Probabilistic Graphical Models
|
|
|
- Emery Rose
- 6 years ago
- Views:
Transcription

 Lecture 29, April 30,")
1 School of Computer Science Probabilistic Graphical Models Posterior Regularization: an integrative paradigm for learning GMs p Eric Xing (courtesy to Jun Zhu) Lecture 29, April 30, 2014 Reading: 1
2 Learning GMs Prior knowledge, bypass model selection, Data integration, scalable inference nonlinear transformation rich forms of data Max-margin learning generalization dual sparsity efficient solvers Regularized Bayesian Inference 2
 Bayes rule offers a mathematically rigorous computational mechanism for combining prior knowledge with incoming")
3 Bayesian Inference A coherent framework of dealing with uncertainties M: a model from some hypothesis space x: observed data Thomas Bayes ( ) Bayes rule offers a mathematically rigorous computational mechanism for combining prior knowledge with incoming evidence 3
4 Parametric Bayesian Inference is represented as a finite set of parameters A parametric likelihood: Prior on θ : Posterior distribution Examples: Gaussian distribution prior + 2D Gaussian likelihood Gaussian posterior distribution Dirichilet distribution prior + 2D Multinomial likelihood Dirichlet posterior distribution Sparsity-inducing priors + some likelihood models Sparse Bayesian inference 4
5 Nonparametric Bayesian Inference is a richer model, e.g., with an infinite set of parameters A nonparametric likelihood: Prior on : Posterior distribution Examples: see next slide 5
![Nonparametric Bayesian Inference probability measure binary matrix Dirichlet Process Prior [Antoniak, 1974] + Multinomial/Gaussian/Softmax likelihood Indian Buffet Process Prior](/docs-images/72/66546228/images/6-0.jpg "[Griffiths & Gharamani, 2005] + Gaussian/Sigmoid/Softmax likelihood function Gaussian Process Prior [Doob, 1944; Rasmussen & Williams, 2006] + Gaussian/Sigmoid/Softmax likelihood")
6 Nonparametric Bayesian Inference probability measure binary matrix Dirichlet Process Prior [Antoniak, 1974] + Multinomial/Gaussian/Softmax likelihood Indian Buffet Process Prior [Griffiths & Gharamani, 2005] + Gaussian/Sigmoid/Softmax likelihood function Gaussian Process Prior [Doob, 1944; Rasmussen & Williams, 2006] + Gaussian/Sigmoid/Softmax likelihood 6
7 Why Bayesian Nonparametrics? Let the data speak for themselves Bypass the model selection problem let data determine model complexity (e.g., the number of components in mixture models) allow model complexity to grow as more data observed 7
8 Can we further control the posterior distributions? posterior likelihood model prior It is desirable to further regularize the posterior distribution An extra freedom to perform Bayesian inference Arguably more direct to control the behavior of models Can be easier and more natural in some examples 8
9 Can we further control the posterior distributions? posterior likelihood model prior Directly control the posterior distributions? Not obvious how hard constraints (A single feasible space) soft constraints (many feasible subspaces with different complexities/penalties) 9
10 A reformulation of Bayesian inference posterior likelihood model prior Bayes rule is equivalent to: A direct but trivial constraint on the posterior distribution E.T. Jaynes (1988): this fresh interpretation of Bayes theorem could make the use of Bayesian methods more attractive and widespread, and stimulate new developments in the general theory of inference [Zellner, Am. Stat. 1988] 10
11 Regularized Bayesian Inference where, e.x., and Solving such constrained optimization problem needs convex duality theory So, where does the constraints come from? 11





12 Recall our evolution of the Max- Margin Learning Paradigms SVM M 3 N b r a c e MED MED-MN? = SMED + Bayesian M 3 N 12
: Feasible subspace of weight distribution: Average from distribution of M 3")
13 Maximum Entropy Discrimination Markov Networks Structured MaxEnt Discrimination (SMED): Feasible subspace of weight distribution: Average from distribution of M 3 Ns p 13
14 Can we use this scheme to learn models other than MN? 14
15 Recall the 3 advantages of MEDN An averaging Model: PAC-Bayesian prediction error guarantee (Theorem 3) Entropy regularization: Introducing useful biases Standard Normal prior => reduction to standard M 3 N (we ve seen it) Laplace prior => Posterior shrinkage effects (sparse M 3 N) Integrating Generative and Discriminative principles (next class) Incorporate latent variables and structures (PoMEN) Semisupervised learning (with partially labeled data) 15


16 Latent Hierarchical MaxEnDNet Web data extraction Goal: Name, Image, Price, Description, etc. Hierarchical labeling Advantages: o Computational efficiency o Long-range dependency o Joint extraction {Head} {image} {Info Block} {Tail} {Note} {Repeat block} {Note} {name, price} {image} {name, price} {name} {price} {desc} {name} {price} 16
17 Partially Observed MaxEnDNet (PoMEN) (Zhu et al, NIPS 2008) Now we are given partially labeled data: PoMEN: learning Prediction: 17

 Step 2: keep fixed, optimize over Equivalently reduced to")
18 Alternating Minimization Alg. Factorization assumption: Alternating minimization: Step 1: keep fixed, optimize over o Normal prior M 3 N problem (QP) o Laplace prior Laplace M 3 N problem (VB) Step 2: keep fixed, optimize over Equivalently reduced to an LP with a polynomial number of constraints 18

 pages, or 1585 data records")


19 Experimental Results Web data extraction: Name, Image, Price, Description Methods: Hierarchical CRFs, Hierarchical M^3N PoMEN, Partially observed HCRFs Pages from 37 templates o o Training: 185 (5/per template) pages, or 1585 data records Testing: 370 (10/per template) pages, or 3391 data records Record-level Evaluation o Leaf nodes are labeled Page-level Evaluation o Supervision Level 1: Leaf nodes and data record nodes are labeled o Supervision Level 2: Level 1 + the nodes above data record nodes 19


20 Record-Level Evaluations Overall performance: Avg F1: o avg F1 over all attributes Block instance accuracy: o % of records whose Name, Image, and Price are correct Attribute performance: 20
21 Page-Level Evaluations Supervision Level 1: Leaf nodes and data record nodes are labeled Supervision Level 2: Level 1 + the nodes above data record nodes 4/29/

22 Key message from PoMEN Structured MaxEnt Discrimination (SMED): Feasible subspace of weight distribution: Average from distribution of PoMENs We can use this for any p and p 0! p 22
23 An all inclusive paradigm for learning general GM --- RegBayes Max-margin learning 23
24 Predictive Latent Subspace Learning via a large-margin approach where M is any subspace model and p is a parametric Bayesian prior 24




![models (aka LDA) [Blei et al 2003]](/docs-images/72/66546228/images/25-7.jpg "Total scene latent space models [Li et")
![al 2009] Athlete Horse Grass Trees Sky](/docs-images/72/66546228/images/25-8.jpg "Saddle Multi-view latent Markov models")
25 Unsupervised Latent Subspace Discovery Finding latent subspace representations (an old topic) Mapping a high-dimensional representation into a latent low-dimensional representation, where each dimension can have some interpretable meaning, e.g., a semantic topic Examples: Topic models (aka LDA) [Blei et al 2003] Total scene latent space models [Li et al 2009] Athlete Horse Grass Trees Sky Saddle Multi-view latent Markov models [Xing et al 2005] PCA, CCA, 25

 labels & rating scores are usually assigned based on")

26 Predictive Subspace Learning with Supervision Unsupervised latent subspace representations are generic but can be suboptimal for predictions Many datasets are available with supervised side information Tripadvisor Hotel Review ( LabelMe Can be noisy, but not random noise (Ames & Naaman, 2007) labels & rating scores are usually assigned based on some intrinsic property of the data helpful to suppress noise and capture the most useful aspects of the data Goals: Discover latent subspace representations that are both predictive and interpretable by exploring weak supervision information Many others Flickr ( 26
27 I. LDA: Latent Dirichlet Allocation (Blei et al., 2003) Generative Procedure: For each document d: Sample a topic proportion For each word: Sample a topic Sample a word Joint Distribution: Variational Inference with : exact inference intractable! Minimize the variational bound to estimate parameters and infer the posterior distribution 27

28 Maximum Entropy Discrimination LDA (MedLDA) (Zhu et al, ICML 2009) Bayesian slda: MED Estimation: MedLDA Regression Model model fitting MedLDA Classification Model predictive accuracy 28
 MedLDA")
29 Document Modeling Data Set: 20 Newsgroups 110 topics + 2D embedding with t-sne (var der Maaten & Hinton, 2008) MedLDA LDA 29
 Multiclass Classification: all the 20 categories Models: DiscLDA, slda (Binary ONLY! Classification slda (Wang et al.")
30 Classification Data Set: 20Newsgroups Binary classification: alt.atheism and talk.religion.misc (Simon et al., 2008) Multiclass Classification: all the 20 categories Models: DiscLDA, slda (Binary ONLY! Classification slda (Wang et al., 2009)), LDA+SVM (baseline), MedLDA, MedLDA+SVM Measure: Relative Improvement Ratio 30
31 Regression Data Set: Movie Review (Blei & McAuliffe, 2007) Models: MedLDA(partial), MedLDA(full), slda, LDA+SVR Measure: predictive R 2 and per-word log-likelihood 31
32 Time Efficiency Binary Classification Multiclass: MedLDA is comparable with LDA+SVM Regression: MedLDA is comparable with slda 32
33 II. Upstream Scene Understanding Models The Total Scene Understanding Model (Li et al, CVPR 2009) class: Polo Using MLE to estimate model parameters Athlete Horse Grass Trees Sky Saddle 33
34 Scene Classification 8-category sports data set (Li & Fei-Fei, 2007): Fei-Fei s theme model: 0.65 (different image representation) SVM: images (50/50 split) Pre-segment each image into regions Region features: color, texture, and location patches with SIFT features Global features: Gist (Oliva & Torralba, 2001) Sparse SIFT codes (Yang et al, 2009) 34
 used human annotated interest")
35 MIT Indoor Scene Classification results: 67-category MIT indoor scene (Quattoni & Torralba, 2009): ~80 per-category for training; ~20 per-category for testing Same feature representation as above Gist global features $ ROI+Gist(annotation) used human annotated interest regions. 35
 contrastive divergence is the commonly used approximation method in learning undirected latent variable models (Welling et al.")
36 III. Supervised Multi-view RBMs A probabilistic method with an additional view of response variables Y Y 1 Y L normalization factor Parameters can be learned with maximum likelihood estimation, e.g., special supervised Harmonium (Yang et al., 2007) contrastive divergence is the commonly used approximation method in learning undirected latent variable models (Welling et al., 2004; Salakhutdinov & Murray, 2008). 36

37 Predictive Latent Representation t-sne (van der Maaten & Hinton, 2008) 2D embedding of the discovered latent space representation on the TRECVID 2003 data MMH Avg-KL: average pair-wise divergence TWH 37

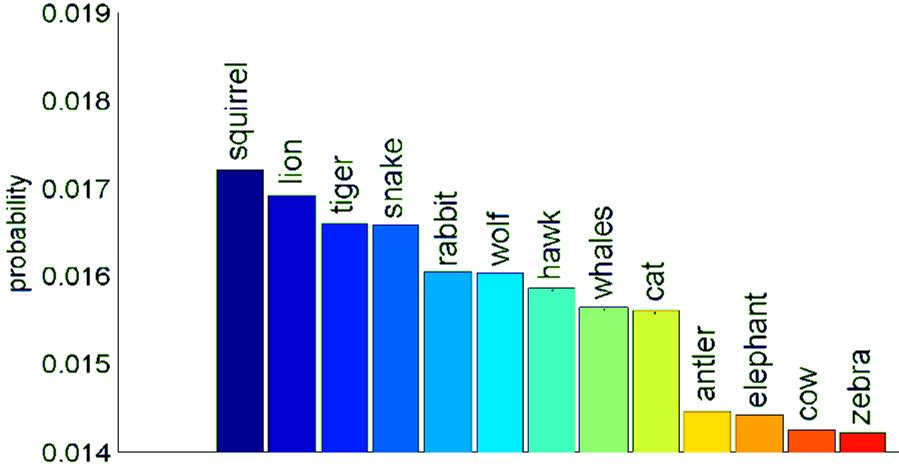




38 Predictive Latent Representation Example latent topics discovered by a 60-topic MMH on Flickr Animal Data 38
39 Classification Results Data Sets: (Left) TRECVID 2003: (text + image features) (Right) Flickr 13 Animal: (sift + image features) Models: baseline(svm),dwh+svm, GM-Mixture+SVM, GM-LDA+SVM, TWH, MedLDA(sift only), MMH TRECVID Flickr 39

 average precision on different topics and (Right) precisionrecall curve")
40 Retrieval Results Data Set: TRECVID 2003 Each test sample is treated as a query, training samples are ranked based on the cosine similarity between a training sample and the given query Similarity is computed based on the discovered latent topic representations Models: DWH, GM-Mixture, GM-LDA, TWH, MMH Measure: (Left) average precision on different topics and (Right) precisionrecall curve 40
41 Infinite SVM and infinite latent SVM: -- where SVMs meet NB for classification and feature selection where M is any combinations of classifiers and p is a nonparametric Bayesian prior 41
42 Mixture of SVMs Dirichlet process mixture of large-margin kernel machines Learn flexible non-linear local classifiers; potentially lead to a better control on model complexity, e.g., few unnecessary components SVM using RBF kernel Mixture of 2 linear SVM Mixture of 2 RBF-SVM The first attempt to integrate Bayesian nonparametrics, large-margin learning, and kernel methods 42
43 Infinite SVM RegBayes framework: convex function direct and rich constraints on posterior distribution Model latent class model Prior Dirichlet process Likelihood Gaussian likelihood Posterior constraints max-margin constraints 43

44 Infinite SVM DP mixture of large-margin classifiers process of determining which classifier to use: Given a component classifier: Graphical model with stick-breaking construction of DP Overall discriminant function: Prediction rule: Learning problem: 44
45 Infinite SVM Assumption and relaxation Truncated variational distribution Upper bound the KL-regularizer Graphical model with stick-breaking construction of DP Opt. with coordinate descent For, we solve an SVM learning problem For, we get the closed update rule The last term regularizes the mixing proportions to favor prediction For, the same update rules as in (Blei & Jordan, 2006) 45
 Clusters: simiar backgroud images group a cluster has fewer")
46 Experiments on high-dim real data Classification results and test time: For training, linear-isvm is very efficient (~200s); RBF-iSVM is much slower, but can be significantly improved using efficient kernel methods (Rahimi & Recht, 2007; Fine & Scheinberg, 2001) Clusters: simiar backgroud images group a cluster has fewer categories 46
47 Learning Latent Features Infinite SVM is a Bayesian nonparametric latent class model discover clustering structures each data point is assigned to a single cluster/class Infinite Latent SVM is a Bayesian nonparametric latent feature/factor model discover latent factors each data point is mapped to a set (can be infinite) of latent factors Latent factor analysis is a key technique in many fields; Popular models are FA, PCA, ICA, NMF, LSI, etc. 47
48 Infinite Latent SVM RegBayes framework: convex function direct and rich constraints on posterior distribution Model latent feature model Prior Indian Buffet process Likelihood Gaussian likelihood Posterior constraints max-margin constraints 48
49 Beta-Bernoulli Latent Feature Model A random finite binary latent feature models is the relative probability of each feature being on, e.g., are binary vectors, giving the latent structure that s used to generate the data, e.g., 49

50 Indian Buffet Process A stochastic process on infinite binary feature matrices Generative procedure: Customer 1 chooses the first dishes: Customer i chooses: Each of the existing dishes with probability additional dishes, where 50
51 Posterior Constraints classification Suppose latent features z are given, we define latent discriminant function: Define effective discriminant function (reduce uncertainty): Posterior constraints with max-margin principle 51


52 Experimental Results Classification Accuracy and F1 scores on TRECVID2003 and Flickr image datasets 52
53 Summary Bayesian kernel machines; Infinite GPs Large-margin learning Large-margin kernel machines 53
 Large-margin")
54 Summary Linear Expectation Operator (resolve uncertainty) Large-margin learning 54
55 Summary A general framework of MaxEnDNet for learning structured input/output models Subsumes the standard M 3 Ns Model averaging: PAC-Bayes theoretical error bound Entropic regularization: sparse M 3 Ns Generative + discriminative: latent variables, semi-supervised learning on partially labeled data, fast inference PoMEN Provides an elegant approach to incorporate latent variables and structures under maxmargin framework Enable Learning arbitrary graphical models discriminatively Predictive Latent Subspace Learning MedLDA for text topic learning Med total scene model for image understanding Med latent MNs for multi-view inference Bayesian nonparametrics meets max-margin learning Experimental results show the advantages of max-margin learning over likelihood methods in EVERY case. 55
56 Remember: Elements of Learning Here are some important elements to consider before you start: Task: Embedding? Classification? Clustering? Topic extraction? Data and other info: Input and output (e.g., continuous, binary, counts, ) Supervised or unsupervised, of a blend of everything? Prior knowledge? Bias? Models and paradigms: BN? MRF? Regression? SVM? Bayesian/Frequents? Parametric/Nonparametric? Objective/Loss function: MLE? MCLE? Max margin? Log loss, hinge loss, square loss? Tractability and exactness trade off: Exact inference? MCMC? Variational? Gradient? Greedy search? Online? Batch? Distributed? Evaluation: Visualization? Human interpretability? Perperlexity? Predictive accuracy? It is better to consider one element at a time! 56
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Semi-Supervised Face Detection
 Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Semi-Supervised Face Detection Nicu Sebe, Ira Cohen 2, Thomas S. Huang 3, Theo Gevers Faculty of Science, University of Amsterdam, The Netherlands 2 HP Research Labs, USA 3 Beckman Institute, University
Calibration of Confidence Measures in Speech Recognition
 Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Submitted to IEEE Trans on Audio, Speech, and Language, July 2010 1 Calibration of Confidence Measures in Speech Recognition Dong Yu, Senior Member, IEEE, Jinyu Li, Member, IEEE, Li Deng, Fellow, IEEE
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model
 Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
Unsupervised Learning of Word Semantic Embedding using the Deep Structured Semantic Model Xinying Song, Xiaodong He, Jianfeng Gao, Li Deng Microsoft Research, One Microsoft Way, Redmond, WA 98052, U.S.A.
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation
 A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
A New Perspective on Combining GMM and DNN Frameworks for Speaker Adaptation SLSP-2016 October 11-12 Natalia Tomashenko 1,2,3 natalia.tomashenko@univ-lemans.fr Yuri Khokhlov 3 khokhlov@speechpro.com Yannick
arxiv: v2 [cs.cv] 30 Mar 2017
![arxiv: v2 [cs.cv] 30 Mar 2017](/thumbs/71/66193079.jpg "arxiv: v2 [cs.cv] 30 Mar 2017") Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Domain Adaptation for Visual Applications: A Comprehensive Survey Gabriela Csurka arxiv:1702.05374v2 [cs.cv] 30 Mar 2017 Abstract The aim of this paper 1 is to give an overview of domain adaptation and
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Comment-based Multi-View Clustering of Web 2.0 Items
 Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Comment-based Multi-View Clustering of Web 2.0 Items Xiangnan He 1 Min-Yen Kan 1 Peichu Xie 2 Xiao Chen 3 1 School of Computing, National University of Singapore 2 Department of Mathematics, National University
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Corrective Feedback and Persistent Learning for Information Extraction
 Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Corrective Feedback and Persistent Learning for Information Extraction Aron Culotta a, Trausti Kristjansson b, Andrew McCallum a, Paul Viola c a Dept. of Computer Science, University of Massachusetts,
Detailed course syllabus
 Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Detailed course syllabus 1. Linear regression model. Ordinary least squares method. This introductory class covers basic definitions of econometrics, econometric model, and economic data. Classification
Attributed Social Network Embedding
 JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2017 1 Attributed Social Network Embedding arxiv:1705.04969v1 [cs.si] 14 May 2017 Lizi Liao, Xiangnan He, Hanwang Zhang, and Tat-Seng Chua Abstract Embedding
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
arxiv: v1 [cs.lg] 15 Jun 2015
![arxiv: v1 [cs.lg] 15 Jun 2015](/thumbs/71/66112896.jpg "arxiv: v1 [cs.lg] 15 Jun 2015") Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
Dual Memory Architectures for Fast Deep Learning of Stream Data via an Online-Incremental-Transfer Strategy arxiv:1506.04477v1 [cs.lg] 15 Jun 2015 Sang-Woo Lee Min-Oh Heo School of Computer Science and
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Copyright by Sung Ju Hwang 2013
 Copyright by Sung Ju Hwang 2013 The Dissertation Committee for Sung Ju Hwang certifies that this is the approved version of the following dissertation: Discriminative Object Categorization with External
Copyright by Sung Ju Hwang 2013 The Dissertation Committee for Sung Ju Hwang certifies that this is the approved version of the following dissertation: Discriminative Object Categorization with External
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
The University of Amsterdam s Concept Detection System at ImageCLEF 2011
 The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Word learning as Bayesian inference
 Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
Word learning as Bayesian inference Joshua B. Tenenbaum Department of Psychology Stanford University jbt@psych.stanford.edu Fei Xu Department of Psychology Northeastern University fxu@neu.edu Abstract
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES
 PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
PREDICTING SPEECH RECOGNITION CONFIDENCE USING DEEP LEARNING WITH WORD IDENTITY AND SCORE FEATURES Po-Sen Huang, Kshitiz Kumar, Chaojun Liu, Yifan Gong, Li Deng Department of Electrical and Computer Engineering,
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
A survey of multi-view machine learning
 Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Noname manuscript No. (will be inserted by the editor) A survey of multi-view machine learning Shiliang Sun Received: date / Accepted: date Abstract Multi-view learning or learning with multiple distinct
Phonetic- and Speaker-Discriminant Features for Speaker Recognition. Research Project
 Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Phonetic- and Speaker-Discriminant Features for Speaker Recognition by Lara Stoll Research Project Submitted to the Department of Electrical Engineering and Computer Sciences, University of California
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
As a high-quality international conference in the field
 The New Automated IEEE INFOCOM Review Assignment System Baochun Li and Y. Thomas Hou Abstract In academic conferences, the structure of the review process has always been considered a critical aspect of
The New Automated IEEE INFOCOM Review Assignment System Baochun Li and Y. Thomas Hou Abstract In academic conferences, the structure of the review process has always been considered a critical aspect of
THE world surrounding us involves multiple modalities
 1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
1 Multimodal Machine Learning: A Survey and Taxonomy Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency arxiv:1705.09406v2 [cs.lg] 1 Aug 2017 Abstract Our experience of the world is multimodal
Modeling function word errors in DNN-HMM based LVCSR systems
 Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
Modeling function word errors in DNN-HMM based LVCSR systems Melvin Jose Johnson Premkumar, Ankur Bapna and Sree Avinash Parchuri Department of Computer Science Department of Electrical Engineering Stanford
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines
 Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Speech Segmentation Using Probabilistic Phonetic Feature Hierarchy and Support Vector Machines Amit Juneja and Carol Espy-Wilson Department of Electrical and Computer Engineering University of Maryland,
Learning to Rank with Selection Bias in Personal Search
 Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
Learning to Rank with Selection Bias in Personal Search Xuanhui Wang, Michael Bendersky, Donald Metzler, Marc Najork Google Inc. Mountain View, CA 94043 {xuanhui, bemike, metzler, najork}@google.com ABSTRACT
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION
 HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
HIERARCHICAL DEEP LEARNING ARCHITECTURE FOR 10K OBJECTS CLASSIFICATION Atul Laxman Katole 1, Krishna Prasad Yellapragada 1, Amish Kumar Bedi 1, Sehaj Singh Kalra 1 and Mynepalli Siva Chaitanya 1 1 Samsung
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance
 A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance a Assistant Professor a epartment of Computer Science Memoona Khanum a Tahira Mahboob b b Assistant Professor
A Survey on Unsupervised Machine Learning Algorithms for Automation, Classification and Maintenance a Assistant Professor a epartment of Computer Science Memoona Khanum a Tahira Mahboob b b Assistant Professor
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Comparison of network inference packages and methods for multiple networks inference
 Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
Comparison of network inference packages and methods for multiple networks inference Nathalie Villa-Vialaneix http://www.nathalievilla.org nathalie.villa@univ-paris1.fr 1ères Rencontres R - BoRdeaux, 3
arxiv: v2 [cs.ir] 22 Aug 2016
![arxiv: v2 [cs.ir] 22 Aug 2016](/thumbs/71/66014616.jpg "arxiv: v2 [cs.ir] 22 Aug 2016") Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
Exploring Deep Space: Learning Personalized Ranking in a Semantic Space arxiv:1608.00276v2 [cs.ir] 22 Aug 2016 ABSTRACT Jeroen B. P. Vuurens The Hague University of Applied Science Delft University of
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS. Elliot Singer and Douglas Reynolds
 DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
DOMAIN MISMATCH COMPENSATION FOR SPEAKER RECOGNITION USING A LIBRARY OF WHITENERS Elliot Singer and Douglas Reynolds Massachusetts Institute of Technology Lincoln Laboratory {es,dar}@ll.mit.edu ABSTRACT
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION
 ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
ADVANCES IN DEEP NEURAL NETWORK APPROACHES TO SPEAKER RECOGNITION Mitchell McLaren 1, Yun Lei 1, Luciana Ferrer 2 1 Speech Technology and Research Laboratory, SRI International, California, USA 2 Departamento
WHEN THERE IS A mismatch between the acoustic
 808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
808 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 14, NO. 3, MAY 2006 Optimization of Temporal Filters for Constructing Robust Features in Speech Recognition Jeih-Weih Hung, Member,
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA. 1. Introduction. Alta de Waal, Jacobus Venter and Etienne Barnard
 Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Chapter 10 APPLYING TOPIC MODELING TO FORENSIC DATA Alta de Waal, Jacobus Venter and Etienne Barnard Abstract Most actionable evidence is identified during the analysis phase of digital forensic investigations.
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Probability and Game Theory Course Syllabus
 Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Probability and Game Theory Course Syllabus DATE ACTIVITY CONCEPT Sunday Learn names; introduction to course, introduce the Battle of the Bismarck Sea as a 2-person zero-sum game. Monday Day 1 Pre-test
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Course Outline. Course Grading. Where to go for help. Academic Integrity. EE-589 Introduction to Neural Networks NN 1 EE
 EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
EE-589 Introduction to Neural Assistant Prof. Dr. Turgay IBRIKCI Room # 305 (322) 338 6868 / 139 Wensdays 9:00-12:00 Course Outline The course is divided in two parts: theory and practice. 1. Theory covers
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
JONATHAN H. WRIGHT Department of Economics, Johns Hopkins University, 3400 N. Charles St., Baltimore MD (410)
") JONATHAN H. WRIGHT Department of Economics, Johns Hopkins University, 3400 N. Charles St., Baltimore MD 21218. (410) 516 5728 wrightj@jhu.edu EDUCATION Harvard University 1993-1997. Ph.D., Economics (1997).
JONATHAN H. WRIGHT Department of Economics, Johns Hopkins University, 3400 N. Charles St., Baltimore MD 21218. (410) 516 5728 wrightj@jhu.edu EDUCATION Harvard University 1993-1997. Ph.D., Economics (1997).
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH
 IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
IEEE TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 17, NO. 3, MARCH 2009 423 Adaptive Multimodal Fusion by Uncertainty Compensation With Application to Audiovisual Speech Recognition George
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Deep Facial Action Unit Recognition from Partially Labeled Data
 Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
Deep Facial Action Unit Recognition from Partially Labeled Data Shan Wu 1, Shangfei Wang,1, Bowen Pan 1, and Qiang Ji 2 1 University of Science and Technology of China, Hefei, Anhui, China 2 Rensselaer
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK. Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren
 A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
A NOVEL SCHEME FOR SPEAKER RECOGNITION USING A PHONETICALLY-AWARE DEEP NEURAL NETWORK Yun Lei Nicolas Scheffer Luciana Ferrer Mitchell McLaren Speech Technology and Research Laboratory, SRI International,
Abnormal Activity Recognition Based on HDP-HMM Models
 Abnormal Activity Recognition Based on HDP-HMM Models Derek Hao Hu a, Xian-Xing Zhang b,jieyin c, Vincent Wenchen Zheng a and Qiang Yang a a Department of Computer Science and Engineering, Hong Kong University
Abnormal Activity Recognition Based on HDP-HMM Models Derek Hao Hu a, Xian-Xing Zhang b,jieyin c, Vincent Wenchen Zheng a and Qiang Yang a a Department of Computer Science and Engineering, Hong Kong University
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Probability estimates in a scenario tree
 101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
101 Chapter 11 Probability estimates in a scenario tree An expert is a person who has made all the mistakes that can be made in a very narrow field. Niels Bohr (1885 1962) Scenario trees require many numbers.
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Analysis of Emotion Recognition System through Speech Signal Using KNN & GMM Classifier
 IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
IOSR Journal of Electronics and Communication Engineering (IOSR-JECE) e-issn: 2278-2834,p- ISSN: 2278-8735.Volume 10, Issue 2, Ver.1 (Mar - Apr.2015), PP 55-61 www.iosrjournals.org Analysis of Emotion
Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation
 Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Multimodal Technologies and Interaction Article Evaluating Interactive Visualization of Multidimensional Data Projection with Feature Transformation Kai Xu 1, *,, Leishi Zhang 1,, Daniel Pérez 2,, Phong
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition
 Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition Tom Y. Ouyang * MIT CSAIL ouyang@csail.mit.edu Yang Li Google Research yangli@acm.org ABSTRACT Personal
Bootstrapping Personal Gesture Shortcuts with the Wisdom of the Crowd and Handwriting Recognition Tom Y. Ouyang * MIT CSAIL ouyang@csail.mit.edu Yang Li Google Research yangli@acm.org ABSTRACT Personal
12- A whirlwind tour of statistics
 CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
CyLab HT 05-436 / 05-836 / 08-534 / 08-734 / 19-534 / 19-734 Usable Privacy and Security TP :// C DU February 22, 2016 y & Secu rivac rity P le ratory bo La Lujo Bauer, Nicolas Christin, and Abby Marsh
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY
 TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
TRANSFER LEARNING IN MIR: SHARING LEARNED LATENT REPRESENTATIONS FOR MUSIC AUDIO CLASSIFICATION AND SIMILARITY Philippe Hamel, Matthew E. P. Davies, Kazuyoshi Yoshii and Masataka Goto National Institute
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur)
 (Some slides, pony-based examples from Blase Ur)") Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Quantitative analysis with statistics (and ponies) (Some slides, pony-based examples from Blase Ur) 1 Interviews, diary studies Start stats Thursday: Ethics/IRB Tuesday: More stats New homework is available
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
A Case-Based Approach To Imitation Learning in Robotic Agents
 A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu
A Case-Based Approach To Imitation Learning in Robotic Agents Tesca Fitzgerald, Ashok Goel School of Interactive Computing Georgia Institute of Technology, Atlanta, GA 30332, USA {tesca.fitzgerald,goel}@cc.gatech.edu