F1 (cl.2): 81.8%
16 Classification Measures Imbalanced Dataset Some solutions Upsample the minority class Downsample the majority class - e.g. select randomly the same number of examples as the minority class. - Repeat this procedure several times and train a classifier each time with a different training set. - Report the mean and st. dev. of the selected performance measure Japkowicz, Nathalie, and Shaju Stephen. "The class imbalance problem: A systematic study." Intelligent data analysis 6.5 (2002):
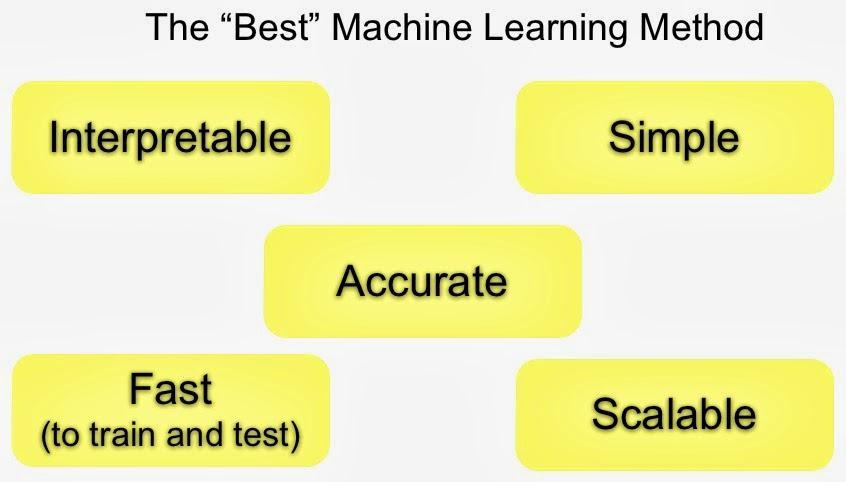
17 It s not all about accuracy
18
19 Training/Validation/Test Sets Split your dataset into 3 disjoint sets: Training, Validation, Test If a lot of data are available then you can try 50:25:25 otherwise 60:20:20. Identify which parameters need to be optimised and select a performance measure to evaluate the performance on the validation set. - e.g. number of hidden neurons - Use F1 as performance measure. It s perfectly fine to use any other measure, depends on your application
20 Training/Validation/Test Sets Train your algorithm on the training set multiple times, each time using different values for the parameters you wish to optimise. For each trained classifier evaluate the performance on the validation set (using the performance measure you have selected).
21 Training/Validation/Test Sets Keep the classifier that leads to the maximum performance on the validation set (in this example the one trained with 35 hidden neurons) This is called parameter optimisation, since you select the set of parameters that have produced the best classifier.
22 Training/Validation/Test Sets Test the performance on the test set. The test set should NOT be used for training or validation. It is used ONLY in the end for estimating the performance on unknown examples, i.e. how well your trained classifiers generalises. You should assume that you do not know the labels of the test set and only after you have trained your classifier they are given to you.
23 Cross Validation Total error estimate: When we have a lot of examples then the division into training/validation/test datasets is sufficient. When we have a small sample size then a good alternative is cross validation.
24 Cross Validation Parameter Optimisation + Test Set Performance Total error estimate: Divide dataset into k (usually 10) folds using k-1 for training+validation and one for testing Test data between different folds should never overlap! Training+Validation and test data in the same iteration should never overlap! In each iteration the error on the left-out test set is estimated Error estimate: average of the k errors
 fold cross-validation on the training+validation folds only in order to optimise the parameters.")
25 Cross Validation Parameter Optimisation + Test Set Performance Test data Validation data k-1 folds Training data Training data Repeat k times n-fold cross validation on k-1 folds only Validation data We can run an n (usually 2-3) fold cross-validation on the training+validation folds only in order to optimise the parameters. Select the parameters that result in the best average performance over all n folds. Then train on the entire training+validation set (k-1 folds) and test on the k fold. Inner cross-validation: Parameter Optimisation Outer cross-validation: Performance evaluation

26 Cross Validation Parameter Optimisation + Test Set Performance S. Marsland, Machine learning: An algorithmic perspective Another simpler way to optimise the parameters is simply to leave a second fold out for validation. Train on the training set, optimise parameters on the validation set and test on the test set.
27 Overfitting Given a hypothesis space H, h H overfits the training data if there exists some alternative hypothesis h H such that h has smaller error than h over the training examples, but h has smaller error than h over the entire distribution of instances. Underfitting Just right Red: error on Test set (unseen examples) Blue: error on Training set Overfitting Overfitting: Small error on training set, but large error on unseen examples. Underfitting: Larger error on training and test sets.
28 Overfitting Green: True target function Red: Training points Blue: What we have learned (overfitting) (by Tomaso Poggio, The algorithm has learned perfectly the training examples, even the noise present in the examples and cannot generalise on unseen examples.
29 Overfitting Overfitting can occur when: Learning is performed for too long (e.g. in Neural Networks). The examples in the training set are not representative of all possible situations. The model we use is too complex.
30 Estimating accuracy of classification measures Q1: What is the best estimate of the accuracy over future examples drawn from the same distribution? - If future examples are drawn from a different distribution then we cannot generalise our conclusions based on the sample we already have. Q2: What is the probable error in this accuracy estimate? We want to assess the confidence that we can have in this classification measure.
31 Sample error & true error The True error of hypothesis h is the probability that it will misclassify a randomly drawn example x from distribution D: error D h Pr f x h x f:true target function The Sample error of hypothesis h based on a data sample S: 1 error S, n h f x h x x S n: number of examples in S δ(f(x),h(x))=1 if f(x) h(x) δ(f(x),h(x))=0 if f(x)=h(x) We want to know the true error but we can only measure the sample error.
32 Sample Set Assumptions We assume that the sample S is drawn at random using the same distribution D from which future examples will be drawn. Drawing an example from D does not influence the probability that another example will be drawn next. Examples are independent of the hypothesis (classifier) h being tested.
33 Bernouli Process Let s draw a random example from the distribution D (which generates our examples). This is a Bernouli trial since there are only two outcomes, the example will be either correctly classified or misclassified. The probability of misclassification is p. Note also that p is the true error. We draw n examples and count the number of misclassifications r (corresponds to the number of heads). Sample error = r/n. If we repeat the same experiment another n times then r will be slightly different.
34 Binomial Distribution If we plot the histogram of the sample error r/n then it will also look like the following plot: The number of errors (r) is a random variable that follows a Binomial distribution. The probability of observing r errors in a data sample of n randomly drawn examples is:
35 Sample Error as Estimator True error = p Sample error = r/n Sample error is a random variable that follows a binomial distribution. Estimator = random variable used to estimate some parameter (in our case p) of the population from which the sample is drawn. Sample error is called an estimator of the true error. Expected value of r = np (Exp. Val. Binomial distribution) Expected value of sample error = np/n =p.
36 Sample Error as Estimator Q1: What is the best estimate of the accuracy over future examples drawn from the same distribution? True error = p Expected value of sample error = np/n =p. The best estimate of the true error is the sample error.
37 Confidence interval Q2: What is the probable error in this accuracy estimate? We want to assess the confidence that we can have in this classification measure. What we really want to estimate is a confidence interval for the true error. An N% confidence interval for some parameter p is an interval that is expected with probability N% to contain p. e.g. a 95% confidence interval [0.2,0.4] means that with probability 95% p lies between 0.2 and 0.4.
 by")
38 Trick (p. 138 ML book) by Xiao Fei
39 Confidence Interval Normal distribution of sample error μ The probability that the sample error will fall between L and U is for this example it is 80%. z n In other words, the sample error will fall between [ zn, zn ] N% of the time (in this example 80%). Similarly, we can say that μ will fall between [ errors zn, errors zn ] N% of the time. U L Pr Y
40 Confidence interval - Theory Given a sample S with n >= 30 on which hypothesis h makes r errors, we can say that: Q1: The most probable value of error D (h) is error s (h) Q2: With N % confidence, the true error lies in the interval: with: error s h z N error s h 1 error n s h
41 Confidence interval example (2) Given the following extract from a scientific paper on multimodal emotion recognition: For the Face modality, what is n? What is error s (h)? Exercise: compute the 95% confidence interval for this error.
42 Confidence interval example (3) Given that error s (h)=0.22 and n= 50, and z N =1.96 for N = 95%, we can now say that with 95% confidence error D (h) will lie in the interval: , ,0.34 What will happen when n?
43 Comparing Two Algorithms Consider the distributions as the classification errors of two different classifiers derived by cross-validation. The means of the distributions are not enough to say that one of the classifiers is better!! In all cases the mean difference is the same. That s why we need to run a statistical test to tell us if there is indeed a difference between the two distributions.
44 Two-sample T-test Null hypothesis: two sets of observations x, y are independent random samples from normal distributions with equal means. For example x, y could be the classification errors on two different datasets. We define the test statistic as: t x x n y 2 2 y m μ x, μ y are the sample means σ x 2, σ y 2 are the sample variances n, m are the sample sizes
45 Paired T-test Null hypothesis: the difference between the observations x-y are a random sample from a normal distribution with μ = 0 and unknown variance. It s called paired because the observations are matched, they are not independent. For example x, y could be the classification errors on the same folds of crossvalidation from two different algorithms. The test folds are the same, i.e. they are matched. We define the test statistic as: t x y 2 x y n μ x y is the sample mean of the differences σ 2 x y is the sample variance of the differences. n is the sample size

46 T-test The test statistic t will follow a t-distribution if the null hypothesis is true. That is why it is called t-test. Once we compute the test statistic we also define a confidence level, usually 95%. Confidence Level Degrees of freedom: number of values that are free to vary, e.g. for paired t-test = n-1. t is less than with probability 95%.
47 T-test If the calculated t value is above the threshold chosen for statistical significance then the null hypothesis that the two groups do not differ is rejected in favour of the alternative hypothesis, which typically states that the groups do differ. Significance level = 1 confidence level, so usually 5%. Significance level α%: α times out of 100 you would find a statistically significant difference between the distributions even if there was none. It essentially defines our tolerance level. To summarise: we only have to compute t, set α and we use a lookup table to check if our value t is higher than the value in the table. If yes, then our sets of observations are different (null hypothesis rejected).
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations
 Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Edexcel GCSE. Statistics 1389 Paper 1H. June Mark Scheme. Statistics Edexcel GCSE
 Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Stacks Teacher notes. Activity description. Suitability. Time. AMP resources. Equipment. Key mathematical language. Key processes
 Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
Stacks Teacher notes Activity description (Interactive not shown on this sheet.) Pupils start by exploring the patterns generated by moving counters between two stacks according to a fixed rule, doubling
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation
 School of Computer Science Human-Computer Interaction Institute Carnegie Mellon University Year 2007 Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation Noboru Matsuda
School of Computer Science Human-Computer Interaction Institute Carnegie Mellon University Year 2007 Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation Noboru Matsuda
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question.
 Ch 2 Test Remediation Work Name MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. Provide an appropriate response. 1) High temperatures in a certain
Ch 2 Test Remediation Work Name MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. Provide an appropriate response. 1) High temperatures in a certain
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lecture 2: Quantifiers and Approximation
 Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Lecture 2: Quantifiers and Approximation Case study: Most vs More than half Jakub Szymanik Outline Number Sense Approximate Number Sense Approximating most Superlative Meaning of most What About Counting?
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models
 What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Version Space. Term 2012/2013 LSI - FIB. Javier Béjar cbea (LSI - FIB) Version Space Term 2012/ / 18
 Version Space Term 2012/ / 18") Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Mining Student Evolution Using Associative Classification and Clustering
 Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Cultivating DNN Diversity for Large Scale Video Labelling
 Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
Cultivating DNN Diversity for Large Scale Video Labelling Mikel Bober-Irizar mikel@mxbi.net Sameed Husain sameed.husain@surrey.ac.uk Miroslaw Bober m.bober@surrey.ac.uk Eng-Jon Ong e.ong@surrey.ac.uk Abstract
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Speech Recognition by Indexing and Sequencing
 International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
International Journal of Computer Information Systems and Industrial Management Applications. ISSN 215-7988 Volume 4 (212) pp. 358 365 c MIR Labs, www.mirlabs.net/ijcisim/index.html Speech Recognition
Mathematics (JUN14MS0401) General Certificate of Education Advanced Level Examination June Unit Statistics TOTAL.
 General Certificate of Education Advanced Level Examination June Unit Statistics TOTAL.") Centre Number Candidate Number For Examiner s Use Surname Other Names Candidate Signature Examiner s Initials Mathematics Unit Statistics 4 Tuesday 24 June 2014 General Certificate of Education Advanced
Centre Number Candidate Number For Examiner s Use Surname Other Names Candidate Signature Examiner s Initials Mathematics Unit Statistics 4 Tuesday 24 June 2014 General Certificate of Education Advanced
Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation
 Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Mathematics process categories
 Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method
 Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Linking the Ohio State Assessments to NWEA MAP Growth Tests *
 Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C
 Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Activity Recognition from Accelerometer Data
 Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011
 Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning
 Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Evidence for Reliability, Validity and Learning Effectiveness
 PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
NEURAL PROCESSING INFORMATION SYSTEMS 2 DAVID S. TOURETZKY ADVANCES IN EDITED BY CARNEGI-E MELLON UNIVERSITY
 D. Cohn, L.E. Atlas, R. Ladner, M.A. El-Sharkawi, R.J. Marks II, M.E. Aggoune, D.C. Park, "Training connectionist networks with queries and selective sampling", Advances in Neural Network Information Processing
D. Cohn, L.E. Atlas, R. Ladner, M.A. El-Sharkawi, R.J. Marks II, M.E. Aggoune, D.C. Park, "Training connectionist networks with queries and selective sampling", Advances in Neural Network Information Processing
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Measurement. When Smaller Is Better. Activity:
 Measurement Activity: TEKS: When Smaller Is Better (6.8) Measurement. The student solves application problems involving estimation and measurement of length, area, time, temperature, volume, weight, and
Measurement Activity: TEKS: When Smaller Is Better (6.8) Measurement. The student solves application problems involving estimation and measurement of length, area, time, temperature, volume, weight, and
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
Many instructors use a weighted total to calculate their grades. This lesson explains how to set up a weighted total using categories.
 Weighted Totals Many instructors use a weighted total to calculate their grades. This lesson explains how to set up a weighted total using categories. Set up your grading scheme in your syllabus Your syllabus
Weighted Totals Many instructors use a weighted total to calculate their grades. This lesson explains how to set up a weighted total using categories. Set up your grading scheme in your syllabus Your syllabus
How do adults reason about their opponent? Typologies of players in a turn-taking game
 How do adults reason about their opponent? Typologies of players in a turn-taking game Tamoghna Halder (thaldera@gmail.com) Indian Statistical Institute, Kolkata, India Khyati Sharma (khyati.sharma27@gmail.com)
How do adults reason about their opponent? Typologies of players in a turn-taking game Tamoghna Halder (thaldera@gmail.com) Indian Statistical Institute, Kolkata, India Khyati Sharma (khyati.sharma27@gmail.com)
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques
 Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Non intrusive multi-biometrics on a mobile device: a comparison of fusion techniques Lorene Allano 1*1, Andrew C. Morris 2, Harin Sellahewa 3, Sonia Garcia-Salicetti 1, Jacques Koreman 2, Sabah Jassim
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Informatics 2A: Language Complexity and the. Inf2A: Chomsky Hierarchy
 Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Informatics 2A: Language Complexity and the Chomsky Hierarchy September 28, 2010 Starter 1 Is there a finite state machine that recognises all those strings s from the alphabet {a, b} where the difference
Cooperative evolutive concept learning: an empirical study
 Cooperative evolutive concept learning: an empirical study Filippo Neri University of Piemonte Orientale Dipartimento di Scienze e Tecnologie Avanzate Piazza Ambrosoli 5, 15100 Alessandria AL, Italy Abstract
Cooperative evolutive concept learning: an empirical study Filippo Neri University of Piemonte Orientale Dipartimento di Scienze e Tecnologie Avanzate Piazza Ambrosoli 5, 15100 Alessandria AL, Italy Abstract
4-3 Basic Skills and Concepts
 4-3 Basic Skills and Concepts Identifying Binomial Distributions. In Exercises 1 8, determine whether the given procedure results in a binomial distribution. For those that are not binomial, identify at
4-3 Basic Skills and Concepts Identifying Binomial Distributions. In Exercises 1 8, determine whether the given procedure results in a binomial distribution. For those that are not binomial, identify at
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion