P(A, B) = P(A B) = P(A) + P(B) - P(A B)
|
|
|
- Brett Willis
- 6 years ago
- Views:
Transcription
 = P(A) + P(B) - P(A B) Area = Probability of")
1 AND Probability P(A, B) = P(A B) = P(A) + P(B) - P(A B) P(A B) = P(A) + P(B) - P(A B) Area = Probability of Event
2 AND Probability P(A, B) = P(A B) = P(A) + P(B) - P(A B) If, and only if, A and B are independent, then and only then P(A and B) = P(A)*P(B). If A and B are disjoint (i.e., never co-occur), then P(A and B) = 0. If A and B are synonyms (i.e., co-occur exactly) then P(A and B) = P(A) = P(B).
3 Introduction to Machine Learning Reading for today: R&N Next lecture: R&N ,
4 Outline The importance of a good representation Different types of learning problems Different types of learning algorithms Supervised learning Decision trees Naïve Bayes Perceptrons, Multi-layer Neural Networks Boosting Unsupervised Learning K-means Applications: learning to detect faces in images Reading for today s lecture: Chapter 18.1 to 18.4 (inclusive)
5 You will be expected to know Understand Attributes, Error function, Classification, Regression, Hypothesis (Predictor function) What is Supervised Learning? Decision Tree Algorithm Entropy Information Gain Tradeoff between train and test with model complexity Cross validation
6 Search? Complete architectures for intelligence? Solve the problem of what to do. Learning? Learn what to do. Logic and inference? Reason about what to do. Encoded knowledge/ expert systems? Know what to do. Modern view: It s complex & multi-faceted.

7 Automated Learning Why is it useful for our agent to be able to learn? Learning is a key hallmark of intelligence The ability of an agent to take in real data and feedback and improve performance over time Check out USC Autonomous Flying Vehicle Project! Types of learning Supervised learning Learning a mapping from a set of inputs to a target variable Classification: target variable is discrete (e.g., spam ) Regression: target variable is real-valued (e.g., stock market) Unsupervised learning No target variable provided Clustering: grouping data into K groups Other types of learning Reinforcement learning: e.g., game-playing agent Learning to rank, e.g., document ranking in Web search And many others.
8 The importance of a good representation Properties of a good representation: Reveals important features Hides irrelevant detail Exposes useful constraints Makes frequent operations easy-to-do Supports local inferences from local features Called the soda straw principle or locality principle Inference from features through a soda straw Rapidly or efficiently computable It s nice to be fast
9 Reveals important features / Hides irrelevant detail You can t learn what you can t represent. --- G. Sussman In search: A man is traveling to market with a fox, a goose, and a bag of oats. He comes to a river. The only way across the river is a boat that can hold the man and exactly one of the fox, goose or bag of oats. The fox will eat the goose if left alone with it, and the goose will eat the oats if left alone with it. A good representation makes this problem easy:
10 Simple illustrative learning problem Problem: decide whether to wait for a table at a restaurant, based on the following attributes: 1. Alternate: is there an alternative restaurant nearby? 2. Bar: is there a comfortable bar area to wait in? 3. Fri/Sat: is today Friday or Saturday? 4. Hungry: are we hungry? 5. Patrons: number of people in the restaurant (None, Some, Full) 6. Price: price range ($, $$, $$$) 7. Raining: is it raining outside? 8. Reservation: have we made a reservation? 9. Type: kind of restaurant (French, Italian, Thai, Burger) 10. WaitEstimate: estimated waiting time (0-10, 10-30, 30-60, >60)
11 Training Data for Supervised Learning
12 Terminology Attributes Also known as features, variables, independent variables, covariates Target Variable Also known as goal predicate, dependent variable, Classification Also known as discrimination, supervised classification, Error function Objective function, loss function,
13 Inductive learning Let x represent the input vector of attributes Let f(x) represent the value of the target variable for x The implicit mapping from x to f(x) is unknown to us We just have training data pairs, D = {x, f(x)} available We want to learn a mapping from x to f, i.e., h(x; θ) is close to f(x) for all training data points x θ are the parameters of our predictor h(..) Examples: h(x; θ) = sign(w 1 x 1 + w 2 x 2 + w 3 ) h k (x) = (x1 OR x2) AND (x3 OR NOT(x4))
14 Empirical Error Functions Empirical error function: E(h) = Σ x distance[h(x; θ), f] e.g., distance = squared error if h and f are real-valued (regression) distance = delta-function if h and f are categorical (classification) Sum is over all training pairs in the training data D In learning, we get to choose 1. what class of functions h(..) that we want to learn potentially a huge space! ( hypothesis space ) 2. what error function/distance to use - should be chosen to reflect real loss in problem - but often chosen for mathematical/algorithmic convenience
15 Inductive Learning as Optimization or Search Empirical error function: E(h) = Σ x distance[h(x; θ), f] Empirical learning = finding h(x), or h(x; θ) that minimizes E(h) In simple problems there may be a closed form solution E.g., normal equations when h is a linear function of x, E = squared error If E(h) is differentiable as a function of q, then we have a continuous optimization problem and can use gradient descent, etc E.g., multi-layer neural networks If E(h) is non-differentiable (e.g., classification), then we typically have a systematic search problem through the space of functions h E.g., decision tree classifiers Once we decide on what the functional form of h is, and what the error function E is, then machine learning typically reduces to a large search or optimization problem Additional aspect: we really want to learn an h(..) that will generalize well to new data, not just memorize training data will return to this later
16 Our training data example (again) If all attributes were binary, h(..) could be any arbitrary Boolean function Natural error function E(h) to use is classification error, i.e., how many incorrect predictions does a hypothesis h make Note an implicit assumption: For any set of attribute values there is a unique target value This in effect assumes a no-noise mapping from inputs to targets This is often not true in practice (e.g., in medicine). Will return to this later
 Truth table has 2 d rows So there are 2 to the power of 2 d different Boolean functions we can define (!")
17 Learning Boolean Functions Given examples of the function, can we learn the function? How many Boolean functions can be defined on d attributes? Boolean function = Truth table + column for target function (binary) Truth table has 2 d rows So there are 2 to the power of 2 d different Boolean functions we can define (!) This is the size of our hypothesis space William of Ockham c E.g., d = 6, there are 18.4 x possible Boolean functions Observations: Huge hypothesis spaces > directly searching over all functions is impossible Given a small data (n pairs) our learning problem may be underconstrained Ockham s razor: if multiple candidate functions all explain the data equally well, pick the simplest explanation (least complex function) Constrain our search to classes of Boolean functions, e.g., decision trees Weighted linear sums of inputs (e.g., perceptrons)
18 Decision Tree Learning Constrain h(..) to be a decision tree

19 Decision Tree Representations Decision trees are fully expressive can represent any Boolean function Every path in the tree could represent 1 row in the truth table Yields an exponentially large tree Truth table is of size 2 d, where d is the number of attributes
20 Decision Tree Representations Trees can be very inefficient for certain types of functions Parity function: 1 only if an even number of 1 s in the input vector Trees are very inefficient at representing such functions Majority function: 1 if more than ½ the inputs are 1 s Also inefficient Simple DNF formulae can be easily represented E.g., f = (A AND B) OR (NOT(A) AND D) DNF = disjunction of conjunctions Decision trees are in effect DNF representations often used in practice since they often result in compact approximate representations for complex functions E.g., consider a truth table where most of the variables are irrelevant to the function
21 Decision Tree Learning Find the smallest decision tree consistent with the n examples Unfortunately this is provably intractable to do optimally Greedy heuristic search used in practice: Select root node that is best in some sense Partition data into 2 subsets, depending on root attribute value Recursively grow subtrees Different termination criteria For noiseless data, if all examples at a node have the same label then declare it a leaf and backup For noisy data it might not be possible to find a pure leaf using the given attributes we ll return to this later but a simple approach is to have a depth-bound on the tree (or go to max depth) and use majority vote We have talked about binary variables up until now, but we can trivially extend to multi-valued variables
22 Pseudocode for Decision tree learning
23 Choosing an attribute Idea: a good attribute splits the examples into subsets that are (ideally) "all positive" or "all negative" Patrons? is a better choice How can we quantify this? One approach would be to use the classification error E directly (greedily) Empirically it is found that this works poorly Much better is to use information gain (next slides)
24 Entropy H(p) = entropy of distribution p = {p i } (called information in text) = E [p i log (1/p i ) ] = - p log p - (1-p) log (1-p) Entropy is the expected amount of information we gain, given a probability distribution its our average uncertainty In general, H(p) is maximized when all p i are equal and minimized (=0) when one of the p i s is 1 and all others zero.
25 Entropy with only 2 outcomes Consider 2 class problem: p = probability of class 1, 1 p = probability of class 2 In binary case, H(p) = - p log p - (1-p) log (1-p) H(p) p
26 Information Gain H(p) = entropy of class distribution at a particular node H(p A) = conditional entropy = average entropy of conditional class distribution, after we have partitioned the data according to the values in A Gain(A) = H(p) H(p A) Simple rule in decision tree learning At each internal node, split on the node with the largest information gain (or equivalently, with smallest H(p A)) Note that by definition, conditional entropy can t be greater than the entropy
27 Root Node Example For the training set, 6 positives, 6 negatives, H(6/12, 6/12) = 1 bit positive (p) negative (1-p) >> H(6/12,6/12) = -(6/12)*log2(6/12)-(6/12)*log2(6/12) Consider the attributes Patrons and Type: I I 2 4 ( PG a) = 1 t [ r H (0,1) o + n Hs(1,0) ( TG ) = y1 [ p H ( e 1 2 1, ) H (, ) H (, ) = ].0 b5 i4 t 1s H (, ) H (, ) = ] 0 b Patrons has the highest IG of all attributes and so is chosen by the learning algorithm as the root Information gain is then repeatedly applied at internal nodes until all leaves contain only examples from one class or the other
28 Choosing an attribute
29 Decision Tree Learned Decision tree learned from the 12 examples:
30 True Tree (left) versus Learned Tree (right)
31 Assessing Performance Training data performance is typically optimistic e.g., error rate on training data Reasons? - classifier may not have enough data to fully learn the concept (but on training data we don t know this) - for noisy data, the classifier may overfit the training data In practice we want to assess performance out of sample how well will the classifier do on new unseen data? This is the true test of what we have learned (just like a classroom) With large data sets we can partition our data into 2 subsets, train and test - build a model on the training data - assess performance on the test data
32 Example of Test Performance Restaurant problem - simulate 100 data sets of different sizes - train on this data, and assess performance on an independent test set - learning curve = plotting accuracy as a function of training set size - typical diminishing returns effect (some nice theory to explain this)
33 Overfitting and Underfitting Y X
34 A Complex Model Y = high-order polynomial in X Y X
35 A Much Simpler Model Y = a X + b + noise Y X
36 Example 2
37 Example 2
38 Example 2
39 Example 2
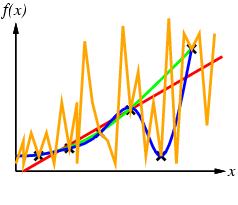
40 Example 2
41 How Overfitting affects Prediction Predictive Error Error on Training Data Model Complexity
42 How Overfitting affects Prediction Predictive Error Error on Test Data Error on Training Data Model Complexity
43 How Overfitting affects Prediction Predictive Error Underfitting Overfitting Error on Test Data Error on Training Data Ideal Range for Model Complexity Model Complexity
44 Training and Validation Data Full Data Set Training Data Validation Data Idea: train each model on the training data and then test each model s accuracy on the validation data
45 The k-fold Cross-Validation Method Why just choose one particular 90/10 split of the data? In principle we could do this multiple times k-fold Cross-Validation (e.g., k=10) randomly partition our full data set into k disjoint subsets (each roughly of size n/k, n = total number of training data points) for i = 1:10 (here k = 10) end train on 90% of data, Acc(i) = accuracy on other 10% Cross-Validation-Accuracy = 1/k Σ i Acc(i) choose the method with the highest cross-validation accuracy common values for k are 5 and 10 Can also do leave-one-out where k = n
46 Disjoint Validation Data Sets Full Data Set Validation Data (aka Test Data) 1 st partition Training Data
47 Disjoint Validation Data Sets Full Data Set Validation Data (aka Test Data) 1 st partition 2 nd partition Training Data
48 Disjoint Validation Data Sets Full Data Set Validation Data (aka Test Data) 1 st partition 2 nd partition Training Data Validation Data 3 rd partition 4 th partition 5 th partition
49 More on Cross-Validation Notes cross-validation generates an approximate estimate of how well the learned model will do on unseen data by averaging over different partitions it is more robust than just a single train/validate partition of the data k-fold cross-validation is a generalization partition data into disjoint validation subsets of size n/k train, validate, and average over the v partitions e.g., k=10 is commonly used k-fold cross-validation is approximately k times computationally more expensive than just fitting a model to all of the data
50 Summary Inductive learning Error function, class of hypothesis/models {h} Want to minimize E on our training data Example: decision tree learning Generalization Training data error is over-optimistic We want to see performance on test data Cross-validation is a useful practical approach Learning to recognize faces Viola-Jones algorithm: state-of-the-art face detector, entirely learned from data, using boosting+decision-stumps
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Version Space. Term 2012/2013 LSI - FIB. Javier Béjar cbea (LSI - FIB) Version Space Term 2012/ / 18
 Version Space Term 2012/ / 18") Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
A Version Space Approach to Learning Context-free Grammars
 Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Machine Learning 2: 39~74, 1987 1987 Kluwer Academic Publishers, Boston - Manufactured in The Netherlands A Version Space Approach to Learning Context-free Grammars KURT VANLEHN (VANLEHN@A.PSY.CMU.EDU)
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the SAT
 The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
The Journal of Technology, Learning, and Assessment Volume 6, Number 6 February 2008 Using the Attribute Hierarchy Method to Make Diagnostic Inferences about Examinees Cognitive Skills in Algebra on the
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Learning goal-oriented strategies in problem solving
 Learning goal-oriented strategies in problem solving Martin Možina, Timotej Lazar, Ivan Bratko Faculty of Computer and Information Science University of Ljubljana, Ljubljana, Slovenia Abstract The need
Learning goal-oriented strategies in problem solving Martin Možina, Timotej Lazar, Ivan Bratko Faculty of Computer and Information Science University of Ljubljana, Ljubljana, Slovenia Abstract The need
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge
 Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Introduction to Simulation
 Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Introduction to Simulation Spring 2010 Dr. Louis Luangkesorn University of Pittsburgh January 19, 2010 Dr. Louis Luangkesorn ( University of Pittsburgh ) Introduction to Simulation January 19, 2010 1 /
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
IT Students Workshop within Strategic Partnership of Leibniz University and Peter the Great St. Petersburg Polytechnic University
 IT Students Workshop within Strategic Partnership of Leibniz University and Peter the Great St. Petersburg Polytechnic University 06.11.16 13.11.16 Hannover Our group from Peter the Great St. Petersburg
IT Students Workshop within Strategic Partnership of Leibniz University and Peter the Great St. Petersburg Polytechnic University 06.11.16 13.11.16 Hannover Our group from Peter the Great St. Petersburg
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
CHAPTER 4: REIMBURSEMENT STRATEGIES 24
 CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Decision Analysis. Decision-Making Problem. Decision Analysis. Part 1 Decision Analysis and Decision Tables. Decision Analysis, Part 1
 Decision Support: Decision Analysis Jožef Stefan International Postgraduate School, Ljubljana Programme: Information and Communication Technologies [ICT3] Course Web Page: http://kt.ijs.si/markobohanec/ds/ds.html
Decision Support: Decision Analysis Jožef Stefan International Postgraduate School, Ljubljana Programme: Information and Communication Technologies [ICT3] Course Web Page: http://kt.ijs.si/markobohanec/ds/ds.html
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
On-the-Fly Customization of Automated Essay Scoring
 Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Word learning as Bayesian inference
 Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Physics 270: Experimental Physics
 2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
ScienceDirect. A Framework for Clustering Cardiac Patient s Records Using Unsupervised Learning Techniques
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm
 Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Syntax Parsing 1. Grammars and parsing 2. Top-down and bottom-up parsing 3. Chart parsers 4. Bottom-up chart parsing 5. The Earley Algorithm syntax: from the Greek syntaxis, meaning setting out together
Algebra 2- Semester 2 Review
 Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Name Block Date Algebra 2- Semester 2 Review Non-Calculator 5.4 1. Consider the function f x 1 x 2. a) Describe the transformation of the graph of y 1 x. b) Identify the asymptotes. c) What is the domain
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Toward Probabilistic Natural Logic for Syllogistic Reasoning
 Toward Probabilistic Natural Logic for Syllogistic Reasoning Fangzhou Zhai, Jakub Szymanik and Ivan Titov Institute for Logic, Language and Computation, University of Amsterdam Abstract Natural language
Toward Probabilistic Natural Logic for Syllogistic Reasoning Fangzhou Zhai, Jakub Szymanik and Ivan Titov Institute for Logic, Language and Computation, University of Amsterdam Abstract Natural language
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Constructive Induction-based Learning Agents: An Architecture and Preliminary Experiments
 Proceedings of the First International Workshop on Intelligent Adaptive Systems (IAS-95) Ibrahim F. Imam and Janusz Wnek (Eds.), pp. 38-51, Melbourne Beach, Florida, 1995. Constructive Induction-based
Proceedings of the First International Workshop on Intelligent Adaptive Systems (IAS-95) Ibrahim F. Imam and Janusz Wnek (Eds.), pp. 38-51, Melbourne Beach, Florida, 1995. Constructive Induction-based
On the Polynomial Degree of Minterm-Cyclic Functions
 On the Polynomial Degree of Minterm-Cyclic Functions Edward L. Talmage Advisor: Amit Chakrabarti May 31, 2012 ABSTRACT When evaluating Boolean functions, each bit of input that must be checked is costly,
On the Polynomial Degree of Minterm-Cyclic Functions Edward L. Talmage Advisor: Amit Chakrabarti May 31, 2012 ABSTRACT When evaluating Boolean functions, each bit of input that must be checked is costly,
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Multi-Lingual Text Leveling
 Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
Multi-Lingual Text Leveling Salim Roukos, Jerome Quin, and Todd Ward IBM T. J. Watson Research Center, Yorktown Heights, NY 10598 {roukos,jlquinn,tward}@us.ibm.com Abstract. Determining the language proficiency
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality