Learning Policies by Imitating Optimal Control. CS : Deep Reinforcement Learning Week 3, Lecture 2 Sergey Levine
|
|
|
- Claire Parks
- 6 years ago
- Views:
Transcription
1 Learning Policies by Imitating Optimal Control CS : Deep Reinforcement Learning Week 3, Lecture 2 Sergey Levine
2 Overview 1. Last time: learning models of system dynamics and using optimal control to choose actions Global models and model-based RL Local models and model-based RL with constraints 2. What if we want a policy? Much quicker to evaluate actions at runtime Potentially better generalization 3. Can we just backpropagate into the policy? 4. How does this relate to imitation learning?
3 Today s Lecture 1. Backpropagating into a policy with learned models 2. How this becomes equivalent to imitating optimal control 3. The guided policy search algorithm 4. Imitating optimal control with DAgger 5. Limitations & considerations Goals Understand how to train policies using optimal control Understand tradeoffs between various methods
 But what if we want a policy? Don t need to replan (faster) Potentially better generalization (e.g. gaze heuristic)")
4 So how can we train policies? So far we saw how we can Train global models (e.g. GPs) Train local models (e.g. linear models) Combine global and local models (e.g. using Bayesian linear regression) But what if we want a policy? Don t need to replan (faster) Potentially better generalization (e.g. gaze heuristic)
5 Backpropagate directly into the policy? backprop backprop backprop easy for deterministic policies, but also possible for stochastic policy (more on this later)
6 What s the problem with backprop into policy? backprop backprop backprop big gradients here small gradients here
7 What s the problem? backprop backprop backprop
8 What s the problem? backprop backprop backprop Similar parameter sensitivity problems as shooting methods But no longer have convenient second order LQR-like method, because policy parameters couple all the time steps, so no dynamic programming Similar problems to training long RNNs with BPTT Vanishing and exploding gradients Unlike LSTM, we can t just choose a simple dynamics, dynamics are chosen by nature
9 What s the problem? What about collocation methods?
10 What s the problem? What about collocation methods?

11 Even simpler generic trajectory optimization, solve however you want How can we impose constraints on trajectory optimization?


12 Review: dual gradient descent
13 A small tweak to DGD: augmented Lagrangian Still converges to correct solution When far from solution, quadratic term tends to improve stability Closely related to alternating direction method of multipliers (ADMM)

14 Constraining trajectory optimization with dual gradient descent
15 Constraining trajectory optimization with dual gradient descent
16 Guided policy search discussion Can be interpreted as constrained trajectory optimization method Can be interpreted as imitation of an optimal control expert, since step 2 is just supervised learning The optimal control teacher adapts to the learner, and avoids actions that the learner can t mimic
17 General guided policy search scheme
18 Stochastic (Gaussian) GPS
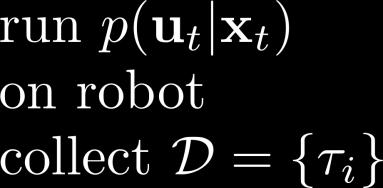

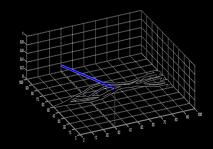
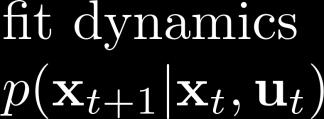
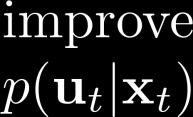
19 Stochastic (Gaussian) GPS with local models






20 Robotics Example trajectory-centric RL supervised learning
21 Input Remapping Trick training time test time

22 CNN Vision-Based Policy
23 Case study: vision-based control with GPS
24 Case study: vision-based control with GPS

25 Imitating optimal control with DAgger

26 A problem with DAgger

27 Imitating MPC: PLATO algorithm Kahn, Zhang, Levine, Abbeel 16
28 Imitating MPC: PLATO algorithm path replanned!
29 Imitating MPC: PLATO algorithm
30 Imitating MPC: PLATO algorithm
31 Imitating MPC: PLATO algorithm
32 Imitating MPC: PLATO algorithm
33 Imitating MPC: PLATO algorithm
34 Imitating MPC: PLATO algorithm

35 Imitating MPC: PLATO algorithm
36 Imitating MPC: PLATO algorithm avoids high cost! input substitution trick need state at training time but not at test time!

37 Imitating MPC: PLATO algorithm
38 DAgger vs GPS DAgger does not require an adaptive expert Any expert will do, so long as states from learned policy can be labeled Assumes it is possible to match expert s behavior up to bounded loss Not always possible (e.g. partially observed domains) GPS adapts the expert behavior Does not require bounded loss on initial expert (expert will change)
39 Why imitate optimal control? Relatively stable and easy to use Supervised learning works very well Optimal control (usually) works very well The combination of the two (usually) works very well Input remapping trick: can exploit availability of additional information at training time to learn policy from raw observations Overcomes optimization challenges of backpropagating into policy directly Usually sample-efficient and viable for real physical systems
 are not fast Sometimes fast model classes (linear models) are not expressive Some kind of additional assumptions Linearizability/continuity Ability to reset the system (for local linear models)")
40 Limitations of model-based RL Need some kind of model Not always available Sometimes harder to learn than the policy Learning the model takes time & data Sometimes expressive model classes (neural nets) are not fast Sometimes fast model classes (linear models) are not expressive Some kind of additional assumptions Linearizability/continuity Ability to reset the system (for local linear models) Smoothness (for GP-style global models) Etc.

41 Model-free RL: trial and error learning What if we didn t need a model? Intuition: trial and error learning Much slower Often more general Coming up next!
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models
 Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
Autoregressive product of multi-frame predictions can improve the accuracy of hybrid models Navdeep Jaitly 1, Vincent Vanhoucke 2, Geoffrey Hinton 1,2 1 University of Toronto 2 Google Inc. ndjaitly@cs.toronto.edu,
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Deep search. Enhancing a search bar using machine learning. Ilgün Ilgün & Cedric Reichenbach
 #BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
#BaselOne7 Deep search Enhancing a search bar using machine learning Ilgün Ilgün & Cedric Reichenbach We are not researchers Outline I. Periscope: A search tool II. Goals III. Deep learning IV. Applying
arxiv: v2 [cs.ro] 3 Mar 2017
![arxiv: v2 [cs.ro] 3 Mar 2017](/thumbs/71/66179626.jpg "arxiv: v2 [cs.ro] 3 Mar 2017") Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
Learning Feedback Terms for Reactive Planning and Control Akshara Rai 2,3,, Giovanni Sutanto 1,2,, Stefan Schaal 1,2 and Franziska Meier 1,2 arxiv:1610.03557v2 [cs.ro] 3 Mar 2017 Abstract With the advancement
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Detailed course syllabus
 Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task
 Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Transferring End-to-End Visuomotor Control from Simulation to Real World for a Multi-Stage Task Stephen James Dyson Robotics Lab Imperial College London slj12@ic.ac.uk Andrew J. Davison Dyson Robotics
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
B.S/M.A in Mathematics
 B.S/M.A in Mathematics The dual Bachelor of Science/Master of Arts in Mathematics program provides an opportunity for individuals to pursue advanced study in mathematics and to develop skills that can
B.S/M.A in Mathematics The dual Bachelor of Science/Master of Arts in Mathematics program provides an opportunity for individuals to pursue advanced study in mathematics and to develop skills that can
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures
 Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures Alex Graves and Jürgen Schmidhuber IDSIA, Galleria 2, 6928 Manno-Lugano, Switzerland TU Munich, Boltzmannstr.
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
Texas Wisconsin California Control Consortium Group Highlights
 Texas Wisconsin California Control Consortium Group Highlights James B. Rawlings Department of Chemical and Biological Engineering University of Wisconsin Madison Madison, Wisconsin September 17-18, 2012
Texas Wisconsin California Control Consortium Group Highlights James B. Rawlings Department of Chemical and Biological Engineering University of Wisconsin Madison Madison, Wisconsin September 17-18, 2012
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
An empirical study of learning speed in backpropagation
 Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
Carnegie Mellon University Research Showcase @ CMU Computer Science Department School of Computer Science 1988 An empirical study of learning speed in backpropagation networks Scott E. Fahlman Carnegie
9.85 Cognition in Infancy and Early Childhood. Lecture 7: Number
 9.85 Cognition in Infancy and Early Childhood Lecture 7: Number What else might you know about objects? Spelke Objects i. Continuity. Objects exist continuously and move on paths that are connected over
9.85 Cognition in Infancy and Early Childhood Lecture 7: Number What else might you know about objects? Spelke Objects i. Continuity. Objects exist continuously and move on paths that are connected over
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Dialog-based Language Learning
 Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Dialog-based Language Learning Jason Weston Facebook AI Research, New York. jase@fb.com arxiv:1604.06045v4 [cs.cl] 20 May 2016 Abstract A long-term goal of machine learning research is to build an intelligent
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
arxiv: v1 [cs.lg] 7 Apr 2015
![arxiv: v1 [cs.lg] 7 Apr 2015](/thumbs/71/66174892.jpg "arxiv: v1 [cs.lg] 7 Apr 2015") Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
Transferring Knowledge from a RNN to a DNN William Chan 1, Nan Rosemary Ke 1, Ian Lane 1,2 Carnegie Mellon University 1 Electrical and Computer Engineering, 2 Language Technologies Institute Equal contribution
DOCTOR OF PHILOSOPHY HANDBOOK
 University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
University of Virginia Department of Systems and Information Engineering DOCTOR OF PHILOSOPHY HANDBOOK 1. Program Description 2. Degree Requirements 3. Advisory Committee 4. Plan of Study 5. Comprehensive
A Comparison of Annealing Techniques for Academic Course Scheduling
 A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
A Comparison of Annealing Techniques for Academic Course Scheduling M. A. Saleh Elmohamed 1, Paul Coddington 2, and Geoffrey Fox 1 1 Northeast Parallel Architectures Center Syracuse University, Syracuse,
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses
 Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention
 A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
A Simple VQA Model with a Few Tricks and Image Features from Bottom-up Attention Damien Teney 1, Peter Anderson 2*, David Golub 4*, Po-Sen Huang 3, Lei Zhang 3, Xiaodong He 3, Anton van den Hengel 1 1
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Predicting Future User Actions by Observing Unmodified Applications
 From: AAAI-00 Proceedings. Copyright 2000, AAAI (www.aaai.org). All rights reserved. Predicting Future User Actions by Observing Unmodified Applications Peter Gorniak and David Poole Department of Computer
From: AAAI-00 Proceedings. Copyright 2000, AAAI (www.aaai.org). All rights reserved. Predicting Future User Actions by Observing Unmodified Applications Peter Gorniak and David Poole Department of Computer
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Texas Wisconsin California Control Consortium Group Highlights
 Texas Wisconsin California Control Consortium Group Highlights James B. Rawlings Department of Chemical and Biological Engineering University of Wisconsin Madison Los Angeles, California February 1 2,
Texas Wisconsin California Control Consortium Group Highlights James B. Rawlings Department of Chemical and Biological Engineering University of Wisconsin Madison Los Angeles, California February 1 2,
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Automatic Discretization of Actions and States in Monte-Carlo Tree Search
 Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Automatic Discretization of Actions and States in Monte-Carlo Tree Search Guy Van den Broeck 1 and Kurt Driessens 2 1 Katholieke Universiteit Leuven, Department of Computer Science, Leuven, Belgium guy.vandenbroeck@cs.kuleuven.be
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Degeneracy results in canalisation of language structure: A computational model of word learning
 Degeneracy results in canalisation of language structure: A computational model of word learning Padraic Monaghan (p.monaghan@lancaster.ac.uk) Department of Psychology, Lancaster University Lancaster LA1
Degeneracy results in canalisation of language structure: A computational model of word learning Padraic Monaghan (p.monaghan@lancaster.ac.uk) Department of Psychology, Lancaster University Lancaster LA1
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD
 TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
Evolutive Neural Net Fuzzy Filtering: Basic Description
 Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Journal of Intelligent Learning Systems and Applications, 2010, 2: 12-18 doi:10.4236/jilsa.2010.21002 Published Online February 2010 (http://www.scirp.org/journal/jilsa) Evolutive Neural Net Fuzzy Filtering:
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Navigating the PhD Options in CMS
 Navigating the PhD Options in CMS This document gives an overview of the typical student path through the four Ph.D. programs in the CMS department ACM, CDS, CS, and CMS. Note that it is not a replacement
Navigating the PhD Options in CMS This document gives an overview of the typical student path through the four Ph.D. programs in the CMS department ACM, CDS, CS, and CMS. Note that it is not a replacement
Version Space. Term 2012/2013 LSI - FIB. Javier Béjar cbea (LSI - FIB) Version Space Term 2012/ / 18
 Version Space Term 2012/ / 18") Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Version Space Javier Béjar cbea LSI - FIB Term 2012/2013 Javier Béjar cbea (LSI - FIB) Version Space Term 2012/2013 1 / 18 Outline 1 Learning logical formulas 2 Version space Introduction Search strategy
Given a directed graph G =(N A), where N is a set of m nodes and A. destination node, implying a direction for ow to follow. Arcs have limitations
, where N is a set of m nodes and A. destination node, implying a direction for ow to follow. Arcs have limitations") 4 Interior point algorithms for network ow problems Mauricio G.C. Resende AT&T Bell Laboratories, Murray Hill, NJ 07974-2070 USA Panos M. Pardalos The University of Florida, Gainesville, FL 32611-6595
4 Interior point algorithms for network ow problems Mauricio G.C. Resende AT&T Bell Laboratories, Murray Hill, NJ 07974-2070 USA Panos M. Pardalos The University of Florida, Gainesville, FL 32611-6595
Ricochet Robots - A Case Study for Human Complex Problem Solving
 Ricochet Robots - A Case Study for Human Complex Problem Solving Nicolas Butko, Katharina A. Lehmann, Veronica Ramenzoni September 15, 005 1 Introduction At the beginning of the Cognitive Revolution, stimulated
Ricochet Robots - A Case Study for Human Complex Problem Solving Nicolas Butko, Katharina A. Lehmann, Veronica Ramenzoni September 15, 005 1 Introduction At the beginning of the Cognitive Revolution, stimulated
Kamaldeep Kaur University School of Information Technology GGS Indraprastha University Delhi
 Soft Computing Approaches for Prediction of Software Maintenance Effort Dr. Arvinder Kaur University School of Information Technology GGS Indraprastha University Delhi Kamaldeep Kaur University School
Soft Computing Approaches for Prediction of Software Maintenance Effort Dr. Arvinder Kaur University School of Information Technology GGS Indraprastha University Delhi Kamaldeep Kaur University School
Deep Facial Action Unit Recognition from Partially Labeled Data
 Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN-
 LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
LEARNING TO PLAY IN A DAY: FASTER DEEP REIN- FORCEMENT LEARNING BY OPTIMALITY TIGHTENING Frank S. He Department of Computer Science University of Illinois at Urbana-Champaign Zhejiang University frankheshibi@gmail.com
AP Calculus AB. Nevada Academic Standards that are assessable at the local level only.
 Calculus AB Priority Keys Aligned with Nevada Standards MA I MI L S MA represents a Major content area. Any concept labeled MA is something of central importance to the entire class/curriculum; it is a
Calculus AB Priority Keys Aligned with Nevada Standards MA I MI L S MA represents a Major content area. Any concept labeled MA is something of central importance to the entire class/curriculum; it is a
The use of mathematical programming with artificial intelligence and expert systems
 European Journal of Operational Research 70 (1993) 1-15 North-Holland Invited Review The use of mathematical programming with artificial intelligence and expert systems Richard D. McBride and Daniel E.
European Journal of Operational Research 70 (1993) 1-15 North-Holland Invited Review The use of mathematical programming with artificial intelligence and expert systems Richard D. McBride and Daniel E.
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Adaptive Learning in Time-Variant Processes With Application to Wind Power Systems
 IEEE TRANSACTIONS ON AUTOMATION SCIENCE AND ENGINEERING, VOL 13, NO 2, APRIL 2016 997 Adaptive Learning in Time-Variant Processes With Application to Wind Power Systems Eunshin Byon, Member, IEEE, Youngjun
IEEE TRANSACTIONS ON AUTOMATION SCIENCE AND ENGINEERING, VOL 13, NO 2, APRIL 2016 997 Adaptive Learning in Time-Variant Processes With Application to Wind Power Systems Eunshin Byon, Member, IEEE, Youngjun
Mathematics process categories
 Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
Mathematics process categories All of the UK curricula define multiple categories of mathematical proficiency that require students to be able to use and apply mathematics, beyond simple recall of facts
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING. Calendar Description Units: 1.
 University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
University of Victoria School of Exercise Science, Physical and Health Education EPHE 245 MOTOR LEARNING Calendar Description Units: 1.5 Hours: 3-2 Neural and cognitive processes underlying human skilled
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems
 Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Analysis of Hybrid Soft and Hard Computing Techniques for Forex Monitoring Systems Ajith Abraham School of Business Systems, Monash University, Clayton, Victoria 3800, Australia. Email: ajith.abraham@ieee.org
Chapter 2. Intelligent Agents. Outline. Agents and environments. Rationality. PEAS (Performance measure, Environment, Actuators, Sensors)
") Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
Intelligent Agents Chapter 2 1 Outline Agents and environments Rationality PEAS (Performance measure, Environment, Actuators, Sensors) Agent types 2 Agents and environments sensors environment percepts
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Data Fusion Through Statistical Matching
 A research and education initiative at the MIT Sloan School of Management Data Fusion Through Statistical Matching Paper 185 Peter Van Der Puttan Joost N. Kok Amar Gupta January 2002 For more information,
A research and education initiative at the MIT Sloan School of Management Data Fusion Through Statistical Matching Paper 185 Peter Van Der Puttan Joost N. Kok Amar Gupta January 2002 For more information,
Second Exam: Natural Language Parsing with Neural Networks
 Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Second Exam: Natural Language Parsing with Neural Networks James Cross May 21, 2015 Abstract With the advent of deep learning, there has been a recent resurgence of interest in the use of artificial neural
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Getting Started with Deliberate Practice
 Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Getting Started with Deliberate Practice Most of the implementation guides so far in Learning on Steroids have focused on conceptual skills. Things like being able to form mental images, remembering facts
Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors
 Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence (IJCAI-6) Dual-Memory Deep Learning Architectures for Lifelong Learning of Everyday Human Behaviors Sang-Woo Lee,
Knowledge Transfer in Deep Convolutional Neural Nets
 Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
Knowledge Transfer in Deep Convolutional Neural Nets Steven Gutstein, Olac Fuentes and Eric Freudenthal Computer Science Department University of Texas at El Paso El Paso, Texas, 79968, U.S.A. Abstract
How to analyze visual narratives: A tutorial in Visual Narrative Grammar
 How to analyze visual narratives: A tutorial in Visual Narrative Grammar Neil Cohn 2015 neilcohn@visuallanguagelab.com www.visuallanguagelab.com Abstract Recent work has argued that narrative sequential
How to analyze visual narratives: A tutorial in Visual Narrative Grammar Neil Cohn 2015 neilcohn@visuallanguagelab.com www.visuallanguagelab.com Abstract Recent work has argued that narrative sequential
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING
 SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
SEMI-SUPERVISED ENSEMBLE DNN ACOUSTIC MODEL TRAINING Sheng Li 1, Xugang Lu 2, Shinsuke Sakai 1, Masato Mimura 1 and Tatsuya Kawahara 1 1 School of Informatics, Kyoto University, Sakyo-ku, Kyoto 606-8501,
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
A theoretic and practical framework for scheduling in a stochastic environment
 J Sched (2009) 12: 315 344 DOI 10.1007/s10951-008-0080-x A theoretic and practical framework for scheduling in a stochastic environment Julien Bidot Thierry Vidal Philippe Laborie J. Christopher Beck Received:
J Sched (2009) 12: 315 344 DOI 10.1007/s10951-008-0080-x A theoretic and practical framework for scheduling in a stochastic environment Julien Bidot Thierry Vidal Philippe Laborie J. Christopher Beck Received:
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS. Heiga Zen, Haşim Sak
 UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
UNIDIRECTIONAL LONG SHORT-TERM MEMORY RECURRENT NEURAL NETWORK WITH RECURRENT OUTPUT LAYER FOR LOW-LATENCY SPEECH SYNTHESIS Heiga Zen, Haşim Sak Google fheigazen,hasimg@google.com ABSTRACT Long short-term
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes
 Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Rover Races Grades: 3-5 Prep Time: ~45 Minutes Lesson Time: ~105 minutes WHAT STUDENTS DO: Establishing Communication Procedures Following Curiosity on Mars often means roving to places with interesting
Residual Stacking of RNNs for Neural Machine Translation
 Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp
Residual Stacking of RNNs for Neural Machine Translation Raphael Shu The University of Tokyo shu@nlab.ci.i.u-tokyo.ac.jp Akiva Miura Nara Institute of Science and Technology miura.akiba.lr9@is.naist.jp