Statistical methods in NLP Classication
|
|
|
- Clyde Jones
- 6 years ago
- Views:
Transcription
1 Statistical methods in NLP Classication UNIVERSITY OF Richard Johansson February 4, 2016
2 overview of today's lecture classication: general ideas Naive Bayes recap formulation, estimation Naive Bayes as a generative model other classiers (that are not generative) practical matters
3 overview introduction Naive Bayes denition and generative models estimation in the Naive Bayes model discriminative models the next few weeks
4 classiers... given an object, assign a category such tasks are pervasive in NLP
... by target group (e.g. CEFR readability) or some property of the author (e.g. gender, native language)")
5 example: classication of documents assignment 1: develop a program that groups customer reviews into positive and negative classes (given the text only) other examples: Reuters, 100 hierarchical categories classication according to a library system (LCC, SAB)... by target group (e.g. CEFR readability) or some property of the author (e.g. gender, native language)

6 example: disambiguation of word meaning in context A woman and child suered minor injuries after the car they were riding in crashed into a rock wall Tuesday morning. what is the meaning of rock in this context?
7 example: classication of grammatical relations what is the grammatical relation between åker and till? e.g. subject, object, adverbial,...
8 example: classication of discourse relations Mary had to study hard. Her exam was only one week away. what is the discourse/rhetorical relation between the two sentences? e.g. IF, THEN, AND, BECAUSE, BUT,...
9 features for classication to be able to classify an object, we must describe its properties: features useful information that we believe helps us tell the classes apart this is an art more than a science examples: in document classication, typically the words... but also stylistic features such as sentence length, word variation, syntactic complexity
10 representation of features depending on the task we are trying to solve, features may be viewed in dierent ways bag of words: ["I", "love", "this", "film"] attributevalue pairs: {"age"=63, "gender"="f", "income"=25000} geometric vector: [0, 0, 0, 0, 1, 0, 0, 2, 0, 0, 1] in this lecture and in the assignments, we will use the bag of words representation
11 a note on terminology we want to develop some NLP system (a classier, a tagger, a parser,... ) by getting some parameters from the data instead of hard-coding (data-driven) a statistician would say that we estimate parameters of a model a computer scientist would say that we train the model or conversely, that we apply a machine learning algorithm in the machine learning course this fall, we will see several such algorithms including algorithms that are not motivated by probabilities and statistical theory
12 training sets we are given a set of examples (e.g. reviews) each example comes with a gold-standard positive or negative class label we then use these examples to estimate the parameters of our statistical model the model can then be used to classify reviews we haven't seen before
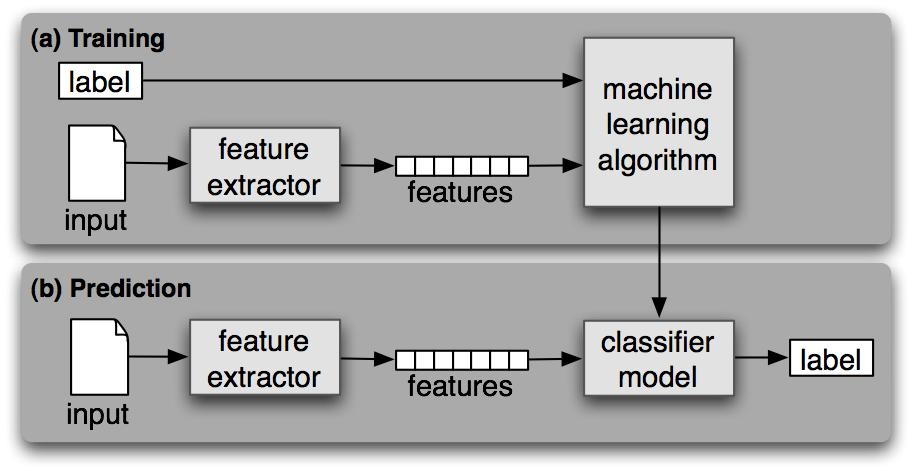
13 overview
14 scientic hygiene in experiments in addition to the training set, we have a test set that we use when estimating the accuracy (or P, R, etc) like the training set, the test set also contains gold-standard labels the training and test sets should be distinct! also, don't use the test set for optimization! use a separate development set instead
15 overview introduction Naive Bayes denition and generative models estimation in the Naive Bayes model discriminative models the next few weeks
16 Naive Bayes Naive Bayes is a classication method based on a simple probability model recall from the NLP course: P(f 1,..., f n, class) = P(class) P(f 1,..., f n class) = P(class) P(f 1 class)... P(f n class) for instance: f 1,..., f n are the words occurring in the document, and class is positive or negative if we have these probabilities, then we can guess the class of an unseen example (just nd the class that maximizes P) guess = arg max class P(f 1,..., f n, class)
17 Naive Bayes as a generative model Naive Bayes is an example of a generative graphical model a generative graphical model is dened in terms of a generative story that describes how the data was created a generative model computes the joint probability P(input, output) we can draw them using plate diagrams
18 generative story in Naive Bayes
19 generative story in Naive Bayes
20 generative story in Naive Bayes
21 generative story in Naive Bayes
22 generative story in Naive Bayes
23 generative story in Naive Bayes the model gives us P(this hotel is really nice, Positive)
24 a plate diagram for Naive Bayes this story can be represented using a plate diagram:
25 explanation of the plate diagram (1) grey balls represent observed variables and white balls unobserved supervised NB: we see the words and the document classes unsupervised NB: we don't see the document classes
26 explanation of the plate diagram (2) the arrows represent how we model probabilities the probability of a word x ij is dened in terms of the document class y i the rectangles (the plates) represent repetion (a for loop): the collection consists of documents i = 1,..., m each document consists of words j = 1,..., n i
27 generative story in hidden Markov models
28 generative story in hidden Markov models
29 generative story in hidden Markov models
30 generative story in hidden Markov models
31 generative story in hidden Markov models
32 generative story in PCFGs
33 generative story in topic models (simplied)
34 generative story in topic models (simplied)
35 generative story in topic models (simplied)
36 generative story in topic models (simplied)
37 generative story in topic models (simplied)
38 generative story in topic models (simplied)
39 overview introduction Naive Bayes denition and generative models estimation in the Naive Bayes model discriminative models the next few weeks
40 what kind of information is available? supervised learning: the desired output classes are given
41 what kind of information is available? supervised learning: the desired output classes are given unsupervised learning: the classes are not given
42 what kind of information is available? supervised learning: the desired output classes are given unsupervised learning: the classes are not given semisupervised learning: some of the classes are given
43 estimation in supervised Naive Bayes we are given a set of documents labeled with classes to be able to guess the class of new unseen documents, we estimate the parameters of the model: the probability of each class the probabilities of the features (words) given the class in the supervised case, this is unproblematic
44 estimation of the class probabilities we observe two positive (blue) documents out of four how do we estimate P(positive)?
45 estimation of the class probabilities we observe two positive (blue) documents out of four how do we estimate P(positive)? maximum likelihood estimate P MLE (positive) = count(positive) count(all) = 2 4 (four observations of a coin-toss variable)
46 estimation of the feature probabilities how do we estimate P(nice positive)?
47 estimation of the feature probabilities how do we estimate P(nice positive)? maximum likelihood estimate count(nice, positive) P MLE (nice positive) = count(any word, positive) = 2 7
48 dealing with zeros zero counts are as usual a problem for MLE estimates! smoothing is needed
 = count(word, class)+1 count(any word, class)+ voc size P Laplace (nice positive) = 2+1")
49 Laplace smoothing: add one to each count Laplace smoothing: add one to all counts P Laplace (word class) = count(word, class)+1 count(any word, class)+ voc size P Laplace (nice positive) =
50 overview introduction Naive Bayes denition and generative models estimation in the Naive Bayes model discriminative models the next few weeks
51 generative vs. discriminative models recall that a generative model computes the joint probability P(input, output) and is dened in terms of a generative story other types of classiers are called discriminative: they can compute some other probability instead for instance P(output input) or classify in some other way without probabilities!
52 some types of discriminative classiers logistic regression: maximum likelihood of P(output input) (read on your own) many other types of classiers, e.g. decision trees (Simon's lecture) we will now study a very simple approach based on dictionary lookup in a weight table we'll consider the use case of classifying reviews, like in your assignment

53 rst idea: use a polarity wordlist... for instance the MPQA list
54 document sentiment polarity by summing word scores store all MPQA polarity values in a table as numerical values e.g. 2 points for strong positive, -1 point for weak negative predict the overall polarity value of the document by summing the scores of each word occurring def guess_sentiment_polarity(document, weights): score = 0 for word in document: score += weights[word] if score >= 0: return "pos" else: return "neg"
55 experiment we evaluate on 50% of a sentiment dataset def evaluate(labeled_documents, weights): ncorrect = 0 for class_label, document in labeled_documents: guess = guess_sentiment_polarity(document, weights) if guess == class_label: ncorrect += 1 return ncorrect / len(labeled_documents) this is a balanced dataset, coin-toss accuracy would be 50% with MPQA, we get an accuracy of 59.5%
56 can we do better? it's hard to set the word weights what if we don't even have a resource such as MPQA? can we set the weights automatically?
57 an idea for setting the weights automatically start with an empty weight table (instead of using MPQA) classify documents according to the current weight table each time we misclassify, change the weight table a bit if a positive document was misclassied, add 1 to the weight of each word in the document and conversely...
58 an idea for setting the weights automatically start with an empty weight table (instead of using MPQA) classify documents according to the current weight table each time we misclassify, change the weight table a bit if a positive document was misclassied, add 1 to the weight of each word in the document and conversely... def train_by_errors(labeled_documents): weights = Counter() for class_label, document in labeled_documents: guess = guess_sentiment_polarity(document, weights) if class_label == "pos" and guess == "neg": for word in document: weights[word] += 1 elif class_label == "neg" and guess == "pos": for word in document: weights[word] -= 1 return weights
59 new experiment we compute the weights using 50% of the sentiment data and test on the other half the accuracy is 81.4%, up from the 59.5% we had when we used the MPQA train_by_errors is called the perceptron algorithm and is one of the most widely used machine learning algorithms
60 examples of the weights amazing 171 easy 124 perfect 109 highly 108 five 107 excellent 104 enjoy 93 job 92 question 90 wonderful 90 performance 83 those 80 r&b 80 loves 79 best 78 recommended 77 favorite 77 included 76 medical 75 america 74 waste -175 worst -168 boring -154 poor -134 ` -130 unfortunately -122 horrible -118 ok -111 disappointment -109 unless -108 called -103 example -100 bad -100 save -99 bunch -98 talk -96 useless -95 author -94 effort -94 oh -94
61 the same thing with scikit-learn to train a classier: vec = DictVectorizer() clf = Perceptron(n_iter=20) clf.fit(vec.fit_transform(train_docs), numpy.array(train_targets)) to classify a new instance: guess = clf.predict(vec.transform(doc)) more about classication and scikit-learn in the course on machine learning
62 an aside: domain sensitivity a common problem with classiers (and NLP systems in general) is domain sensitivity: they work best on the type of texts used when developing a review classier for book reviews won't work as well for health product reviews book health book health it may depend on the domain which words are informative, and also what sentiment they have for instance, small may be a good thing about a camera but not about a hotel room
63 overview introduction Naive Bayes denition and generative models estimation in the Naive Bayes model discriminative models the next few weeks
64 the computer assignments assignment 1: implement a Naive Bayes classier and use it to group customer reviews into positive and negative optionally: implement the perceptron as well, or use scikit-learn February 9 and 11 report deadline: February 25 assignment 2: a statistical analysis of the performance of your classier(s)
65 next lectures February 16 (in the lab): comparing classiers February 23 (here): tagging with HMM models
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Contents. Foreword... 5
 Contents Foreword... 5 Chapter 1: Addition Within 0-10 Introduction... 6 Two Groups and a Total... 10 Learn Symbols + and =... 13 Addition Practice... 15 Which is More?... 17 Missing Items... 19 Sums with
Contents Foreword... 5 Chapter 1: Addition Within 0-10 Introduction... 6 Two Groups and a Total... 10 Learn Symbols + and =... 13 Addition Practice... 15 Which is More?... 17 Missing Items... 19 Sums with
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Mathematics Success Grade 7
 T894 Mathematics Success Grade 7 [OBJECTIVE] The student will find probabilities of compound events using organized lists, tables, tree diagrams, and simulations. [PREREQUISITE SKILLS] Simple probability,
T894 Mathematics Success Grade 7 [OBJECTIVE] The student will find probabilities of compound events using organized lists, tables, tree diagrams, and simulations. [PREREQUISITE SKILLS] Simple probability,
CS 598 Natural Language Processing
 CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
CS 598 Natural Language Processing Natural language is everywhere Natural language is everywhere Natural language is everywhere Natural language is everywhere!"#$%&'&()*+,-./012 34*5665756638/9:;< =>?@ABCDEFGHIJ5KL@
What is a Mental Model?
 Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
Mental Models for Program Understanding Dr. Jonathan I. Maletic Computer Science Department Kent State University What is a Mental Model? Internal (mental) representation of a real system s behavior,
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly
 ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
ESSLLI 2010: Resource-light Morpho-syntactic Analysis of Highly Inflected Languages Classical Approaches to Tagging The slides are posted on the web. The url is http://chss.montclair.edu/~feldmana/esslli10/.
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
CSL465/603 - Machine Learning
 CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
CSL465/603 - Machine Learning Fall 2016 Narayanan C Krishnan ckn@iitrpr.ac.in Introduction CSL465/603 - Machine Learning 1 Administrative Trivia Course Structure 3-0-2 Lecture Timings Monday 9.55-10.45am
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Improving Simple Bayes. Abstract. The simple Bayesian classier (SBC), sometimes called
, sometimes called") Improving Simple Bayes Ron Kohavi Barry Becker Dan Sommereld Data Mining and Visualization Group Silicon Graphics, Inc. 2011 N. Shoreline Blvd. Mountain View, CA 94043 fbecker,ronnyk,sommdag@engr.sgi.com
Improving Simple Bayes Ron Kohavi Barry Becker Dan Sommereld Data Mining and Visualization Group Silicon Graphics, Inc. 2011 N. Shoreline Blvd. Mountain View, CA 94043 fbecker,ronnyk,sommdag@engr.sgi.com
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Multilingual Sentiment and Subjectivity Analysis
 Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Multilingual Sentiment and Subjectivity Analysis Carmen Banea and Rada Mihalcea Department of Computer Science University of North Texas rada@cs.unt.edu, carmen.banea@gmail.com Janyce Wiebe Department
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities
 Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
Enhancing Unlexicalized Parsing Performance using a Wide Coverage Lexicon, Fuzzy Tag-set Mapping, and EM-HMM-based Lexical Probabilities Yoav Goldberg Reut Tsarfaty Meni Adler Michael Elhadad Ben Gurion
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Prediction of Maximal Projection for Semantic Role Labeling
 Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Prediction of Maximal Projection for Semantic Role Labeling Weiwei Sun, Zhifang Sui Institute of Computational Linguistics Peking University Beijing, 100871, China {ws, szf}@pku.edu.cn Haifeng Wang Toshiba
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Accuracy (%) # features
 # features") Question Terminology and Representation for Question Type Classication Noriko Tomuro DePaul University School of Computer Science, Telecommunications and Information Systems 243 S. Wabash Ave. Chicago,
Question Terminology and Representation for Question Type Classication Noriko Tomuro DePaul University School of Computer Science, Telecommunications and Information Systems 243 S. Wabash Ave. Chicago,
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
CHAPTER 4: REIMBURSEMENT STRATEGIES 24
 CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
11/29/2010. Statistical Parsing. Statistical Parsing. Simple PCFG for ATIS English. Syntactic Disambiguation
 tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
tatistical Parsing (Following slides are modified from Prof. Raymond Mooney s slides.) tatistical Parsing tatistical parsing uses a probabilistic model of syntax in order to assign probabilities to each
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Online Updating of Word Representations for Part-of-Speech Tagging
 Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
Online Updating of Word Representations for Part-of-Speech Tagging Wenpeng Yin LMU Munich wenpeng@cis.lmu.de Tobias Schnabel Cornell University tbs49@cornell.edu Hinrich Schütze LMU Munich inquiries@cislmu.org
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Let's Learn English Lesson Plan
 Let's Learn English Lesson Plan Introduction: Let's Learn English lesson plans are based on the CALLA approach. See the end of each lesson for more information and resources on teaching with the CALLA
Let's Learn English Lesson Plan Introduction: Let's Learn English lesson plans are based on the CALLA approach. See the end of each lesson for more information and resources on teaching with the CALLA
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics
 Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Machine Learning from Garden Path Sentences: The Application of Computational Linguistics http://dx.doi.org/10.3991/ijet.v9i6.4109 J.L. Du 1, P.F. Yu 1 and M.L. Li 2 1 Guangdong University of Foreign Studies,
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF
 Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
Read Online and Download Ebook ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY DOWNLOAD EBOOK : ADVANCED MACHINE LEARNING WITH PYTHON BY JOHN HEARTY PDF Click link bellow and free register to download
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS
 CORRELATED TO CALIFORNIA CONTENT STANDARDS") AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
AGS THE GREAT REVIEW GAME FOR PRE-ALGEBRA (CD) CORRELATED TO CALIFORNIA CONTENT STANDARDS 1 CALIFORNIA CONTENT STANDARDS: Chapter 1 ALGEBRA AND WHOLE NUMBERS Algebra and Functions 1.4 Students use algebraic
Ensemble Technique Utilization for Indonesian Dependency Parser
 Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
Ensemble Technique Utilization for Indonesian Dependency Parser Arief Rahman Institut Teknologi Bandung Indonesia 23516008@std.stei.itb.ac.id Ayu Purwarianti Institut Teknologi Bandung Indonesia ayu@stei.itb.ac.id
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
Transductive Inference for Text Classication using Support Vector. Machines. Thorsten Joachims. Universitat Dortmund, LS VIII
 Transductive Inference for Text Classication using Support Vector Machines Thorsten Joachims Universitat Dortmund, LS VIII 4422 Dortmund, Germany joachims@ls8.cs.uni-dortmund.de Abstract This paper introduces
Transductive Inference for Text Classication using Support Vector Machines Thorsten Joachims Universitat Dortmund, LS VIII 4422 Dortmund, Germany joachims@ls8.cs.uni-dortmund.de Abstract This paper introduces
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
Chapter 2 Rule Learning in a Nutshell
 Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Chapter 2 Rule Learning in a Nutshell This chapter gives a brief overview of inductive rule learning and may therefore serve as a guide through the rest of the book. Later chapters will expand upon the
Objectives. Chapter 2: The Representation of Knowledge. Expert Systems: Principles and Programming, Fourth Edition
 Chapter 2: The Representation of Knowledge Expert Systems: Principles and Programming, Fourth Edition Objectives Introduce the study of logic Learn the difference between formal logic and informal logic
Chapter 2: The Representation of Knowledge Expert Systems: Principles and Programming, Fourth Edition Objectives Introduce the study of logic Learn the difference between formal logic and informal logic
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Basic Parsing with Context-Free Grammars. Some slides adapted from Julia Hirschberg and Dan Jurafsky 1
 Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Basic Parsing with Context-Free Grammars Some slides adapted from Julia Hirschberg and Dan Jurafsky 1 Announcements HW 2 to go out today. Next Tuesday most important for background to assignment Sign up
Purdue Data Summit Communication of Big Data Analytics. New SAT Predictive Validity Case Study
 Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Purdue Data Summit 2017 Communication of Big Data Analytics New SAT Predictive Validity Case Study Paul M. Johnson, Ed.D. Associate Vice President for Enrollment Management, Research & Enrollment Information
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
CS177 Python Programming
 CS177 Python Programming Recitation 1 Introduction Adapted from John Zelle s Book Slides 1 Course Instructors Dr. Elisha Sacks E-mail: eps@purdue.edu Ruby Tahboub (Course Coordinator) E-mail: rtahboub@purdue.edu
CS177 Python Programming Recitation 1 Introduction Adapted from John Zelle s Book Slides 1 Course Instructors Dr. Elisha Sacks E-mail: eps@purdue.edu Ruby Tahboub (Course Coordinator) E-mail: rtahboub@purdue.edu
CS 1103 Computer Science I Honors. Fall Instructor Muller. Syllabus
 CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
CS 1103 Computer Science I Honors Fall 2016 Instructor Muller Syllabus Welcome to CS1103. This course is an introduction to the art and science of computer programming and to some of the fundamental concepts
SOCIAL STUDIES GRADE 1. Clear Learning Targets Office of Teaching and Learning Curriculum Division FAMILIES NOW AND LONG AGO, NEAR AND FAR
 SOCIAL STUDIES FAMILIES NOW AND LONG AGO, NEAR AND FAR GRADE 1 Clear Learning Targets 2015-2016 Aligned with Ohio s Learning Standards for Social Studies Office of Teaching and Learning Curriculum Division
SOCIAL STUDIES FAMILIES NOW AND LONG AGO, NEAR AND FAR GRADE 1 Clear Learning Targets 2015-2016 Aligned with Ohio s Learning Standards for Social Studies Office of Teaching and Learning Curriculum Division
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode
 Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
Unsupervised Acoustic Model Training for Simultaneous Lecture Translation in Incremental and Batch Mode Diploma Thesis of Michael Heck At the Department of Informatics Karlsruhe Institute of Technology
IN THIS UNIT YOU LEARN HOW TO: SPEAKING 1 Work in pairs. Discuss the questions. 2 Work with a new partner. Discuss the questions.
 6 1 IN THIS UNIT YOU LEARN HOW TO: ask and answer common questions about jobs talk about what you re doing at work at the moment talk about arrangements and appointments recognise and use collocations
6 1 IN THIS UNIT YOU LEARN HOW TO: ask and answer common questions about jobs talk about what you re doing at work at the moment talk about arrangements and appointments recognise and use collocations
Iraqi EFL Students' Achievement In The Present Tense And Present Passive Constructions
 Iraqi EFL Students' Achievement In The Present Tense And Present Passive Constructions Shurooq Abudi Ali University Of Baghdad College Of Arts English Department Abstract The present tense and present
Iraqi EFL Students' Achievement In The Present Tense And Present Passive Constructions Shurooq Abudi Ali University Of Baghdad College Of Arts English Department Abstract The present tense and present
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Part I. Figuring out how English works
 9 Part I Figuring out how English works 10 Chapter One Interaction and grammar Grammar focus. Tag questions Introduction. How closely do you pay attention to how English is used around you? For example,
9 Part I Figuring out how English works 10 Chapter One Interaction and grammar Grammar focus. Tag questions Introduction. How closely do you pay attention to how English is used around you? For example,
Chunk Parsing for Base Noun Phrases using Regular Expressions. Let s first let the variable s0 be the sentence tree of the first sentence.
 NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
NLP Lab Session Week 8 October 15, 2014 Noun Phrase Chunking and WordNet in NLTK Getting Started In this lab session, we will work together through a series of small examples using the IDLE window and
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches
 NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
Content Language Objectives (CLOs) August 2012, H. Butts & G. De Anda
 August 2012, H. Butts & G. De Anda") Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System
 QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
QuickStroke: An Incremental On-line Chinese Handwriting Recognition System Nada P. Matić John C. Platt Λ Tony Wang y Synaptics, Inc. 2381 Bering Drive San Jose, CA 95131, USA Abstract This paper presents
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
University of Alberta. Large-Scale Semi-Supervised Learning for Natural Language Processing. Shane Bergsma
 University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
University of Alberta Large-Scale Semi-Supervised Learning for Natural Language Processing by Shane Bergsma A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of
College Pricing. Ben Johnson. April 30, Abstract. Colleges in the United States price discriminate based on student characteristics
 College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
College Pricing Ben Johnson April 30, 2012 Abstract Colleges in the United States price discriminate based on student characteristics such as ability and income. This paper develops a model of college
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
BMBF Project ROBUKOM: Robust Communication Networks
 BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
BMBF Project ROBUKOM: Robust Communication Networks Arie M.C.A. Koster Christoph Helmberg Andreas Bley Martin Grötschel Thomas Bauschert supported by BMBF grant 03MS616A: ROBUKOM Robust Communication Networks,
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Softprop: Softmax Neural Network Backpropagation Learning
 Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Softprop: Softmax Neural Networ Bacpropagation Learning Michael Rimer Computer Science Department Brigham Young University Provo, UT 84602, USA E-mail: mrimer@axon.cs.byu.edu Tony Martinez Computer Science
Curriculum Design Project with Virtual Manipulatives. Gwenanne Salkind. George Mason University EDCI 856. Dr. Patricia Moyer-Packenham
 Curriculum Design Project with Virtual Manipulatives Gwenanne Salkind George Mason University EDCI 856 Dr. Patricia Moyer-Packenham Spring 2006 Curriculum Design Project with Virtual Manipulatives Table
Curriculum Design Project with Virtual Manipulatives Gwenanne Salkind George Mason University EDCI 856 Dr. Patricia Moyer-Packenham Spring 2006 Curriculum Design Project with Virtual Manipulatives Table