TOWARDS DATA-DRIVEN AUTONOMICS IN DATA CENTERS
|
|
|
- Dana Franklin
- 6 years ago
- Views:
Transcription
1 TOWARDS DATA-DRIVEN AUTONOMICS IN DATA CENTERS ALINA SIRBU, OZALP BABAOGLU SUMMARIZED BY ARDA GUMUSALAN
2 MOTIVATION 2
3 MOTIVATION Human-interaction-dependent data centers are not sustainable for future data centers which are expected to be bigger scale than todays data centers. Exascale-> billion of billion servers per data center. Unreasonable number of employee to oversee the system. Data centers in the future will fully be autonomic and human technicians will be limited to setting high-level goals and policies. No more low-level operations Level 5 of A survey of autonomic computing-degrees, models, and applications 3
4 MOTIVATION Applying traditional autonomic computing techniques to large data centers are problematic. Current autonomic computing technologies are reactive. They lack predictive capabilities to anticipate undesired states in advance. 4
5 GOAL AND CONTRIBUTION 5
6 GOAL Build a predictive model for node failures in data centers. Develop a new generation of autonomics that is data-driven, predictive, and proactive based on holistic models which considers computer systems as an ecosystem. This is the first step towards a more comprehensive predictor. 6
7 CONTRIBUTION Shows that modern data centers can be scaled to extreme dimensions by eliminating its reliance on human operators. Provide a prediction model. Combining subsampling with bagging and prediction based voting. Will be explained in the upcoming slides. Provide an example of BigQuery usage with quantitative evaluation of running times as a function of data size. Computation times will be included. Data mining related parts are not directly related to autonomic computing so some parts will be omitted. 7
8 BACKGROUND 8
9 RANDOM FOREST A technique that is commonly applied when the feature set is large or the data is unbalanced. Main idea: Ensemble weaklearners to form a strong learner. Weak-learner is a decision tree 9
10 RANDOM FOREST 1. Sample N cases at random with replacement to create a subset of the data. This is called bagging. 2. At each node: 1. Randomly chose m predictor variables from all predictor variables. 2. Determine the predictors that give the best binary split according to some objective function. 3. At the next node, choose another m variables at random from all predictor variables and do the same. 10
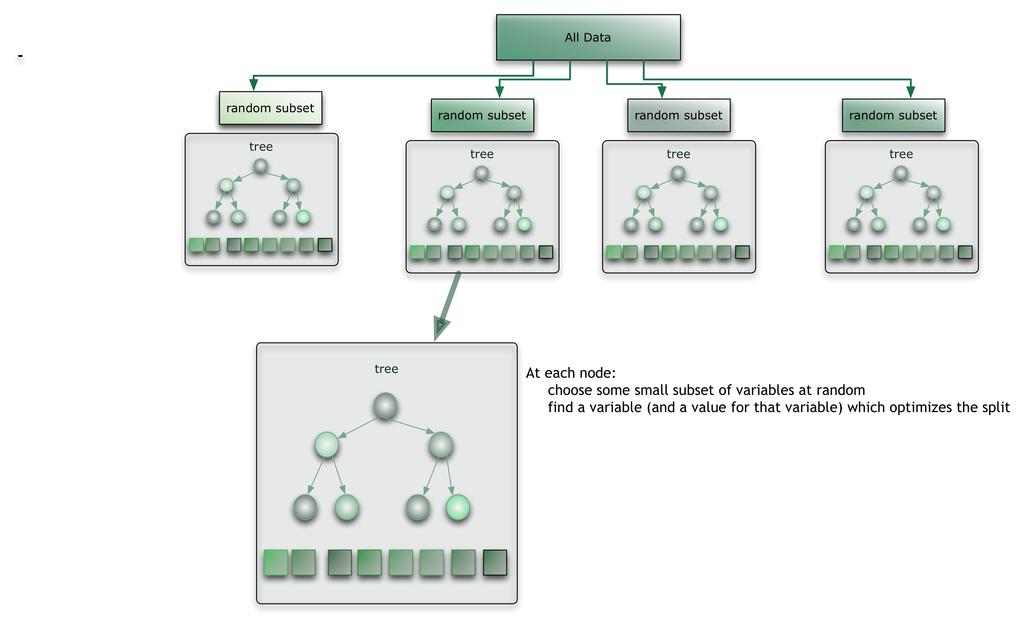
11 11 RANDOM FOREST
12 RANDOM FOREST When a new input is entered to the system: Run it on all of the trees. The result can be obtained as: Average or weighted average the results of each tree. Majority voting. In order to have accurate results, inter-tree correlation should be low. Tradeoff: smaller m leads to lower inter-tree correlation but also lowers strength of an individual tree. 12
13 BUILDING THE FEATURE SET 13
14 FEATURE SET The workload trace published by Google has been analyzed. 29 days for a cluster of 12,453 machines. Includes: amount of resources used per task for every 5 minute intervals. Due to the size of uncompressed data, the authors used BigQuery. 17 GB for over 1 billion records. 14
15 BASIC FEATURES Basic features obtained for each machine for every 5 minute interval: Number of tasks currently running, Number of tasks that have started in the last 5 minutes, Number of tasks that have finished, Evicted Failed Completed Killed Lost CPU load, Memory, Disk time, Cycles per instruction, Memory access per instruction. Total of 12 basic features. 15
16 BASIC FEATURES For each 12 basic feature for each time step: Consider the previous 6 time windows (30 minutes) 12 x 6 = 72 features in total A separate table per feature. First 5 features took between 139 to 939 seconds. The remaining took 3585 to 9096 seconds. 16
17 SECOND LEVEL AGGREGATION A second level of aggregation for each basic feature compute: Averages, Standard deviation, Coefficient of variation. Repeat this for 6 different running window sizes: 1, 12, 24, 48, 72, 96 hours. 3 statistics x 12 basic features x 6 window sizes = 216 additional features. The sizes of these tables were ranging between 143 GB to 12.5 TB However, not time consuming. 17
18 THIRD LEVEL OF AGGREGATION Compute the correlation between for following 7 features: Number of running tasks, Number of started tasks, Number of failed jobs, CPU Memory Disk time, Cycles per instruction. A total of 21 correlation pairs. Calculate this for each 6 of the time windows. 1, 12, 24, 48, 72, 96 hours. Additional 21x6=126 features. 18
 of the required times per")
19 RUNNING TIMES The tables shows the mean(the standard deviation) of the required times per feature. 19
20 ADDITIONAL FEATURES 2 new features are added. Up-time for each machine The time passed since the last ADD event The number of REMOVE events for the entire cluster within the last hour. A total of 416 features. 20
21 21
22 CLASSIFICATION APPROACH 22
23 CLASSIFICATION APPROACH The features explained so far are used for classification with Random Forest (RF) classifier. Data points are separated into two parts: SAFE: did not fail -> negative FAIL: failed -> positive All points with time to remove less than 24 hours were assigned to FAIL class. If the gap between REMOVE and ADD event for the same machine was longer than 2 hours, it counted as a failure. Out of 8,957 REMOVE events, 2,298 were considered as failure. Subset of SAFE classes were extracted. 0.5% of the total random sampling Due to imbalanced data points. A total of 544,985 SAFE data points and 108,365 FAIL data points. These 653,350 data points formed the basis of their predictive study. 23
24 FEATURE SELECTION MECHANISMS The authors explored two types of future selection mechanism: Principal component analysis: a statistical procedure that converts a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principle components. Theoretically, the top principle components can be used for classification, since those should contain the most important information. However, the performance of principle components were not better than using original features. 24
25 FEATURE SELECTION MECHANISMS Filtering the original features: Filter the original features based on their correlation to the time_to_remove event. Only the correlation values greater than a threshold is used. The best performance was obtained with null threshold indicating that once again the best results were obtained using all the features. None of the feature selection mechanisms performed better than the RF with the original features. RF itself performs feature selection when building decision trees. 25
26 BUILDING THE ENSEMBLE OF RF 26
27 BUILDING THE ENSEMBLE OF RF The authors observed that the performance of individual classifiers (a single RF) was not satisfactory. They combined RFs to form a forest of forests. A known technique especially for imbalanced with rare events. Each RF had a varying number of decision trees -> between 2 and 15 Each RF trained with different data -> bagging Every time a new classifier is trained, a new training dataset is built by considering all the points in the positive class and a random subset of the negative class. fsafe: the ratio between SAFE and FAIL classes. {0.25, 0.5, 1, 2, 3, 4} 27
28 BUILDING THE ENSEMBLE OF RF Repeat the algorithm 5 times resulting in 420 RF in the ensemble. 5 reps x 6 fsafe x 14 RF size 28
29 COMBINING STRATEGY Precision weighted voting: calculate the accuracy of each classifier on training data. Divide the test data into two halves: Individual test: used to evaluate the precision of individual classifiers and and calculate their weights. Ensemble test: used to calculate the final evaluation of the ensemble. Precision is the fraction of points labeled fail is actually a failure. 29
30 COMBINING STRATEGY The classification of the ensemble is computed as the sum of all individual answers multiplied by their precision. Each individual answer is a discrete value but combination of them is continuous. Higher score indicates a higher probability of failure. For all data points, there is a score 30
31 CLASSIFICATION RESULTS 31

32 CROSS VALIDATION APPROACH The authors separated their data as train and test data. Train over 10 days and test on the 12 th. First two days are omitted in order to decrease the effect on aggregated features. Mimics how this model should be used in real life scenarios. Took up to 9 hours with a relatively low spec computer. 32
33 CROSS VALIDATION APPROACH PR: Precision vs. Recall. Precision: positive predictive value. Recall: sensitivity Ex: Suppose a program for recognizing dogs in scenes from a video that contains dogs and cats. There are a total of 9 dogs and some cats. Our program identifies 7 of the animals as dogs but only 4 out of those 7 are actually dogs. Precision:4/7 Recall: 4/9 33
34 CLASSIFICATION RESULTS Evaluation was based on receiver operating characteristics (ROC) and precision recall (PR) curves. ROC curves plot True Positive Rate (TPR) versus False Positive Rate (FPR). PR curve displays the precision vs. recall which is equal to TPR. For both, the higher the value, the better it is. A threshold value, s*, is needed to classify the score of the ensemble RF. By decreasing s* the number of true positives grows but so do the false positive. 34

35 CLASSIFICATION RESULTS For all days, AUROC values are greater than 0.75 and up to 0.97 AUPR ranges between 0.38 and 0.87 Lower performance at the beginning can be due to fact that some of the aggregated data were incomplete (for those over 3 and 4 days). 35
36 MORE DETAILED LOOK Performance of individual classifiers are displayed. Very low FPR-> good! In many cases, very low TPR-> bad! 36
37 MORE DETAILED LOOK TPR increases when the fsafe parameter decreases But FPR increases and precision decreases. The results obtained with different fsafe values are diverse which means it is suitable to use with ensemble approaches. In general, the points corresponding to the individual classifiers are below the ROC and PR curves describing the performance of the ensemble. This proves that the ensemble method is better than the individual classifiers. Except for TPR less than
38 CLASSIFICATION RESULTS Conclusion: Recall (TPR) rate is between 27.2% and 88.6% (lowest and highest). This means 27.2%-88.6% of the failures were identified successfully. Precision: From all instances labeled as failure, between 50.2% and 72.8% are actual failures (FPR). 38
39 TIME_TO_NEXT_FAILURE ANALYSIS 39
40 TIME_TO_NEXT_FAILURE ANALYSIS The authors analyzed the relation between the classifier label and the exact time until the next REMOVE event. 24 hours away point was considered SAFE. It would be considered SAFE if it fails in 2 days. Also, no difference between failing in 10 minutes vs. in 24 hours. SAFE classified as FAIL counts less as a misclassification as the time to next failure decreases. FAIL classified as SAFE has a higher negative impact when it is close to the point of failure. These will be clear in the next slide. 40
41 TIME_TO_NEXT_FAILURE ANALYSIS Because of the fact the authors used 24 hours as the threshold value, when the classifier gives the wrong output, we still have time to catch it before the FAIL occurs. A good result: if the misclassified positives (actual failures labeled as SAFE) are further in time from the point of failure compared to correctly classified failures. If we do not miss the closer failures but miss the further ones then it is good. We will have some time catch it again. Another good result: if misclassified negatives (actual safes labeled as FAIL) are closer to the failure point compared to correctly classified negatives. If we misclassify closer SAFEs (they will eventually fail after 24 hours) compared to further away misclassified SAFEs, then our prediction makes more sense. 41

42 TIME_TO_NEXT_FAILURE ANALYSIS The outputs are divided into: TP: failures correctly identified FN: failures missed Upper and lower limits are 0 to 24 as expected. TP, on average, has lower times until the next event compared to FN. This is good news: there is still some time left to actual failure so classifier may detect this in the future. If we take this into account, the lowest prediction goes from 27.2% to 52.5% for benchmark 4 and from 88.6% to 88.8% for benchmark
43 TIME_TO_NEXT_FAILURE ANALYSIS The outputs are divided into : FP: SAFE labeled as FAIL TN: SAFE labeled as SAFE IMPORTANT: but they will eventually fail. The time_to_the_next_failure, on average, are lower for FP than TN. This is good news: the classifier gives false alarms when a failure is approaching, even if it is not strictly in the next 24 hours. 43
44 ADAPTATIONS FOR REAL LIFE USAGE 44
45 PERFORMING ONLINE All features need to be computed online. Computation needs to take less than 5 minutes. Data aggregation is embarrassingly parallel. All independent. The cost of storing the data and using BigQuery for analysis is estimated to be 60 dollars per day. Training each RF is also embarrassingly parallel. It is estimated 5 minutes to update their models. 45
46 CRITIQUE 46
47 CRITIQUE The cost analysis of missed FAILS plus misclassified FAILS vs. not using their model? Performance of difference features are no presented. How did we sampled two halves of test data (individual, ensemble). Same with training data or separate. The threshold value analysis of ensemble output is omitted. 47
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Linking the Ohio State Assessments to NWEA MAP Growth Tests *
 Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Probability and Statistics Curriculum Pacing Guide
 Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Unit 1 Terms PS.SPMJ.3 PS.SPMJ.5 Plan and conduct a survey to answer a statistical question. Recognize how the plan addresses sampling technique, randomization, measurement of experimental error and methods
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
CHAPTER 4: REIMBURSEMENT STRATEGIES 24
 CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Build on students informal understanding of sharing and proportionality to develop initial fraction concepts.
 Recommendation 1 Build on students informal understanding of sharing and proportionality to develop initial fraction concepts. Students come to kindergarten with a rudimentary understanding of basic fraction
Recommendation 1 Build on students informal understanding of sharing and proportionality to develop initial fraction concepts. Students come to kindergarten with a rudimentary understanding of basic fraction
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations
 Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
Evidence for Reliability, Validity and Learning Effectiveness
 PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and
 A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
A Decision Tree Analysis of the Transfer Student Emma Gunu, MS Research Analyst Robert M Roe, PhD Executive Director of Institutional Research and Planning Overview Motivation for Analyses Analyses and
On-the-Fly Customization of Automated Essay Scoring
 Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011
 Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
Grade 6: Correlated to AGS Basic Math Skills
 Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Grade 6: Correlated to AGS Basic Math Skills Grade 6: Standard 1 Number Sense Students compare and order positive and negative integers, decimals, fractions, and mixed numbers. They find multiples and
Simple Random Sample (SRS) & Voluntary Response Sample: Examples: A Voluntary Response Sample: Examples: Systematic Sample Best Used When
 & Voluntary Response Sample: Examples: A Voluntary Response Sample: Examples: Systematic Sample Best Used When") Simple Random Sample (SRS) & Voluntary Response Sample: In statistics, a simple random sample is a group of people who have been chosen at random from the general population. A simple random sample is
Simple Random Sample (SRS) & Voluntary Response Sample: In statistics, a simple random sample is a group of people who have been chosen at random from the general population. A simple random sample is
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
ECE-492 SENIOR ADVANCED DESIGN PROJECT
 ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
ECE-492 SENIOR ADVANCED DESIGN PROJECT Meeting #3 1 ECE-492 Meeting#3 Q1: Who is not on a team? Q2: Which students/teams still did not select a topic? 2 ENGINEERING DESIGN You have studied a great deal
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Understanding and Interpreting the NRC s Data-Based Assessment of Research-Doctorate Programs in the United States (2010)
") Understanding and Interpreting the NRC s Data-Based Assessment of Research-Doctorate Programs in the United States (2010) Jaxk Reeves, SCC Director Kim Love-Myers, SCC Associate Director Presented at UGA
Understanding and Interpreting the NRC s Data-Based Assessment of Research-Doctorate Programs in the United States (2010) Jaxk Reeves, SCC Director Kim Love-Myers, SCC Associate Director Presented at UGA
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Extending Place Value with Whole Numbers to 1,000,000
 Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Grade 4 Mathematics, Quarter 1, Unit 1.1 Extending Place Value with Whole Numbers to 1,000,000 Overview Number of Instructional Days: 10 (1 day = 45 minutes) Content to Be Learned Recognize that a digit
Measurement. When Smaller Is Better. Activity:
 Measurement Activity: TEKS: When Smaller Is Better (6.8) Measurement. The student solves application problems involving estimation and measurement of length, area, time, temperature, volume, weight, and
Measurement Activity: TEKS: When Smaller Is Better (6.8) Measurement. The student solves application problems involving estimation and measurement of length, area, time, temperature, volume, weight, and
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape
 Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Lip reading: Japanese vowel recognition by tracking temporal changes of lip shape Koshi Odagiri 1, and Yoichi Muraoka 1 1 Graduate School of Fundamental/Computer Science and Engineering, Waseda University,
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Instructor: Mario D. Garrett, Ph.D. Phone: Office: Hepner Hall (HH) 100
 100") San Diego State University School of Social Work 610 COMPUTER APPLICATIONS FOR SOCIAL WORK PRACTICE Statistical Package for the Social Sciences Office: Hepner Hall (HH) 100 Instructor: Mario D. Garrett,
San Diego State University School of Social Work 610 COMPUTER APPLICATIONS FOR SOCIAL WORK PRACTICE Statistical Package for the Social Sciences Office: Hepner Hall (HH) 100 Instructor: Mario D. Garrett,
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C
 Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Numeracy Medium term plan: Summer Term Level 2C/2B Year 2 Level 2A/3C Using and applying mathematics objectives (Problem solving, Communicating and Reasoning) Select the maths to use in some classroom
Individual Component Checklist L I S T E N I N G. for use with ONE task ENGLISH VERSION
 L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
L I S T E N I N G Individual Component Checklist for use with ONE task ENGLISH VERSION INTRODUCTION This checklist has been designed for use as a practical tool for describing ONE TASK in a test of listening.
Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation
 School of Computer Science Human-Computer Interaction Institute Carnegie Mellon University Year 2007 Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation Noboru Matsuda
School of Computer Science Human-Computer Interaction Institute Carnegie Mellon University Year 2007 Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation Noboru Matsuda
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
Pre-Algebra A. Syllabus. Course Overview. Course Goals. General Skills. Credit Value
 Syllabus Pre-Algebra A Course Overview Pre-Algebra is a course designed to prepare you for future work in algebra. In Pre-Algebra, you will strengthen your knowledge of numbers as you look to transition
Syllabus Pre-Algebra A Course Overview Pre-Algebra is a course designed to prepare you for future work in algebra. In Pre-Algebra, you will strengthen your knowledge of numbers as you look to transition
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Multi-label classification via multi-target regression on data streams
 Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Mach Learn (2017) 106:745 770 DOI 10.1007/s10994-016-5613-5 Multi-label classification via multi-target regression on data streams Aljaž Osojnik 1,2 Panče Panov 1 Sašo Džeroski 1,2,3 Received: 26 April
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Modeling user preferences and norms in context-aware systems
 Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
Modeling user preferences and norms in context-aware systems Jonas Nilsson, Cecilia Lindmark Jonas Nilsson, Cecilia Lindmark VT 2016 Bachelor's thesis for Computer Science, 15 hp Supervisor: Juan Carlos
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Bayllocator: A proactive system to predict server utilization and dynamically allocate memory resources using Bayesian networks and ballooning
 Bayllocator: A proactive system to predict server utilization and dynamically allocate memory resources using Bayesian networks and ballooning Evangelos Tasoulas - University of Oslo Hårek Haugerud - Oslo
Bayllocator: A proactive system to predict server utilization and dynamically allocate memory resources using Bayesian networks and ballooning Evangelos Tasoulas - University of Oslo Hårek Haugerud - Oslo
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Unit 3 Ratios and Rates Math 6
 Number of Days: 20 11/27/17 12/22/17 Unit Goals Stage 1 Unit Description: Students study the concepts and language of ratios and unit rates. They use proportional reasoning to solve problems. In particular,
Number of Days: 20 11/27/17 12/22/17 Unit Goals Stage 1 Unit Description: Students study the concepts and language of ratios and unit rates. They use proportional reasoning to solve problems. In particular,
Why Did My Detector Do That?!
 Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Why Did My Detector Do That?! Predicting Keystroke-Dynamics Error Rates Kevin Killourhy and Roy Maxion Dependable Systems Laboratory Computer Science Department Carnegie Mellon University 5000 Forbes Ave,
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio
 SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
Common Core Standards Alignment Chart Grade 5
 Common Core Standards Alignment Chart Grade 5 Units 5.OA.1 5.OA.2 5.OA.3 5.NBT.1 5.NBT.2 5.NBT.3 5.NBT.4 5.NBT.5 5.NBT.6 5.NBT.7 5.NF.1 5.NF.2 5.NF.3 5.NF.4 5.NF.5 5.NF.6 5.NF.7 5.MD.1 5.MD.2 5.MD.3 5.MD.4
Common Core Standards Alignment Chart Grade 5 Units 5.OA.1 5.OA.2 5.OA.3 5.NBT.1 5.NBT.2 5.NBT.3 5.NBT.4 5.NBT.5 5.NBT.6 5.NBT.7 5.NF.1 5.NF.2 5.NF.3 5.NF.4 5.NF.5 5.NF.6 5.NF.7 5.MD.1 5.MD.2 5.MD.3 5.MD.4
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
STT 231 Test 1. Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point.
 STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
STT 231 Test 1 Fill in the Letter of Your Choice to Each Question in the Scantron. Each question is worth 2 point. 1. A professor has kept records on grades that students have earned in his class. If he
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method
 Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Malicious User Suppression for Cooperative Spectrum Sensing in Cognitive Radio Networks using Dixon s Outlier Detection Method Sanket S. Kalamkar and Adrish Banerjee Department of Electrical Engineering
Interpreting ACER Test Results
 Interpreting ACER Test Results This document briefly explains the different reports provided by the online ACER Progressive Achievement Tests (PAT). More detailed information can be found in the relevant
Interpreting ACER Test Results This document briefly explains the different reports provided by the online ACER Progressive Achievement Tests (PAT). More detailed information can be found in the relevant
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
(Includes a Detailed Analysis of Responses to Overall Satisfaction and Quality of Academic Advising Items) By Steve Chatman
 By Steve Chatman") Report #202-1/01 Using Item Correlation With Global Satisfaction Within Academic Division to Reduce Questionnaire Length and to Raise the Value of Results An Analysis of Results from the 1996 UC Survey
Report #202-1/01 Using Item Correlation With Global Satisfaction Within Academic Division to Reduce Questionnaire Length and to Raise the Value of Results An Analysis of Results from the 1996 UC Survey
Primary National Curriculum Alignment for Wales
 Mathletics and the Welsh Curriculum This alignment document lists all Mathletics curriculum activities associated with each Wales course, and demonstrates how these fit within the National Curriculum Programme
Mathletics and the Welsh Curriculum This alignment document lists all Mathletics curriculum activities associated with each Wales course, and demonstrates how these fit within the National Curriculum Programme
Chapters 1-5 Cumulative Assessment AP Statistics November 2008 Gillespie, Block 4
 Chapters 1-5 Cumulative Assessment AP Statistics Name: November 2008 Gillespie, Block 4 Part I: Multiple Choice This portion of the test will determine 60% of your overall test grade. Each question is
Chapters 1-5 Cumulative Assessment AP Statistics Name: November 2008 Gillespie, Block 4 Part I: Multiple Choice This portion of the test will determine 60% of your overall test grade. Each question is
SETTING STANDARDS FOR CRITERION- REFERENCED MEASUREMENT
 SETTING STANDARDS FOR CRITERION- REFERENCED MEASUREMENT By: Dr. MAHMOUD M. GHANDOUR QATAR UNIVERSITY Improving human resources is the responsibility of the educational system in many societies. The outputs
SETTING STANDARDS FOR CRITERION- REFERENCED MEASUREMENT By: Dr. MAHMOUD M. GHANDOUR QATAR UNIVERSITY Improving human resources is the responsibility of the educational system in many societies. The outputs
STA 225: Introductory Statistics (CT)
") Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Marshall University College of Science Mathematics Department STA 225: Introductory Statistics (CT) Course catalog description A critical thinking course in applied statistical reasoning covering basic
Grade Dropping, Strategic Behavior, and Student Satisficing
 Grade Dropping, Strategic Behavior, and Student Satisficing Lester Hadsell Department of Economics State University of New York, College at Oneonta Oneonta, NY 13820 hadsell@oneonta.edu Raymond MacDermott
Grade Dropping, Strategic Behavior, and Student Satisficing Lester Hadsell Department of Economics State University of New York, College at Oneonta Oneonta, NY 13820 hadsell@oneonta.edu Raymond MacDermott
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS
 METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
METHODS FOR EXTRACTING AND CLASSIFYING PAIRS OF COGNATES AND FALSE FRIENDS Ruslan Mitkov (R.Mitkov@wlv.ac.uk) University of Wolverhampton ViktorPekar (v.pekar@wlv.ac.uk) University of Wolverhampton Dimitar
Edexcel GCSE. Statistics 1389 Paper 1H. June Mark Scheme. Statistics Edexcel GCSE
 Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Edexcel GCSE Statistics 1389 Paper 1H June 2007 Mark Scheme Edexcel GCSE Statistics 1389 NOTES ON MARKING PRINCIPLES 1 Types of mark M marks: method marks A marks: accuracy marks B marks: unconditional
Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge
 Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question.
 Ch 2 Test Remediation Work Name MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. Provide an appropriate response. 1) High temperatures in a certain
Ch 2 Test Remediation Work Name MULTIPLE CHOICE. Choose the one alternative that best completes the statement or answers the question. Provide an appropriate response. 1) High temperatures in a certain
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models
 What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
What Different Kinds of Stratification Can Reveal about the Generalizability of Data-Mined Skill Assessment Models Michael A. Sao Pedro Worcester Polytechnic Institute 100 Institute Rd. Worcester, MA 01609
Essentials of Ability Testing. Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology
 Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Essentials of Ability Testing Joni Lakin Assistant Professor Educational Foundations, Leadership, and Technology Basic Topics Why do we administer ability tests? What do ability tests measure? How are
Ricopili: Postimputation Module. WCPG Education Day Stephan Ripke / Raymond Walters Toronto, October 2015
 Ricopili: Postimputation Module WCPG Education Day Stephan Ripke / Raymond Walters Toronto, October 2015 Ricopili Overview Ricopili Overview postimputation, 12 steps 1) Association analysis 2) Meta analysis
Ricopili: Postimputation Module WCPG Education Day Stephan Ripke / Raymond Walters Toronto, October 2015 Ricopili Overview Ricopili Overview postimputation, 12 steps 1) Association analysis 2) Meta analysis
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany
 Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Automatic Pronunciation Checker
 Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
Institut für Technische Informatik und Kommunikationsnetze Eidgenössische Technische Hochschule Zürich Swiss Federal Institute of Technology Zurich Ecole polytechnique fédérale de Zurich Politecnico federale
PUBLIC CASE REPORT Use of the GeoGebra software at upper secondary school
 PUBLIC CASE REPORT Use of the GeoGebra software at upper secondary school Linked to the pedagogical activity: Use of the GeoGebra software at upper secondary school Written by: Philippe Leclère, Cyrille
PUBLIC CASE REPORT Use of the GeoGebra software at upper secondary school Linked to the pedagogical activity: Use of the GeoGebra software at upper secondary school Written by: Philippe Leclère, Cyrille
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand
 Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student
Grade 2: Using a Number Line to Order and Compare Numbers Place Value Horizontal Content Strand Texas Essential Knowledge and Skills (TEKS): (2.1) Number, operation, and quantitative reasoning. The student