In-depth: Deep learning (one lecture) Applied to both SL and RL above Code examples
|
|
|
- Brianna Rice
- 6 years ago
- Views:
Transcription
 Applied to both SL and RL above Code examples 2017-09-30 2")
1 Introduction to machine learning (two lectures) Supervised learning Reinforcement learning (lab) In-depth: Deep learning (one lecture) Applied to both SL and RL above Code examples

2 To enable machines to learn and adapt skills without programming them Our only frame of reference for learning is from biology but brains are hideously complex, the result of ages of evolution Like much of AI, Machine Learning mainly takes an engineering approach 1 Remember, humanity didn t master flight by just imitating birds! 1. Although there is occasional biological inspiration Hint: Lots of math... Statistics (theories of how to learn from data) Optimization (how to solve such learning problems) Computer Science (efficient algorithms for this) This intro will focus more on intuitions than mathematical details ML also overlaps with multiple areas of engineering, e.g. Computer vision Natural language processing (e.g. machine translation) Robotics, signal processing and control theory...but traditionally differs by focusing more on data-driven models and AI
3 Difficulty in manually programming agents for every possible situation The world is ever changing, if an agent cannot adapt, it will fail Many argue learning is required for Artificial General Intelligence (AGI) We are still far from human-level general learning ability but the algorithms we have so far have shown themselves to be useful in a wide range of applications! Not as data-efficient as human learning, but once an AI is good enough, it can be cheaply duplicated Computers work 24/7 and you can usually scale throughput by piling on more of them Software Agents (Apps and web services) Companies collect ever more data and processing power is cheap ( Big data ) Can let an AI learn how to improve business, e.g. smarter product recommendations, search engine results, or ad serving Can sell services that traditionally required human work, e.g. translation, image categorization, mail filtering, content generation? Hardware Agents (Robotics) Although data is more expensive, many capabilities that humans take for granted like locomotion, grasping, recognizing objects, speech have turned out to be ridiculously difficult to manually construct rules for



4 in narrow applications machine learning can even rival or beat human performance in narrow applications machine learning can even rival human performance
5 Given a task, mathematically encoded via some performance metric, a machine can improve its performance by learning from experience (data) From the agent perspective: Performance Metric Input (Sensors) Agent World Output (Actuators) Machine learning is a young science that is still changing, but traditionally algorithms are divided into three types depending on their purpose. Supervised Learning Reinforcement Learning Unsupervised Learning
6 In supervised learning Agent has to learn from examples of correct behavior Formally, learn an unknown function f(x) = y given examples of (x, y) Performance metric: Loss (difference) between learned function and correct examples Representation from agent perspective: Performance Metric state Reactive Agent f(input) = output e.g. f(robot state) = action action Input (Sensors) Output (Actuators) World but it can also be used as a component in other architectures Supervised Learning is surprisingly powerful and ubiquitous Some real world examples Spam Filter: f(mail) = spam? Microsoft Kinect: f(pixels, distance) = body part


 2017-09-30 13 .")
 Given new low-res image x below,")
7 Learn y=f(x) from examples (x,y),... x = depth image, y = body part Given new depth image below, predict body part per pixel: right hand neck left shoulder right elbow Used in Microsoft Kinect SDK (Shotton et al, CVPR 2011) Learn y=f(x) from examples (x,y),... x = low-res image, y = high-res image (real numbers) Given new low-res image x below, predict y :
8 In reinforcement learning World may have state (e.g. position in maze) and be unknown (how does an action change the state) In each step the agent is only given current state and reward instead of examples of correct behavior Performance metric is sum of rewards over time Combines learning with a planning problem Agent has to plan a sequence of actions for good performance The agent can even learn on its own if the reward signal can be mathematically defined RL is based on a utility (reward) maximizing agent framework Rewards of actions in different states are learned Agent plans ahead to maximize reward over time Performance Metric (reward) state Input (Sensors) RL Agent R(state, action) = reward f(state, action) = new state World Maximize total rewards action Output (Actuators) Real world examples Robot Behavior, Game Playing (AlphaGo )
9 Learning to flip pancakes, supervised and reinforcement learning In unsupervised learning Neither a correct answer/output, nor a reward is given Task is to find some structure in the data Performance metric is some reconstruction error of patterns compared to the input data distribution Examples: Clustering When the data distribution is confined to lie in a small number of clusters we can find these and use them instead of the original representation Dimensionality Reduction Finding a suitable lower dimensional representation while preserving as much information as possible Recent trend: Found structure can be used to generate new examples!

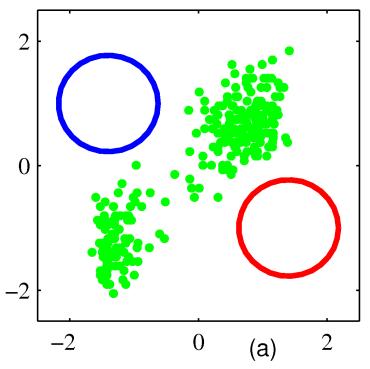


10 Two-dimensional continuous input (Bishop, 2006) Two-dimensional continuous input (Bishop, 2006)

 https://youtu.")


11 Generative model ( Hallucination ) based on Text-Image data Future applications in content generation? (Nguyen et al, 2017) 22 Today we will talk about Supervised Learning Definition Main Concepts General Approaches & Applications Trend: Neural Networks and Deep Learning
12 Remember, in Supervised Learning: Given tuples of training data consisting of (x,y) pairs The objective is to learn to predict the output y for a new input x Formalized as searching for approximation to unknown function y = f(x), given N examples of x and y: (x 1,y 1 ),,(x n,y n ) A candidate approximation is sometimes called a hypothesis (book) Two major classes of supervised learning Classification Output are discrete category labels Example: Detecting disease, y = healthy or ill Regression Output are numeric values Example: Predicting temperature, y = 15.3 degrees In either case, input data x i could be vector valued and discrete, continuous or mixed. Example: x 1 = (12.5, cloud free, true) Can be seen as searching for an approximation to unknown function y = f(x) given N examples of x and y: (x 1,y 1 ),,(x n,y n ) Want the algorithm to generalize from training examples to new inputs x, so that y =f(x ) is close to the correct answer. 1. First construct an input vector x i of examples by encoding relevant problem data. This is often called the feature vector. Examples of such (x i, y i ) is the training set. 2. A model is selected and trained on the examples by searching for parameters (the hypothesis space) that yield a good approximation to the unknown true function. 3. Evaluate performance, (carefully) tweak algorithm or features

 2017-09-30 26 One of the early successes was learning spam filters Spam classification example: Each mail is an input,")
13 Want to learn f(x) = y given N examples of x and y: (x 1,y 1 ),,(x n,y n ) Most standard algorithms work on real number variables If inputs x or outputs y contain categorical values like book or car, we need to encode them with numbers With only two classes we get y in {0,1}, called binary classification Classification into multiple classes can be reduced to a sequence of binary onevs-all classifiers The variables may also be structured like in text, graphs, audio, image or video data Finding a suitable feature representation can be non-trivial, but there are standard approaches for the common domains (given enough data it can also be learned via deep learning) One of the early successes was learning spam filters Spam classification example: Each mail is an input, some mails are flagged as spam or not spam to create training examples. Bag of Words Feature Vector: Encode the existence of a fixed set of relevant key words in each mail as the feature vector. x i = words i = Feature Customer Dollar Nigeria 0 Accept 1 Bank 0. y i = 1 (spam) or 0 (not spam) Exists? 1 (Yes) 0 (No) Simply learn f(x)=y using suitable classifier!




 Select the familiy of linear functions Train the algorithm by searching for a line that fits the data well but")
14 I. Construct a feature vector x i to be used with examples of y i II. Select algorithm and train on training data by searching for a good approximation to the unknown function Fictional example: A learning smartphone app that determines if silent mode should be on/off at different levels of background noise and light based previous user choices. Feature vector x i = (Noise, Light level), y i = { silent on, silent off } Select the familiy of linear discriminant functions Train the algorithm by searching for a line that separates the classes well New cases will be classified according to which side they fall I. Construct a feature vector x i to be used with examples of y i II. Select algorithm and train on training set by searching for a good approximation to the unknown function Fictional example: Same smartphone app but now we want to predict the ring volume based on background noise level (only) Feature vector x i = (Noise db), y i = (Volume %) Select the familiy of linear functions Train the algorithm by searching for a line that fits the data well but how does training really work?
15 Feature vector x i = (Noise in db), outputs y i = (Volume %) Want to find approximation h(x) to the unknown function f(x) As an example we select the hypothesis space to be the family of polynomials of degree one, that is linear functions: The hypothesis space of has two parameters How do we find parameters that result in a good approximation h? Three (poor) linear hypotheses How do we find parameters w that result in a good approximation? Need a performance metric for function approximations of uknown f(x) Loss functions Minimize deviation against the N example data points For regression one common choice is a sum square loss function: Search in continuous domains like w is known as optimization (if unfamiliar, see Ch4.2 in course book AIMA)



16 How do we find parameters w that minimize the loss? Optimization approaches typically move in the direction that locally decreases the loss function Simple and popular approach: gradient descent Initialize w to some random point in the parameter space loop until decrease in loss is small for each in w do Note: Limitations Locally greedy Gets stuck in local minima unless the loss function is convex w.r.t. w, i.e. there is only one minima. Linear models are convex, however most more advanced models are vulnerable to getting stuck in local minina. Care should be taken when training such models by using for example random restarts and picking the least bad minima. If we happen to start in red area, optimization will get stuck in a bad local minima!
 Maximize information gain (used in decision trees, see book) These require specialized parameter search methods Alternative: Squash predicted numeric outputs to [0,1] via sigmoid ( S )")
17 What about classification? Squared error does not make sense when target output in {0,1} Custom loss functions for classification Minimize number of missclassifications (unsmooth w.r.t. parameter changes) Maximize information gain (used in decision trees, see book) These require specialized parameter search methods Alternative: Squash predicted numeric outputs to [0,1] via sigmoid ( S ) Sigmoid functions allow us to use any regression method for binary classification Logistic function for binary classification: Interpret as 1 Interpret as 0 Soft-max (see book) for multiple classes Advantages Linear algorithms are simple and computationally efficient Training them is a convex optimization problem, i.e. one is guaranteed to find the best hypothesis in the space of linear hypothesis Can be extended by non-linear feature transformations Disadvantages The hypothesis space is very restricted, it cannot handle non-linear relations well Still widely used in applications Recommender Systems Initial Netflix Cinematch was a linear regression, before their $1 million competition to improve it At the core of many big internet services. Ad systems at Twitter, Facebook, Google etc
 The Neuron The Network 2017-09-30 38 In (one input) linear regression we used the model:")
18 One non-linear model that has captivated people for decades is Artificial Neural Networks (ANNs) These draw upon inspiration from the physical structure of the brain as an interconnected network of neurons, emitting electrical spikes when excited by inputs (represented by non-linear activation functions ) The Neuron The Network In (one input) linear regression we used the model: Each neuron in an ANN is a linear model of all the inputs passed through a non-linear activation function g, representing the spiking behavior. The activation function is traditionally a sigmoid, but other options exist ANNs generalize logistic linear regression!
19 However, there is not just one neuron, but a network of neurons! Each neuron gets inputs from all neurons in the previous layer. We rewrite our neuron definition using a i for the input, a j for the output and w i,j for the weight parameters: The networks are composed into layers In a traditional feed-forward and fully-connected ANN, all neurons in a layer are connected to all neurons in the next layer, but not to each other Expanding the output of a second layer neuron (5) we get





20 Abstraction Faces Recent surge of successes with deep learning, using multi-layer models like ANNs to better capture layers of abstractions in data. Some tasks are uniquely suited to this like vision, text and speech recognition, where they hold state-of-the-art results. Facial parts Already used by Google, MSFT etc. These require large amounts of data and computation to train, although unsupervised techniques can reduce need for data. Edges More on this later. (Honglak Lee, 2009) How do we train an ANN to find the best parameters w i,j for each layer? Like before, by optimization, minimizing a loss function What is the computational complexity of ANN gradients? Just evaluting network prediction for ANN with p parameters is O(p) Predict output on training set Naive symbolic/numerical differentiation needs O(p) evaluations This means computational complexity of O(p 2 )! Deep learning networks often have >1M parameters. Can we do better?
21 Some intuitions: Consider the chain rule of differentiation E.g assume f(x) = g(h(i(x))), then f(x) = g (h(i(x)))h (i(x))i (x) ANN layers are just compositions of sums and non-linear functions g() ANN derivatives can be computed layerwise backwards, and terms are shared across parameter derivatives! Predict output on training set Caching these terms gives rise to a famous O(p) gradient algorithm Compute errors called backpropagation w.r.t. a loss function Propagate backwards and compute derivatives of weights in all layers See interactive examples of ANN training You can try playing with Different data sets vs. network size Deeper neurons can capture more complex patterns Classification vs. Regression Learning rate (Scaling of gradient descent step)
 Used for speech, object and text recognition at Google, MSFT etc. Often using millions of neurons/parameters and GPU acceleration.")

22 Advantages Very large hypothesis space, under some conditions it is a universal approximator to any function f(x) Some biological justification (real NNs more complex) Can be layered to capture abstraction (deep learning) Used for speech, object and text recognition at Google, MSFT etc. Often using millions of neurons/parameters and GPU acceleration. Modern GPU-accelerated tools for large models and Big Data Tensorflow (Google), PyTorch (Facebook), Theano etc. Disadvantages Training is a non-convex problem with saddle points and local minima Has many tuning parameters to twiddle with (number of neurons, layers, starting weights, gradient scaling...) Difficult to interpret or debug weights in the network Believed to be a more common problem than local minima for ANN

23 Thank you for listening!
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
MYCIN. The MYCIN Task
 MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
MYCIN Developed at Stanford University in 1972 Regarded as the first true expert system Assists physicians in the treatment of blood infections Many revisions and extensions over the years The MYCIN Task
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
AUTOMATIC DETECTION OF PROLONGED FRICATIVE PHONEMES WITH THE HIDDEN MARKOV MODELS APPROACH 1. INTRODUCTION
 JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
JOURNAL OF MEDICAL INFORMATICS & TECHNOLOGIES Vol. 11/2007, ISSN 1642-6037 Marek WIŚNIEWSKI *, Wiesława KUNISZYK-JÓŹKOWIAK *, Elżbieta SMOŁKA *, Waldemar SUSZYŃSKI * HMM, recognition, speech, disorders
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
INPE São José dos Campos
 INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
INPE-5479 PRE/1778 MONLINEAR ASPECTS OF DATA INTEGRATION FOR LAND COVER CLASSIFICATION IN A NEDRAL NETWORK ENVIRONNENT Maria Suelena S. Barros Valter Rodrigues INPE São José dos Campos 1993 SECRETARIA
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
FUZZY EXPERT. Dr. Kasim M. Al-Aubidy. Philadelphia University. Computer Eng. Dept February 2002 University of Damascus-Syria
 FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
FUZZY EXPERT SYSTEMS 16-18 18 February 2002 University of Damascus-Syria Dr. Kasim M. Al-Aubidy Computer Eng. Dept. Philadelphia University What is Expert Systems? ES are computer programs that emulate
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Forget catastrophic forgetting: AI that learns after deployment
 Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Forget catastrophic forgetting: AI that learns after deployment Anatoly Gorshechnikov CTO, Neurala 1 Neurala at a glance Programming neural networks on GPUs since circa 2 B.C. Founded in 2006 expecting
Intelligent Agents. Chapter 2. Chapter 2 1
 Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Intelligent Agents Chapter 2 Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Environment types The structure of agents Chapter 2 2 Agents
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
On the Formation of Phoneme Categories in DNN Acoustic Models
 On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
On the Formation of Phoneme Categories in DNN Acoustic Models Tasha Nagamine Department of Electrical Engineering, Columbia University T. Nagamine Motivation Large performance gap between humans and state-
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
LEGO MINDSTORMS Education EV3 Coding Activities
 LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
LEGO MINDSTORMS Education EV3 Coding Activities s t e e h s k r o W t n e d Stu LEGOeducation.com/MINDSTORMS Contents ACTIVITY 1 Performing a Three Point Turn 3-6 ACTIVITY 2 Written Instructions for a
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments
 Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
Specification and Evaluation of Machine Translation Toy Systems - Criteria for laboratory assignments Cristina Vertan, Walther v. Hahn University of Hamburg, Natural Language Systems Division Hamburg,
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification
 Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Class-Discriminative Weighted Distortion Measure for VQ-Based Speaker Identification Tomi Kinnunen and Ismo Kärkkäinen University of Joensuu, Department of Computer Science, P.O. Box 111, 80101 JOENSUU,
Artificial Neural Networks
 Artificial Neural Networks Andres Chavez Math 382/L T/Th 2:00-3:40 April 13, 2010 Chavez2 Abstract The main interest of this paper is Artificial Neural Networks (ANNs). A brief history of the development
Artificial Neural Networks Andres Chavez Math 382/L T/Th 2:00-3:40 April 13, 2010 Chavez2 Abstract The main interest of this paper is Artificial Neural Networks (ANNs). A brief history of the development
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Speaker Identification by Comparison of Smart Methods. Abstract
 Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Journal of mathematics and computer science 10 (2014), 61-71 Speaker Identification by Comparison of Smart Methods Ali Mahdavi Meimand Amin Asadi Majid Mohamadi Department of Electrical Department of Computer
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Time series prediction
 Chapter 13 Time series prediction Amaury Lendasse, Timo Honkela, Federico Pouzols, Antti Sorjamaa, Yoan Miche, Qi Yu, Eric Severin, Mark van Heeswijk, Erkki Oja, Francesco Corona, Elia Liitiäinen, Zhanxing
Chapter 13 Time series prediction Amaury Lendasse, Timo Honkela, Federico Pouzols, Antti Sorjamaa, Yoan Miche, Qi Yu, Eric Severin, Mark van Heeswijk, Erkki Oja, Francesco Corona, Elia Liitiäinen, Zhanxing
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Self Study Report Computer Science
 Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
Computer Science undergraduate students have access to undergraduate teaching, and general computing facilities in three buildings. Two large classrooms are housed in the Davis Centre, which hold about
Evolution of Symbolisation in Chimpanzees and Neural Nets
 Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Evolution of Symbolisation in Chimpanzees and Neural Nets Angelo Cangelosi Centre for Neural and Adaptive Systems University of Plymouth (UK) a.cangelosi@plymouth.ac.uk Introduction Animal communication
Proposal of Pattern Recognition as a necessary and sufficient principle to Cognitive Science
 Proposal of Pattern Recognition as a necessary and sufficient principle to Cognitive Science Gilberto de Paiva Sao Paulo Brazil (May 2011) gilbertodpaiva@gmail.com Abstract. Despite the prevalence of the
Proposal of Pattern Recognition as a necessary and sufficient principle to Cognitive Science Gilberto de Paiva Sao Paulo Brazil (May 2011) gilbertodpaiva@gmail.com Abstract. Despite the prevalence of the
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
CAFE ESSENTIAL ELEMENTS O S E P P C E A. 1 Framework 2 CAFE Menu. 3 Classroom Design 4 Materials 5 Record Keeping
 CAFE RE P SU C 3 Classroom Design 4 Materials 5 Record Keeping P H ND 1 Framework 2 CAFE Menu R E P 6 Assessment 7 Choice 8 Whole-Group Instruction 9 Small-Group Instruction 10 One-on-one Instruction 11
CAFE RE P SU C 3 Classroom Design 4 Materials 5 Record Keeping P H ND 1 Framework 2 CAFE Menu R E P 6 Assessment 7 Choice 8 Whole-Group Instruction 9 Small-Group Instruction 10 One-on-one Instruction 11
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Knowledge-Based - Systems
 Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
Knowledge-Based - Systems ; Rajendra Arvind Akerkar Chairman, Technomathematics Research Foundation and Senior Researcher, Western Norway Research institute Priti Srinivas Sajja Sardar Patel University
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence
 Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Test Effort Estimation Using Neural Network
 J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
J. Software Engineering & Applications, 2010, 3: 331-340 doi:10.4236/jsea.2010.34038 Published Online April 2010 (http://www.scirp.org/journal/jsea) 331 Chintala Abhishek*, Veginati Pavan Kumar, Harish
EdX Learner s Guide. Release
 EdX Learner s Guide Release Nov 18, 2017 Contents 1 Welcome! 1 1.1 Learning in a MOOC........................................... 1 1.2 If You Have Questions As You Take a Course..............................
EdX Learner s Guide Release Nov 18, 2017 Contents 1 Welcome! 1 1.1 Learning in a MOOC........................................... 1 1.2 If You Have Questions As You Take a Course..............................
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
Agents and environments. Intelligent Agents. Reminders. Vacuum-cleaner world. Outline. A vacuum-cleaner agent. Chapter 2 Actuators
 s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs
s and environments Percepts Intelligent s? Chapter 2 Actions s include humans, robots, softbots, thermostats, etc. The agent function maps from percept histories to actions: f : P A The agent program runs