Automatic document classification of biological literature
|
|
|
- Emil Fox
- 6 years ago
- Views:
Transcription
 Hans-Michael Muller (mueller@caltech.")
1 BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic document classification of biological literature BMC Bioinformatics 2006, 7:370 doi: / David Chen Hans-Michael Muller Paul W Sternberg (pws@caltech.edu) ISSN Article type Methodology article Submission date 28 March 2006 Acceptance date 7 August 2006 Publication date 7 August 2006 Article URL Like all articles in BMC journals, this peer-reviewed article was published immediately upon acceptance. It can be downloaded, printed and distributed freely for any purposes (see copyright notice below). Articles in BMC journals are listed in PubMed and archived at PubMed Central. For information about publishing your research in BMC journals or any BioMed Central journal, go to Chen et al., licensee BioMed Central Ltd. This is an open access article distributed under the terms of the Creative Commons Attribution License ( which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
2 Automatic document classification of biological literature David Chen 1, Hans-Michael Müller 1,, Paul W. Sternberg 1 1 Division of Biology and Howard Hughes Medical Institute, California Institute of Technology, Pasadena, California, United States of America Corresponding author addresses: DC: davidc@caltech.edu HMM: mueller@caltech.edu PWS: pws@caltech.edu
3 Abstract Background Document classification is a wide-spread problem with many applications, from organizing search engine snippets to spam filtering. We previously described Textpresso, a text-mining system for biological literature, which marks up full text according to a shallow ontology that includes terms of biological interest. This project investigates document classification in the context of biological literature, making use of the Textpresso markup of a corpus of Caenorhabditis elegans literature. Results We present a two-step text categorization algorithm to classify a corpus of C. elegans papers. Our classification method first uses a support vector machine-trained classifier, followed by a novel, phrase-based clustering algorithm. This clustering step autonomously creates cluster labels that are descriptive and understandable by humans. This clustering engine performed better on a standard test-set (Reuters 21578) compared to previously published results (F-value of 0.55 vs. 0.49), while producing cluster descriptions that appear more useful. A web interface allows researchers to quickly navigate through the hierarchy and look for documents that belong to a specific concept. Conclusions We have demonstrated a simple method to classify biological documents that embodies an improvement over current methods. While the classification results are currently optimized for Caenorhabditis elegans papers by human-created rules, the classification engine can be adapted to different types of documents. We have demonstrated this by presenting a web interface that allows researchers to quickly navigate through the hierarchy and look for documents that belong to a specific concept. Background With so many Biology papers being published each month, researchers have a difficult time keeping track with the latest developments or finding details that were not important when the paper was published. Automated information extraction and retrieval are thus important tools for biologists (for reviews, see [1-4]). The Textpresso text-mining engine has made progress in this direction with an ontology that marks up the biological concepts within the full-texts of Caenorhabditis elegans papers [5]. Using a simple ontology, we found that search efficiency was improved 3-fold when looking for two uniquely named genes and a term that means an interaction. Here we explore the prospect of further utilizing the ontology to aid performance when using an algorithm to classify papers. Within the field of information retrieval, text classification provides the means to drastically improve the efficiency of researchers. Hierarchical paper taxonomies allow users to focus on the topics and quickly locate papers of interest. In addition, taxonomies allow users to find papers that are similar. A well known taxonomy, Yahoo s Directory,
4 analogously allows users to quickly find internet sites of interest, by first descending down a topic tree. Many recent developments in the information retrieval field have focused on clustering ephemeral search results live clustering of search results from general web searches [6]. Here we investigate the specific problem of clustering Biology papers. A sizable number of Biology papers are published every month (e.g., approximately 60,000 were added to PubMed in January 2006), so automated procedures are necessary for a successful categorization of papers. On the other hand, Dickman noted that machine learning algorithms did better when more human-crafted rules were involved [7]. Thus, one of the main focuses of this clustering engine is to allow more human guidance than current state-of-the-art systems to obtain higher quality results. Support Vector Machines (SVM), with their strong theoretical foundations on structural risk minimization, have become popular tools in classification. The SVM algorithm works by learning a separating hyperplane that divides two groups of vectors. This separation requires that the text documents be represented as vectors, but this problem has been tackled in numerous classification and clustering algorithms. Generally, each word in the vocabulary of the corpus becomes a dimension, and a vector represents the number of occurrences of the respective words in the document. Word-stemming is utilized so that words such as cell and cells are counted together. Joachims showed that Support Vector Machines could classify papers more accurately than previous algorithms [8]. Support Vector Machines work well for text classification since there are many words in the vocabulary, yielding a high-dimensional vector space. At the same time, each paper might only use a small subset of the thousands of words in the vocabulary of the corpus. Support Vector Machines are thus well suited for such document vectors that are sparse but contain dense concepts (i.e., the words that are present in a document are important). While Support Vector Machines are powerful and allow the user much control of the classification, creating many subcategories and finding associated training papers would be prohibitively expensive in terms of human effort. Thus, another method must also be employed to more autonomously create categories and assign the documents to them. Conventional clustering algorithms, such as k-means, separate documents by vector representations, similar to those used in SVM, and then attempt to label the clusters. In contrast to such algorithms, recent research on clustering has focused on creating meaningful labels for the clusters, often by extracting phrases to represent underlying concepts [9]. Such algorithms are an active field of research, but many of the most successful algorithms are closed source. For example, Vivisimo has one of the best commercial clustering engines, capable of extracting a hierarchy of concepts and classifying a variety of documents, from search engine results to abstracts of scientific reports [10]. While many of the recent systems focus on clustering on-the-fly search results, our system performs the classification as a background task. This allows our system to utilize system resources more extensively without runtime as a constraint. For example, we can utilize the full text of the papers instead of just the abstracts. The
5 human-based guidance that our setup involves also provides more control of the produced taxonomy, to help ensure that the results match what a user would expect. Beil et al. described an algorithm to hierarchically classify documents based on frequent term sets [11]. Their system provided an intuitive way for users to understand the contents of the clusters. For example, the top clusters for a corpus of documents on the beach may be: sun, fun, beach, and surf. The second layer of clusters would be: sun, fun, surf, beach, etc. Such annotations marked a step forward from conventional clustering algorithms that would first cluster the papers and then attempt to label the clusters, usually producing labels that are difficult for humans to understand. Results We developed a document classification engine that can classify papers into a topic-based hierarchy. The engine is currently optimized for Caenorhabditis elegans papers by using human-created rules. The rules are in the form of a list of terms associated with each topic. The engine classifies all articles with the full-text available from Textpresso, which currently has over 7000 such papers. By combining two different methods, the classification results are more useful than conventional algorithms while minimizing the amount of manual curation needed. Support Vector Machine-based classifiers assign the documents into nine primary categories, and a phrase-based clustering process creates a hierarchy of up to 200 subcategories for each primary category and labels the papers with these finer descriptions. The classification engine outputs the taxonomy as a large number of HTML files, which allow users to intuitively parse through the hierarchy to find the papers belonging to a biological concept. Figure 1 presents an example of the interface that users browse through to find topics of interest. Classification by support vector machine The initial classification is done by Support Vector Machine, which assigns each paper into at least one of the nine main categories. The nine categories were taken from the chapters of WormBook: Genetics/Genomics, Molecular Biology, Cellular Biology, Sex Determination, Developmental Control, Signal Transduction, Neurobiology and Behavior, Ecology and Evolution, and WormMethods [12]. The Germline chapter from WormBook was excluded, since the category would contain too few papers (please see the Methods and Materials section for detailed analysis). These nine categories divide the nematode literature in a manner with which biologists are familiar, guaranteeing that the top layer of classification matches the expectations of users. Support Vector Machines learn a separating hyperplane that separates two groups of vectors. Following conventional practice when representing text documents as vectors, each dimension of the vector space represents a word in the corpus. When creating the vector representations, words that are not useful are skipped. Most of the rules, such as skipping stopwords and words that occur in too many or too few of the documents, apply to all text domains. A few domain-specific rules are utilized: when counting the number of occurrences of words in a documents, words that are in human-created lists of important words are multiplied by a boosting factor to increase the classification
6 performance. The domain-specific rules for skipping words and the boosting improvement are described in Methods. Since a paper can belong to more than one of the nine categories, the multi-class classification is done with nine runs of one-against-all classification for each paper. Oneagainst-all refers to the fact that each SVM classification decides whether a document belongs to a category or does not belong. In addition, the SVM step forces each paper to belong in at least one category, since the assumption is that all papers in the C. elegans Textpresso corpus discuss the biology of nematodes. The training set currently consists of 226 examples, but a training document may be a positive example for more than one category. Using 10-fold cross-validation, we achieved micro-averaged precision of 69.57% and micro-averaged recall of 65.17% (see the evaluation section for definitions of recall and precision). 10-fold cross-validation refers to dividing the training set into ten groups of 22 documents and then treating a different group as the test set during each of the ten runs. While the cross-validation performance looks low, the decision to allow a paper to belong in multiple categories would give even a human difficulty in classification, since there is no strict threshold for the extent to which a paper must discuss a category before being assigned to it. The distribution of the papers, which is shown in Table 1, appears reasonable to the expected number of articles that should discuss each topic. For example, many papers discuss cellular processes or structure, so the Cell Biology category is expected to be large. The WormMethods category is somewhat larger than expected because it also functions as a catch-all for worm papers that did not belong elsewhere. After SVM, the mean number of categories per paper is with standard deviation of The output of the SVM step serves directly as data to feed into the next step. Since there can be more than a thousand papers assigned to a category after SVM and such a number could easily be overwhelming, users are not given an interface to browse only the results of the SVM process. Instead, the clusters produced by phrases found within each category serve to further divide the papers within each of the nine main topics. Clustering by frequent phrases The key step in clustering is to find phrases that can serve as descriptive labels for the clusters. From informal analysis, phrases of two and three words were found to be descriptive and represented many Biology topics. Thus, for each of the nine categories, the most frequent two and three word phrases are automatically mined and considered as the possible clusters for the respective categories. A distinguishing aspect of clustering Biology literature is which types of phrases are preferred. In general searches, proper nouns, such as names of people and places, are highly descriptive and useful to quickly locate specific information. For Biology researchers, in contrast, there already exist tools to locate papers by specific authors and biological topics are preferred over names. Thus, the mark-up provided by Textpresso is used to automatically decide which phrases are likely to represent concepts. Furthermore, each of the nine categories has a list of manually curated words that should be
7 emphasized in the clusters. For example, the Genetics category emphasizes the words transposon, homolog, repeats, etc. These lists of words are used as human guidance to help the algorithm choose which phrases to use as potential clusters. The lists vary from 35 words for the smaller categories up to 83 words for the WormMethods category, so the combined human effort to construct all the lists is minimal. Both the lists of words and the rules that utilize the Textpresso markup are not necessary to the function of the system. They should be modified for enhanced clustering quality if using this system on a new corpus that has been marked up by Textpresso. After the program automatically checks that the phrases are not mentioned in too many papers in the category, parent-child relationships are found via a subsumption algorithm similar to what Sanderson and Croft describe (also described in the Materials and Methods section) [13]. Each cluster can have at most one parent to ensure an acylic graph. At the risk of creating extraneous clusters, the preference is that there exist enough clusters so that the leaves of the hierarchy are sufficiently descriptive to be useful. All papers are assigned to at most four clusters in each category, and papers that do not contain any of the phrases for a category are excluded from the classification for that category. Despite the customizations that tailor the engine to cluster Biology literature, the overall process can create a topic hierarchy from general search results. As a proof of principle, a program to cluster the top 150 results for a given query from Yahoo was created. The rules specific to Caenorhabditis elegans papers are ignored (i.e., the ontology is not used), and a few rules specific to snippets from search engines are inserted: words such as free and welcome are added to the list of words to skip. An online interface for the clustering engine is available [14]. Testing We used the Reuters test-set as a benchmark to compare the quality of the clustering engine against previously published results. This set consists of 21,578 news articles from 1987 that were later indexed by humans and is freely available for download [15]. Beil et al. used a subset of 8654 articles from the Reuters set [11]. This subset consists of those articles that were manually tagged to belong to exactly one topic. A common way to measure clustering quality among a hierarchy is to use the F-measure. First, the recall and precision for a given topic T k and cluster C j must be defined. The recall refers to the ability to retrieve all expected results while precision represents the portion of returned results that are correct. For each cluster and topic, the documents tagged with that topic represent the set of expected results and the cluster acts as the results returned.
8 Let n j, k denote the number of documents in cluster C j that also belong to topic T k ; that is, the number of correct results. n j, k Recall( Tk,C j ) = # Tk (1) n j, k Precision( Tk,C j ) = # C (2) where # Tk denotes the total number of documents with this topic and C j number of documents that belong in this cluster. The F-measure for the given pair of topic T k and cluster C j, is then 2* Recall* Precision measure ( T,C k j ) = Recall+ Precision F (3) j # denotes the The range of the F-measure falls between 0 to 1, with 1 indicating the best quality for a cluster. The overall F-measure for the entire hierarchy is the weighted average among the topics, choosing the cluster for each topic that gives the highest F-measure, i.e., it is the summation over all the topics, adding the F-measure from the best cluster for that topic multiplied by the number of documents that are known to belong in that topic divided by the total number of documents. Beil et al. obtained an overall F-value of 0.49 [11]. The clustering engine from this project obtained an improved F-value of 0.55, but the key advantage conferred by our system is that the produced clusters, labeled with phrases, are easier to understand than clusters annotated by term sets. For example, one of the top-level clusters our system produces on the Reuters set is last year, with child clusters such as trade surplus and trade deficit. These types of relationships between phrases would not be possible under Beil s system because their system finds term sets, and the next layers must include the previous layers: as illustrated in the Background section, the top clusters for a corpus of documents on the beach may be: "sun", "fun", "beach", and "surf." The second layer of clusters are then constrained to be: "sun, fun", "surf, beach", etc. As another comparison, Larson et al. obtained F-values that varied around 0.6 using a clustering engine that is designed to run quickly and scale linearly with the number of documents [16]. While they obtained fairly good results from the numerical measurement, their cluster annotations consist of the features that were considered important during clustering and may not necessarily be understandable to a human. These tests do not utilize the Textpresso ontology with the Reuters text. As a test of the SVM performance, classification on the top 10 Reuters categories was performed. This set consists of the 6490 training articles, and 2545 testing samples. The SVM classification obtained a micro-averaged F1 score of and macro-averaged F1 score of These scores slightly exceed the results that Debole and Sebastiani obtained on this set with SVM classification [17]. As Debole and Sebastiani describe, this Reuters subset is the easiest because it contains the most training examples. Such a test,
9 however, is a good measure for the top-level classification that SVM provides in our clustering engine, since each category should have a substantial number of training examples. The competitive SVM classification performance indicates that this initial classification stage performs as well as state-of-the-art methods. Discussion Accomplishments This clustering system provides an effective way to classify documents into a taxonomy, with category descriptions that are easily understandable by humans. The benchmarking experiments indicate that the clustering results are competitive with state-of-the-art algorithms. Such a taxonomy with useful cluster labels allows novices in the field to quickly discover the key concepts among the papers while enabling experts to browse through the hierarchy and quickly locate papers discussing a specific topic. The classifications also allow researchers to locate similar papers, by finding papers that contain the same concept. Both, the provision of key concepts of a research field as well as the ability to find similar papers, are not easily achieved by simply entering a set of keywords into a search engine. The software, along with source code, is available for download [18]. The human-provided guidance helps ensure higher quality clustering results. For example, the Sex Determination category provides the following for the top layer of choices: hermaphrodite male, sex determination, development gene, development cells, cells fate, vulval cells, anchor cells, and cells male. As a comparison, the search for sex determination Caenorhabditis elegans on ClusterMed, Vivisimo s engine to cluster up to 500 titles and abstracts from pubmed, yielded the top clusters as Fem, Dosage compensation, Behavior, Gld-1, Mab-3, Fog, Germ cells, Caenoharbdities Elegans Sex-Determining Gene Tra-2, cdna Sequence, Translational control, and Fish Medaka. Compared to Vivisimo s results, our labels emphasize concepts compared to gene names, which should be more useful for researchers trying to explore the field. The immediate goal of the project was to provide a way to classify Caenorhabditis elegans literature, but the process to classify text in another domain is fairly straightforward. The curator must first choose the primary categories, create lists of important words in each of these categories, and then identify training papers for these categories. Domain-specific rules may be needed in the code to specify which words should be skipped in the vector representations. For increased SVM performance, the SVM parameters should also be tuned for these categories, but this step can be automated by the software system once the training papers are found. If an ontology has been used to markup the text in the new domain, the rules used in the clustering step should be modified although an ontology is not required. The unique combination of Support Vector Machines with phrase-based clustering allows the creation of a topic taxonomy that is more guided, and thus, of higher quality than current state-of-the-art methods. At the same time, the amount of human guidance
10 required is kept limited to finding the initial training set for the SVM step. Other steps of human intervention such as finding lists of boosted words or rules for using the Textpresso markup are minimal compared to this step. Besides the utility of the entire system, the individual components of the project might be useful. As demonstrated with the clustering engine on Yahoo search results, documents or snippets from a general source may be used to construct a topic hierarchy. The phrasebased clustering algorithm, while currently optimized for a specific group of papers, can be adapted to a variety of different types of documents. An ontology is required for neither SVM classification nor phrase-based clustering. On-the-fly clustering of search results can also be performed on Caenorhabditis elegans literature, but the clustering engine is currently not optimized for such usage. Areas for improvement The SVM process provides acceptable performance, but further slight modifications may allow better performance. For example, recent reports have indicated superior text classification performance when using transductive SVM, which creates the separating hyperplane while maximizing the margin to both the training and testing vectors, compared to the inductive SVM that the system currently uses [19]. Another concern is the creation of the training set, finding the optimal precision and recall that can be obtained, and which documents to train on to minimize the work needed in making the training set. Schohn and Cohn developed an approach called active learning, an iterative process of identifying papers to add to the training set [20]. The clustering engine, with few published algorithms to compare to, is highly experimental. More human guidance could be implemented when choosing possible phrases or creating the hierarchy. Concepts may be found to be synonyms by looking in a knowledge source, such as the Metathesaurus included in the UMLS [21]. The UMLS also includes data sources that organize topics into a hierarchy. For example, the Medical Subject Headings included in UMLS can relate apoptosis as a child concept of cell death, which is a child concept of cell physiology, and so forth. Thus, by integrating these kinds of relations that have already been created by expert curators into the probabilistic method currently used, a better hierarchical tree could be produced. Conclusions We have presented a simple but effective two-step method to categorize a corpus of biological papers. It consists of a support vector machine component as well as a novel phrase-based clustering algorithm. The method automatically generates clusters with labels that are intuitive and understandable to humans. It is amenable to human intervention and modification such as hand-crafted rules, but can also be used in an unsupervised environment. This method performs competitively when compared to similar algorithms. Methods All software was written in Java to allow reusability of the written code. While Java may have longer run-times than comparable languages, this choice was considered appropriate
11 since the classification is done as a background task on the server. Thus, as long as the classification does not take excessively long (such as more than three days, which is a specification easily met for a corpus of seven thousand papers), the runtime speed was not a concern. A cronjob runs the classification engine weekly, and another cronjob copies the classification results to the public HTML folder. Thus, there is never any downtime from the user s perspective, but there may be times when the classification results are slightly out of date, when the newest papers have not been categorized yet. The classification for the C. elegans corpus can be accessed online through the Textpresso website [22]. Figure 2 illustrates the classification process. The xml files of the papers are converted into plain-text, and these plain-text files are then used to represent the documents as vectors, which are then fed into the SVM machinery, resulting in nine primary categories. The assignments of the papers into the categories are then used during phrase-based clustering, which uses both the plain-text files and the XML files. Support vector machine The plain-text papers are used as inputs to the SVM classification. In order to optimally form vector representations from the text documents, the words must first be parsed, and then non-useful words are skipped. Words are found by splitting at each space or hyphen character. Using domain-specific and general rules, certain words may be skipped: a list of 191 stop-words, which is applicable for most text classification tasks, contains prepositions and other such words that are not useful. Words that consist of just digits are also skipped. In addition, words that are less than three characters long can usually be skipped, but the words that often have special biological significance such as X, Y, XY, XO, XX and G are kept even though they are short. The words are mapped to feature stems by lower-casing the characters and applying the Porter Stemming algorithm [23]. The counts of the feature stems are recorded for each document, and the frequency counts of the features are used in the vector representations. Features that occur in more than 95% of the documents or are used less than three times are considered uninformative and are not used in forming the document vectors. Each of the remaining feature stems represents a dimension in the vector space. The feature counts for the document vectors are then weighted by the TF IDF scheme. # docs feature weight( tk, d j ) = tcount( tk, d j ) *(1+ log ) (4) dcount( t ) where tcount represents how often feature t k occurs in document d j and dcount represents how many documents contain t k. This is a conventional weighting scheme for SVM that emphasizes those terms that occur less frequently in the corpus. A noticeable performance gain can be obtained by boosting the feature-weights of those words that are important in each category by a factor of 5. This performance increase comes for free since the lists of boosted words should be prepared for the phrase-based clustering. The document vectors are then normalized to unit length 1, so that abnormally long or short documents do not adversely affect the training process. The nine SVM models for k
12 each category are then created with LIBSVM [24], a library that provides an implementation of SVM in Java. The model for each category is trained using cost and gamma parameters that have been tuned for that category, and shrinking is turned on. These parameters are found using a tool included with LIBSVM that performs a logarithmic grid search, with cost ranging from 2-5 to 2 15, multiplying by four for each step, and gamma ranging from 2-15 to 2 3, also multiplying by four for each step. Shrinking reduces the number of operations for the training process with minimal loss in accuracy. The training set is represented by a tab-delimited file that indicates to which categories each training paper is known to belong. The papers in the training set were found with keyword-based searches in Textpresso. For example, a sample of the top results for a search of genetics were added in the training set as examples of genetics papers, although some of these papers may have also been examples for other categories. After the training is complete, all documents in the corpus are classified one at a time. While classifying a paper, the probability that a paper belongs to each category is also calculated. If a paper is classified as not belonging to any of the nine categories, the paper is assigned to the category with the lowest probability of not belonging to it. This method allows a paper to belong to multiple categories and guarantees that each paper will be assigned to at least one category. The algorithm that implements probability estimates for SVM classification is described by Wu, et al [25]. The implementation has been slightly modified so the same seed is used when randomly assigning the documents into five groups for computing probability estimates; this ensures that results are the same from run to run without changing the purpose of the function provided by LIBSVM. Analysis of SVM decisions Instead of using the bag-of-words model, an alternative approach was to use the mark-up provided by Textpresso, which can parse for n-grams. For example, the phrase MAP kinase could be used as one dimension in the vector model instead of the bag-of-words model, where the phrase would be split into the words map and kinase. Another issue was that the full-text files provided by Textpresso include the references at the bottom of each paper. Thus, a good fraction of the words in each document were lists of author names and titles of cited papers. Finally, the boosting factor for words that were listed to be important was incremented from 0 to 9. All three issues were thoroughly investigated by performing runs with the varying parameters, and the results are presented in Table 2, with the standard deviations of the average precision and recall included in parentheses. The runs labeled untrimmed are the full-text papers on the bag-of-words model while the trimmed runs are also on the bag-of-words model, but trimming the paper on the last instance of literature cited, references, or acknowledgement and which is at least after 2/3 of the paper. The tests show that these citations actually help SVM performance, so they are kept in the production system. This makes sense since papers that share a topic tend to cite the same papers. In addition, automatically trimming the citations may not always work as intended since papers may delineate their references without words and only visual separations such as white space, which our PDF-parsing tool can not interpret.
13 A paired T-test of the F1 value between XML and untrimmed results has a probability of.8474, indicating that there is an 84.7% chance that the observed differences could be seen if using XML and untrimmed papers were the same. A paired T-test is appropriate since the varying boosting factor provides 10 pairs of data points. Hence, it is not statistically significant whether XML or the untrimmed articles are used. The untrimmed papers was decided to be the source since it is faster to parse than XML and the classification performance is not dependent on the quality of the markups provided by the ontology (which could be important if applying this classification system on a domain outside Caenorhabditis elegans). In addition, the optimum value for the boost factor on untrimmed papers is 5. Clustering by phrases To assist in mining phrases that describe concepts, each category has its own list of boosted words, and these lists also act as a form of human guidance to choose descriptive and useful phrases. These boosted words are crucial in deciding how to label potential clusters, or else the clusters in all categories would be dominated by the same common phrases in nematode biology. Most papers, for instance, mention gene expression and proteins, and phrases associated with these topics are frequently found. For the lists currently used for Caenorhabditis elegans literature, most of the words are the subchapters from WormBook. The table of contents for Developmental Control contains the subchapters Asymmetric cell division and axis formation in the embryo, translational control of maternal RNAs, Gastrulation in C. elegans, etc. Except for words that are not specific to the category such as C elegans, the words in the titles of the subchapters are included in the lists of important words. The lists of boosted words are provided in [Additional file 1]. The phrase extraction process begins by using the XML markup from Textpresso to locate 200 phrases that should be descriptive. Phrases consist of 2 or 3 consecutive XML elements. If any of these elements are labeled as pronoun, modality, or intention, then this is considered a junk element list. In addition, at least one element must be considered useful, which is met if it is labeled as function, entity_feature, process, organism, method, gene, transgene, allele, or cell. The purpose of these requirements is that the phrases contain a useful concept and to avoid phrases such as using with. These rules would need to be modified when clustering a text corpus marked up with a different ontology. In addition, general rules are applied: phrases that contain repeating words or too many stopwords are skipped, and the remaining candidate element-sets are counted in all the documents of the category. Sets of the same word stems are counted together so that phrases such as neurotransmitter transporters and transport neurotransmitters are counted together, but the phrase is labeled by the form it was seen the first time. In order to choose 200 phrases that could form the clusters in the category, the phrases are scored to emphasize phrases that are descriptive for the current category. The cover of a phrase is defined, as was done by Beil et al., to be the set of documents that contain at least one instance of that phrase [11]. In addition, the nested cover of a phrase is the
14 union of its own cover and the cover of all its child phrases. The mined phrases are weighted according to their cover size multiplied by the number of boosted words in the phrase. The presence of a word marked as gene by Textpresso increments the count of boosted words by.1 since phrases that describe genes are frequently important in biology. After automatically extracting and choosing the top 200 phrases, the remaining procedure for generating the hierarchy is general for all text domains. The trimmed, plain-text representations of all the papers in the category are loaded into memory since the XML sources are no longer needed. Phrases with a cover greater than 80% of the possible documents are excluded since they are too general to be useful. The subsumption processes is based on the assumption that two phrases that co-occur in the same sentence often must have some type of relationship. The parent-child relationships are found via a simple probabilistic model. Let x and y be two phrases that have been extracted and are possible clusters with a hierarchical relationship. Let P(x y) be the ratio of sentences containing y that also contain x. Now, if the limit of P(x y) approaches 1 and the limit of P(y x) approaches 0 with respect to all sentences in the corpus, then this implies that x can occur without y, but y is found every time x occurs. This implies that y is a child concept of x. The algorithm first checks that y does not contain more documents than x before assigning x as a parent of y. In addition, the algorithm will not assign the child to a potential parent if the parent already has 8 or more children unless this is the worst possible parent for the child. The hierarchical assignments begin with the x,y that give the greatest P(x y) and continue until the probability becomes less than 1%. P(x y) is computed as the count of combining both phrases divided by the count of phrase y. For performance reasons, the calculation of P(x y) does not require scanning the entire corpus; instead, we only need to check the documents that are known to contain at least phrase y to find the count of phrase y and when counting combined phrases, only the intersection of the covers of both phrases needs to be checked. After creating the hierarchy, all documents in the category must be assigned into the clusters, which are each labeled by a phrase. For each document, each possible cluster is weighed proportionally by the number of occurrences of the corresponding phrase and inversely proportionally to the nested cover of the cluster after the creation of the hierarchy. Each document is then assigned to the four clusters with the highest weights. The choice of four clusters is an arbitrary decision to prevent documents from belonging to too many clusters and overwhelming the user. To encourage user functionality, certain post-processing steps are used on the tree. In particular, clusters that are considered useless are removed. These include phrases that ended up with zero documents or leafs that end in a stopword. In addition, if the first layer contains fewer than eight categories, then the branch with the largest cover is moved up from the largest top layer. This last step is done to encourage user friendliness, to ensure that there exist a reasonable number of choices available.
15 Analysis of primary categories While all the nine categories are the primary sections from WormBook, the Germline section was excluded as a category because it would contain too few papers. To confirm this, an experiment was done with two runs of SVM classification. For the first run, 18 papers (the top results from Textpresso after searching for germline and manually checking their relevance) were labeled as instances of the Germline category. In addition, a subset of the existing training set was added, so that all 10 categories would have approximately the same number of training examples. For the second run, all Germline examples were labeled as Sex Determination (although two papers already were marked as instances of Sex Determination in the first run). The experiment shows that if Germline were a separate category, both the Sex Determination and Germline category would be much too small compared to the other categories as displayed in Table 3. Thus, these two categories are treated the same, since the Germline is a concept frequently related to Sex Determination. All SVM training was done with cost of 5 and gamma of 1.0. Authors contributions DC devised and developed all aspects of the algorithm, performed the computational experiments and analyzed them, implemented the web-interface and its underlying dataprocessing and wrote the manuscript. HMM initiated the project, provided the Textpresso database and infrastructure, suggested ideas and edited the manuscript. PWS edited the manuscript, provided materials and supervised the project. All authors read and approved the final manuscript. Acknowledgements We thank the Caltech WormBase group for discussions. This project was funded by the generosity of Dr. Anthony Skjellum via the SURF program at the California Institute of Technology, and the National Human Genome Research Institute at the US National Institutes of Health # P41 HG02223 and # HG
16 References 1. Andrade MA, Bork P: Automated extraction or information in molecular biology. FEBS Lett 2000, 476: De Bruijn B, Martin J: Getting to the (c)ore of knowledge: Mining biomedical literature. Int J Med Inf 2002, 67: Staab S (editor): Mining information for function genomics. IEEE Intell Syst 2002, 17: Jensen LJ, Saric J, Bork P: Literature mining for the biologist: from information retrieval to biological discovery. Nature Reviews Genetics, 2006, 7: Muller HM, Kenny EE, Sternberg PW: Textpresso: An ontology-based information retrieval and extraction system for biological literature. PLoS Biol 2004, 2: e Ferragina P, Gulli A: The anatomy of a hierarchical clustering engine for Webpage, news and book snippets. In Proceedings of the Fourth IEEE International Conference on Data Mining; 2004: Dickman S: Tough Mining. PLoS Biol 2003, 1: e Joachims T: Text Categorization with Suport Vector Machines: Learning with Many Relevant Features. In Proceedings of the 10 th European Conference on Machine Learning; 1998: Hammouda K, Kamel M: Efficient Phrase-based Document Indexing for Web Document Clustering. IEEE Transactions on Knowledge and Data Engineering 2004, 16: Vivisimo: Clustering automatic categorization and meta-search software [ 11. Beil F, Ester M, Xu X: Frequent term-based text clustering. In Proceedings of the Eighth ACM SIGKDD 2002, WormBook: Online Review of C. elegans Biology [ 13. Sanderson M, Croft B: Deriving concept hierarchies from text. In Proceedings of the 22 nd ACM SIGIR; 1999: Online interface to clustering engine of Yahoo search snippets [ 15. Reuters text categorization test collection distribution 1.0 [ 16. Larsen B, Aone C: Fast and effective text mining using linear-time document clustering. In Proceedings of the Fifth ACM SIGKDD; 1999: Debole F, Sebastiani F: An analysis of the relative hardness of Reuters subsets. Journal of the American Society for Information Science and Technology 2005, 56: Download site for automatic classification software [ 19. Joachims T: Transductive Inference for Text Classification using Support Vector Machines. In Proceedings of the 16th ICML; 1999: Schohn, G., Cohn, D.: Less is more: Active Learning with support vector machines. In Proceedings of the 17 th ICML; 2000: Unified Medical Language System [ 22. Textpresso: An information retrieval and extraction system for biological literature [
17 23. Porter, MF: An algorithm for suffix stripping. Program 1980, 14: LIBSVM: a library for support vector machines [ 25. Wu T, Lin C, Weng RC: Probability estimates for multi-class classification by pairwise coupling. J. Machine Learning Research 2004, 5: Figures Figure 1. An example of the clustering results from the Sex Determination category. An intuitive interface allows users to quickly locate the topic of interest. The topics listed were generated automatically during the phrase-based clustering step. Figure 2. Overview of the classification process Full-text papers are taken from the Textpresso corpus and processed via SVM and phrase-base clustering. The end result is a large set of html files displaying the paper taxonomy.
18 Tables Table 1. Distribution of training examples and SVM output among the nine main categories. Number of examples in training set Number assigned Genetics Molecular Biology Cellular Biology Sex Determination Developmental Control Signal Transduction Neurobiology and Behavior Ecology and Evolution WormMethods Table 2. Comparison of boosting and using XML on SVM performance with 10- fold cross validation on training set Average precision (sigma) Average recall (sigma) F1 score XML (boost 0) (0.0913) (0.0961) Untrimmed (boost 0) (0.0953) (0.1028) Trimmed (boost 0) (0.1005) (0.1016) XML (boost 1) (0.0970) (0.0877) Untrimmed (boost 1) (0.0864) (0.0918) Trimmed (boost 1) (0.0965) (0.0996) XML (boost 2) (0.0790) (0.0775) Untrimmed (boost 2) (0.0655) (0.0761) Trimmed (boost 2) (0.0618) (0.0834) XML (boost 3) (0.0770) (0.0755) Untrimmed (boost 3) (0.0546) (0.0622) Trimmed (boost 3) (0.0478) (0.0593) XML (boost 4) (0.0857) (0.0897) Untrimmed (boost 4) (0.0624) (0.0745) Trimmed (boost 4) (0.0640) (0.0766) XML (boost 5) (0.0908) (0.1035) Untrimmed (boost 5) (0.0746) (0.0655) Trimmed (boost 5) (0.0817) (0.0863) XML (boost 6) (0.0781) (0.0758) Untrimmed (boost 6) (0.0859) (0.0798) Trimmed (boost 6) (0.0929) (0.0966) XML (boost 7) (0.0737) (0.0784)
19 Untrimmed (boost 7) (0.0851) (0.0864) Trimmed (boost 7) (0.0869) (0.0987) XML (boost 8) (0.0709) (0.0886) Untrimmed (boost 8) (0.0682) (0.0704) Trimmed (boost 8) (0.0759) (0.0939) XML (boost 9) (0.0748) (0.0906) Untrimmed (boost 9) (0.0722) (0.0724) Trimmed (boost 9) (0.0775) (0.0963) Table 3. Comparison of number of assigned documents when germline is available as a category With Germline as a category Training Documents examples assigned Without Germline as a category Training Documents examples assigned Genetics Molecular Biology Cellular Biology Sex Determination Developmental Control Signal Transduction Neurobiology and Behavior Ecology and Evolution WormMethods Germline Additional Files Additional file 1 File format: DOC Title: List of boosted words for the nine primary categories Description: Each category contains its own list of words that are given special emphasis during SVM and phrase-based clustering
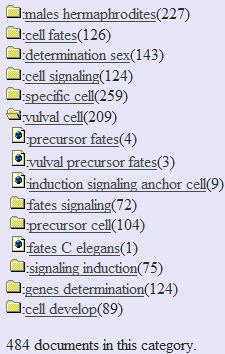
20 Figure 1
21 Articles with XML mark-up from Textpresso Vector Representations of Full-Text Support Vector Machine Articles assigned to nine main categories Convert to plain text Plain-Text Articles Phrase-Based Clustering HTML files Figure 2
22 Additional files provided with this submission: Additional file 1 : Supplemental Material.doc : 59Kb
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Exposé for a Master s Thesis
 Exposé for a Master s Thesis Stefan Selent January 21, 2017 Working Title: TF Relation Mining: An Active Learning Approach Introduction The amount of scientific literature is ever increasing. Especially
Exposé for a Master s Thesis Stefan Selent January 21, 2017 Working Title: TF Relation Mining: An Active Learning Approach Introduction The amount of scientific literature is ever increasing. Especially
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Web as Corpus. Corpus Linguistics. Web as Corpus 1 / 1. Corpus Linguistics. Web as Corpus. web.pl 3 / 1. Sketch Engine. Corpus Linguistics
 (L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
(L615) Markus Dickinson Department of Linguistics, Indiana University Spring 2013 The web provides new opportunities for gathering data Viable source of disposable corpora, built ad hoc for specific purposes
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF)
") SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
SINGLE DOCUMENT AUTOMATIC TEXT SUMMARIZATION USING TERM FREQUENCY-INVERSE DOCUMENT FREQUENCY (TF-IDF) Hans Christian 1 ; Mikhael Pramodana Agus 2 ; Derwin Suhartono 3 1,2,3 Computer Science Department,
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
AQUA: An Ontology-Driven Question Answering System
 AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
AQUA: An Ontology-Driven Question Answering System Maria Vargas-Vera, Enrico Motta and John Domingue Knowledge Media Institute (KMI) The Open University, Walton Hall, Milton Keynes, MK7 6AA, United Kingdom.
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Houghton Mifflin Online Assessment System Walkthrough Guide
 Houghton Mifflin Online Assessment System Walkthrough Guide Page 1 Copyright 2007 by Houghton Mifflin Company. All Rights Reserved. No part of this document may be reproduced or transmitted in any form
Houghton Mifflin Online Assessment System Walkthrough Guide Page 1 Copyright 2007 by Houghton Mifflin Company. All Rights Reserved. No part of this document may be reproduced or transmitted in any form
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Universiteit Leiden ICT in Business
 Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Universiteit Leiden ICT in Business Ranking of Multi-Word Terms Name: Ricardo R.M. Blikman Student-no: s1184164 Internal report number: 2012-11 Date: 07/03/2013 1st supervisor: Prof. Dr. J.N. Kok 2nd supervisor:
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining
 Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining
 Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Evaluation of Usage Patterns for Web-based Educational Systems using Web Mining Dave Donnellan, School of Computer Applications Dublin City University Dublin 9 Ireland daviddonnellan@eircom.net Claus Pahl
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Ontologies vs. classification systems
 Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE. Pierre Foy
 TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
TIMSS ADVANCED 2015 USER GUIDE FOR THE INTERNATIONAL DATABASE Pierre Foy TIMSS Advanced 2015 orks User Guide for the International Database Pierre Foy Contributors: Victoria A.S. Centurino, Kerry E. Cotter,
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
A Comparison of Two Text Representations for Sentiment Analysis
 010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
010 International Conference on Computer Application and System Modeling (ICCASM 010) A Comparison of Two Text Representations for Sentiment Analysis Jianxiong Wang School of Computer Science & Educational
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Speech Recognition at ICSI: Broadcast News and beyond
 Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Speech Recognition at ICSI: Broadcast News and beyond Dan Ellis International Computer Science Institute, Berkeley CA Outline 1 2 3 The DARPA Broadcast News task Aspects of ICSI
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Cross-Lingual Text Categorization
 Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Cross-Lingual Text Categorization Nuria Bel 1, Cornelis H.A. Koster 2, and Marta Villegas 1 1 Grup d Investigació en Lingüística Computacional Universitat de Barcelona, 028 - Barcelona, Spain. {nuria,tona}@gilc.ub.es
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
PowerTeacher Gradebook User Guide PowerSchool Student Information System
 PowerSchool Student Information System Document Properties Copyright Owner Copyright 2007 Pearson Education, Inc. or its affiliates. All rights reserved. This document is the property of Pearson Education,
PowerSchool Student Information System Document Properties Copyright Owner Copyright 2007 Pearson Education, Inc. or its affiliates. All rights reserved. This document is the property of Pearson Education,
Matching Similarity for Keyword-Based Clustering
 Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Matching Similarity for Keyword-Based Clustering Mohammad Rezaei and Pasi Fränti University of Eastern Finland {rezaei,franti}@cs.uef.fi Abstract. Semantic clustering of objects such as documents, web
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Speech Emotion Recognition Using Support Vector Machine
 Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Speech Emotion Recognition Using Support Vector Machine Yixiong Pan, Peipei Shen and Liping Shen Department of Computer Technology Shanghai JiaoTong University, Shanghai, China panyixiong@sjtu.edu.cn,
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments
 Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
Product Feature-based Ratings foropinionsummarization of E-Commerce Feedback Comments Vijayshri Ramkrishna Ingale PG Student, Department of Computer Engineering JSPM s Imperial College of Engineering &
CS 446: Machine Learning
 CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
CS 446: Machine Learning Introduction to LBJava: a Learning Based Programming Language Writing classifiers Christos Christodoulopoulos Parisa Kordjamshidi Motivation 2 Motivation You still have not learnt
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models
 Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Learning Structural Correspondences Across Different Linguistic Domains with Synchronous Neural Language Models Stephan Gouws and GJ van Rooyen MIH Medialab, Stellenbosch University SOUTH AFRICA {stephan,gvrooyen}@ml.sun.ac.za
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Automating Outcome Based Assessment
 Automating Outcome Based Assessment Suseel K Pallapu Graduate Student Department of Computing Studies Arizona State University Polytechnic (East) 01 480 449 3861 harryk@asu.edu ABSTRACT In the last decade,
Automating Outcome Based Assessment Suseel K Pallapu Graduate Student Department of Computing Studies Arizona State University Polytechnic (East) 01 480 449 3861 harryk@asu.edu ABSTRACT In the last decade,
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
CREATING SHARABLE LEARNING OBJECTS FROM EXISTING DIGITAL COURSE CONTENT
 CREATING SHARABLE LEARNING OBJECTS FROM EXISTING DIGITAL COURSE CONTENT Rajendra G. Singh Margaret Bernard Ross Gardler rajsingh@tstt.net.tt mbernard@fsa.uwi.tt rgardler@saafe.org Department of Mathematics
CREATING SHARABLE LEARNING OBJECTS FROM EXISTING DIGITAL COURSE CONTENT Rajendra G. Singh Margaret Bernard Ross Gardler rajsingh@tstt.net.tt mbernard@fsa.uwi.tt rgardler@saafe.org Department of Mathematics
Customized Question Handling in Data Removal Using CPHC
 International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 1, Issue 8, December 2014, PP 29-34 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Customized
International Journal of Research Studies in Computer Science and Engineering (IJRSCSE) Volume 1, Issue 8, December 2014, PP 29-34 ISSN 2349-4840 (Print) & ISSN 2349-4859 (Online) www.arcjournals.org Customized
Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge
 Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
Innov High Educ (2009) 34:93 103 DOI 10.1007/s10755-009-9095-2 Maximizing Learning Through Course Alignment and Experience with Different Types of Knowledge Phyllis Blumberg Published online: 3 February
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS
 OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
OPTIMIZATINON OF TRAINING SETS FOR HEBBIAN-LEARNING- BASED CLASSIFIERS Václav Kocian, Eva Volná, Michal Janošek, Martin Kotyrba University of Ostrava Department of Informatics and Computers Dvořákova 7,
NCEO Technical Report 27
 Home About Publications Special Topics Presentations State Policies Accommodations Bibliography Teleconferences Tools Related Sites Interpreting Trends in the Performance of Special Education Students
Home About Publications Special Topics Presentations State Policies Accommodations Bibliography Teleconferences Tools Related Sites Interpreting Trends in the Performance of Special Education Students
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING
 A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING Yong Sun, a * Colin Fidge b and Lin Ma a a CRC for Integrated Engineering Asset Management, School of Engineering Systems, Queensland
A GENERIC SPLIT PROCESS MODEL FOR ASSET MANAGEMENT DECISION-MAKING Yong Sun, a * Colin Fidge b and Lin Ma a a CRC for Integrated Engineering Asset Management, School of Engineering Systems, Queensland
A study of speaker adaptation for DNN-based speech synthesis
 A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
A study of speaker adaptation for DNN-based speech synthesis Zhizheng Wu, Pawel Swietojanski, Christophe Veaux, Steve Renals, Simon King The Centre for Speech Technology Research (CSTR) University of Edinburgh,
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
The University of Amsterdam s Concept Detection System at ImageCLEF 2011
 The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
The University of Amsterdam s Concept Detection System at ImageCLEF 2011 Koen E. A. van de Sande and Cees G. M. Snoek Intelligent Systems Lab Amsterdam, University of Amsterdam Software available from:
Evidence for Reliability, Validity and Learning Effectiveness
 PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
PEARSON EDUCATION Evidence for Reliability, Validity and Learning Effectiveness Introduction Pearson Knowledge Technologies has conducted a large number and wide variety of reliability and validity studies
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Organizational Knowledge Distribution: An Experimental Evaluation
 Association for Information Systems AIS Electronic Library (AISeL) AMCIS 24 Proceedings Americas Conference on Information Systems (AMCIS) 12-31-24 : An Experimental Evaluation Surendra Sarnikar University
Association for Information Systems AIS Electronic Library (AISeL) AMCIS 24 Proceedings Americas Conference on Information Systems (AMCIS) 12-31-24 : An Experimental Evaluation Surendra Sarnikar University
CHAPTER 4: REIMBURSEMENT STRATEGIES 24
 CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
CHAPTER 4: REIMBURSEMENT STRATEGIES 24 INTRODUCTION Once state level policymakers have decided to implement and pay for CSR, one issue they face is simply how to calculate the reimbursements to districts
The Role of String Similarity Metrics in Ontology Alignment
 The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
The Role of String Similarity Metrics in Ontology Alignment Michelle Cheatham and Pascal Hitzler August 9, 2013 1 Introduction Tim Berners-Lee originally envisioned a much different world wide web than
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
arxiv: v1 [math.at] 10 Jan 2016
![arxiv: v1 [math.at] 10 Jan 2016](/thumbs/72/66271209.jpg "arxiv: v1 [math.at] 10 Jan 2016") THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
THE ALGEBRAIC ATIYAH-HIRZEBRUCH SPECTRAL SEQUENCE OF REAL PROJECTIVE SPECTRA arxiv:1601.02185v1 [math.at] 10 Jan 2016 GUOZHEN WANG AND ZHOULI XU Abstract. In this note, we use Curtis s algorithm and the
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
The taming of the data:
 The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
The taming of the data: Using text mining in building a corpus for diachronic analysis Stefania Degaetano-Ortlieb, Hannah Kermes, Ashraf Khamis, Jörg Knappen, Noam Ordan and Elke Teich Background Big data
Notes on The Sciences of the Artificial Adapted from a shorter document written for course (Deciding What to Design) 1
 1") Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
Notes on The Sciences of the Artificial Adapted from a shorter document written for course 17-652 (Deciding What to Design) 1 Ali Almossawi December 29, 2005 1 Introduction The Sciences of the Artificial
The Indices Investigations Teacher s Notes
 The Indices Investigations Teacher s Notes These activities are for students to use independently of the teacher to practise and develop number and algebra properties.. Number Framework domain and stage:
The Indices Investigations Teacher s Notes These activities are for students to use independently of the teacher to practise and develop number and algebra properties.. Number Framework domain and stage:
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
On-the-Fly Customization of Automated Essay Scoring
 Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Research Report On-the-Fly Customization of Automated Essay Scoring Yigal Attali Research & Development December 2007 RR-07-42 On-the-Fly Customization of Automated Essay Scoring Yigal Attali ETS, Princeton,
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Memory-based grammatical error correction
 Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Memory-based grammatical error correction Antal van den Bosch Peter Berck Radboud University Nijmegen Tilburg University P.O. Box 9103 P.O. Box 90153 NL-6500 HD Nijmegen, The Netherlands NL-5000 LE Tilburg,
Chamilo 2.0: A Second Generation Open Source E-learning and Collaboration Platform
 Chamilo 2.0: A Second Generation Open Source E-learning and Collaboration Platform doi:10.3991/ijac.v3i3.1364 Jean-Marie Maes University College Ghent, Ghent, Belgium Abstract Dokeos used to be one of
Chamilo 2.0: A Second Generation Open Source E-learning and Collaboration Platform doi:10.3991/ijac.v3i3.1364 Jean-Marie Maes University College Ghent, Ghent, Belgium Abstract Dokeos used to be one of
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
A Bayesian Learning Approach to Concept-Based Document Classification
 Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Databases and Information Systems Group (AG5) Max-Planck-Institute for Computer Science Saarbrücken, Germany A Bayesian Learning Approach to Concept-Based Document Classification by Georgiana Ifrim Supervisors
Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability
 Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability Shih-Bin Chen Dept. of Information and Computer Engineering, Chung-Yuan Christian University Chung-Li, Taiwan
Developing True/False Test Sheet Generating System with Diagnosing Basic Cognitive Ability Shih-Bin Chen Dept. of Information and Computer Engineering, Chung-Yuan Christian University Chung-Li, Taiwan
The Strong Minimalist Thesis and Bounded Optimality
 The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
The Strong Minimalist Thesis and Bounded Optimality DRAFT-IN-PROGRESS; SEND COMMENTS TO RICKL@UMICH.EDU Richard L. Lewis Department of Psychology University of Michigan 27 March 2010 1 Purpose of this
STUDENT MOODLE ORIENTATION
 BAKER UNIVERSITY SCHOOL OF PROFESSIONAL AND GRADUATE STUDIES STUDENT MOODLE ORIENTATION TABLE OF CONTENTS Introduction to Moodle... 2 Online Aptitude Assessment... 2 Moodle Icons... 6 Logging In... 8 Page
BAKER UNIVERSITY SCHOOL OF PROFESSIONAL AND GRADUATE STUDIES STUDENT MOODLE ORIENTATION TABLE OF CONTENTS Introduction to Moodle... 2 Online Aptitude Assessment... 2 Moodle Icons... 6 Logging In... 8 Page
MOODLE 2.0 GLOSSARY TUTORIALS
 BEGINNING TUTORIALS SECTION 1 TUTORIAL OVERVIEW MOODLE 2.0 GLOSSARY TUTORIALS The glossary activity module enables participants to create and maintain a list of definitions, like a dictionary, or to collect
BEGINNING TUTORIALS SECTION 1 TUTORIAL OVERVIEW MOODLE 2.0 GLOSSARY TUTORIALS The glossary activity module enables participants to create and maintain a list of definitions, like a dictionary, or to collect
To link to this article: PLEASE SCROLL DOWN FOR ARTICLE
 This article was downloaded by: [Dr Brian Winkel] On: 19 November 2014, At: 04:59 Publisher: Taylor & Francis Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer
This article was downloaded by: [Dr Brian Winkel] On: 19 November 2014, At: 04:59 Publisher: Taylor & Francis Informa Ltd Registered in England and Wales Registered Number: 1072954 Registered office: Mortimer
How to read a Paper ISMLL. Dr. Josif Grabocka, Carlotta Schatten
 How to read a Paper ISMLL Dr. Josif Grabocka, Carlotta Schatten Hildesheim, April 2017 1 / 30 Outline How to read a paper Finding additional material Hildesheim, April 2017 2 / 30 How to read a paper How
How to read a Paper ISMLL Dr. Josif Grabocka, Carlotta Schatten Hildesheim, April 2017 1 / 30 Outline How to read a paper Finding additional material Hildesheim, April 2017 2 / 30 How to read a paper How
BMC Medical Informatics and Decision Making 2012, 12:33
 BMC Medical Informatics and Decision Making This Provisional PDF corresponds to the article as it appeared upon acceptance. Fully formatted PDF and full text (HTML) versions will be made available soon.
BMC Medical Informatics and Decision Making This Provisional PDF corresponds to the article as it appeared upon acceptance. Fully formatted PDF and full text (HTML) versions will be made available soon.
Mining Student Evolution Using Associative Classification and Clustering
 Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
The Internet as a Normative Corpus: Grammar Checking with a Search Engine
 The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
The Internet as a Normative Corpus: Grammar Checking with a Search Engine Jonas Sjöbergh KTH Nada SE-100 44 Stockholm, Sweden jsh@nada.kth.se Abstract In this paper some methods using the Internet as a
Automating the E-learning Personalization
 Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Automating the E-learning Personalization Fathi Essalmi 1, Leila Jemni Ben Ayed 1, Mohamed Jemni 1, Kinshuk 2, and Sabine Graf 2 1 The Research Laboratory of Technologies of Information and Communication
Field Experience Management 2011 Training Guides
 Field Experience Management 2011 Training Guides Page 1 of 40 Contents Introduction... 3 Helpful Resources Available on the LiveText Conference Visitors Pass... 3 Overview... 5 Development Model for FEM...
Field Experience Management 2011 Training Guides Page 1 of 40 Contents Introduction... 3 Helpful Resources Available on the LiveText Conference Visitors Pass... 3 Overview... 5 Development Model for FEM...
What can I learn from worms?
 What can I learn from worms? Stem cells, regeneration, and models Lesson 7: What does planarian regeneration tell us about human regeneration? I. Overview In this lesson, students use the information that
What can I learn from worms? Stem cells, regeneration, and models Lesson 7: What does planarian regeneration tell us about human regeneration? I. Overview In this lesson, students use the information that
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
AGENDA LEARNING THEORIES LEARNING THEORIES. Advanced Learning Theories 2/22/2016
 AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
AGENDA Advanced Learning Theories Alejandra J. Magana, Ph.D. admagana@purdue.edu Introduction to Learning Theories Role of Learning Theories and Frameworks Learning Design Research Design Dual Coding Theory
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Term Weighting based on Document Revision History
 Term Weighting based on Document Revision History Sérgio Nunes, Cristina Ribeiro, and Gabriel David INESC Porto, DEI, Faculdade de Engenharia, Universidade do Porto. Rua Dr. Roberto Frias, s/n. 4200-465
Term Weighting based on Document Revision History Sérgio Nunes, Cristina Ribeiro, and Gabriel David INESC Porto, DEI, Faculdade de Engenharia, Universidade do Porto. Rua Dr. Roberto Frias, s/n. 4200-465
Performance Analysis of Optimized Content Extraction for Cyrillic Mongolian Learning Text Materials in the Database
 Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized
Journal of Computer and Communications, 2016, 4, 79-89 Published Online August 2016 in SciRes. http://www.scirp.org/journal/jcc http://dx.doi.org/10.4236/jcc.2016.410009 Performance Analysis of Optimized