CS 4649/7649 Robot Intelligence: Planning
|
|
|
- Angelina Sparks
- 5 years ago
- Views:
Transcription
1 CS 4649/7649 Robot Intelligence: Planning RL Sungmoon Joo School of Interactive Computing College of Computing Georgia Institute of Technology S. Joo 1 *Slides based in part on Dr. Mike Stilman and Dr. Pieter Abbeel s slides Administrative Final Project CS project proposal: Due Oct. 30 ( a pdf file to me and Saul) - project final report: Due Dec. 4, 23:59pm, conference-style paper - project presentation: Dec. 11, 11:30am - 2:20pm CS project reviewer assignment: Oct. 28 ( 2 ~ 3 reviewers/project) - proposal review report: Due Nov. 6 - project review report(for the assigned project): Due Dec. 11, 11:30am - project presentation review*(for all presentation): Due Dec. 11, 2:20pm *presentation review sheets will be provided S. Joo (sungmoon.joo@cc.gatech.edu) 2 1
2 MDP with unknown models Reinforcement Learning - Model-based Learning : Learn the model first, then solve the (approx.) MDP with VI or PI - Model-free Learning : Direct Evaluation [performs policy evaluation] : Temporal Difference Learning [performs policy evaluation] : Q-Learning [learns optimal state-action value function Q*] : Policy search [learns optimal policy from subset of all policies] S. Joo (sungmoon.joo@cc.gatech.edu) 3 Reinforcement Learning Idea - Receive feedback in the form of rewards - Agent s is defined by the reward function utility(e.g. average/accumulated sum of the rewards) - Must (learn to) act so as to maximize expected rewards - Learning is based on observed samples of outcomes Agent Rewards State transition action Environment S. Joo (sungmoon.joo@cc.gatech.edu) 4 2

3 Machine Learning Supervised Learning - The most common machine learning category - Trying to map some data points to some function(or function approximation) that best approximates the data. Unsupervised Learning - Analyzing data without any sort of function to map to. Figuring out what the data is w/o any feedback - Unsupervised in the sense that the algorithm doesn t know what the output should be. Instead, the algorithm has to come up with it itself. Reinforcement Learning - Figuring out how to play a multistage game with rewards and payoffs to optimize the life of the agent - Similar to supervised learning, but with reward. S. Joo (sungmoon.joo@cc.gatech.edu) 5 RL examples: Inverted Pendulum S. Joo (sungmoon.joo@cc.gatech.edu) 6 3
 7 Markov Decision Process - A set of states s S - A set of actions (per state) A - A transition model T(s s,a) - A reward function R(s,a,s ) Reinforcement Learning Looking for a policy for MDP,")
4 RL examples: Helicopter Flying S. Joo 7 Markov Decision Process - A set of states s S - A set of actions (per state) A - A transition model T(s s,a) - A reward function R(s,a,s ) Reinforcement Learning Looking for a policy for MDP, but don t know T and/or R - Don t know what the actions do and/or which states are good Reinforcement Learning MDP with T and/or R unknown - Model-based learning - Model-free learning : Direct evaluation (performs policy evaluation) : Temporal difference learning (performs policy evaluation) : Q-Learning (learns optimal state-action value function Q) : S. Joo (sungmoon.joo@cc.gatech.edu) 8 4
 -Discover an estimate of R(s,a,s ) when we experience (s,a,s ) Step 2: Solving the MDP with the learned model -Value iteration, or")
5 Model-based Learning Idea: -Step 1: Learn the model empirically through experience -Step 2: Solve for policy/values as if the learned model were correct Step 1: Empirical model learning -Count outcomes s for each s,a -Normalize to give an estimate of T(s s, a) -Discover an estimate of R(s,a,s ) when we experience (s,a,s ) Step 2: Solving the MDP with the learned model -Value iteration, or policy iteration, as before S. Joo (sungmoon.joo@cc.gatech.edu) 9 Model Learning Example S. Joo (sungmoon.joo@cc.gatech.edu) 10 5
 11 Learning the Model in MBL Estimate P(s) from samples -Samples -Estimate Estimate P(s s,a) from samples -Samples -Estimate Why does this work?")
6 Model-based vs Model-free CS4649/7649 students S. Joo 11 Learning the Model in MBL Estimate P(s) from samples -Samples -Estimate Estimate P(s s,a) from samples -Samples -Estimate Why does this work? B/C samples appear with the right frequencies! S. Joo 12 6
7 MBL vs MFL Model-based RL -First act in MDP and learn T/R -Then value iteration or policy iteration with learned T/R -Advantage: efficient use of data -Disadvantage: need sufficient date/requires building a model for T/R Model-free RL -Bypass the need to learn T/R -Methods to evaluate V π, the value function for a fixed policy π without knowing T, R: (i) Direct Evaluation (ii) Temporal Difference Learning -Method to learn π*, Q*, V* without knowing T, R (iii) Q-Learning S. Joo (sungmoon.joo@cc.gatech.edu) 13 RL examples: Table Tennis S. Joo (sungmoon.joo@cc.gatech.edu) 14 7
8 MFL Want to compute an expectation weighted by P(x): Model-based: estimate P(x) from samples, compute expectation Model-free: estimate expectation directly from samples Why does this work? Because samples appear with the right frequencies! S. Joo 15 MFL: Direct Evaluation Goal: Compute values for each state under π Idea: Average together observed sample values - Act according to π - Every time you visit a state, write down what the sum of discounted rewards accumulate from state s onwards - Average those samples S. Joo (sungmoon.joo@cc.gatech.edu) 16 8

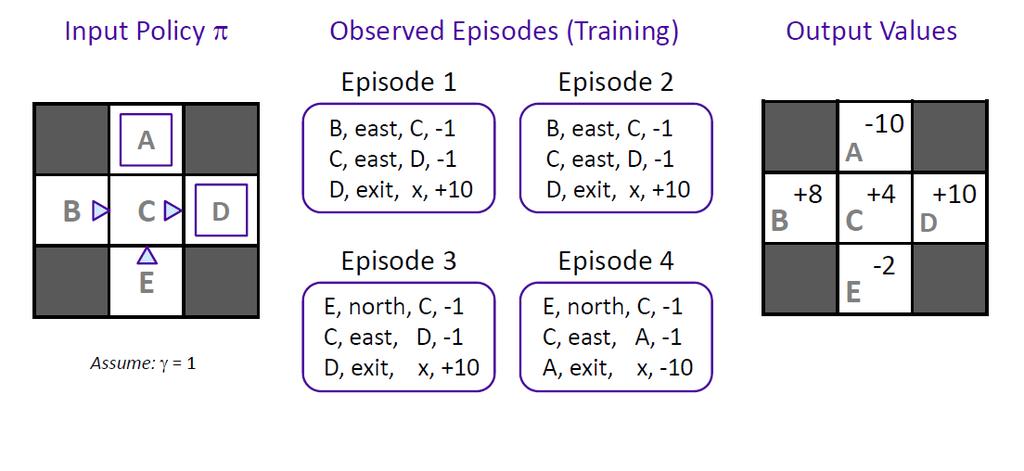
9 Direct Evaluation Example S. Joo 17 Direct Evaluation Example S. Joo 18 9

10 MFL: Direct Evaluation What is good about DE? - It s easy to understand - It doesn t require any knowledge of T, R - It eventually computes the correct average values, using just sample transitions What is bad about DE? - It wastes information about state connections - Each state must be learned separately - So, it takes a long time to learn S. Joo (sungmoon.joo@cc.gatech.edu) 19 RL examples: Pancake Flipping S. Joo (sungmoon.joo@cc.gatech.edu) 20 10

11 Why Not Use Policy Evaluation? Simplified Bellman updates calculate V for a fixed policy: Each round, replace V with a one step look ahead layer over V This approach fully exploited the connections between the states Unfortunately, we need T and R to do it! Key question: how can we do this update to V without knowing T and R? In other words, how do we take a weighted average without knowing the weights? S. Joo (sungmoon.joo@cc.gatech.edu) 21 Sample-based Policy Evaluation? We want to improve our estimate of V by computing these averages Take samples of outcomes s (by doing the action!) and compute the average: S. Joo (sungmoon.joo@cc.gatech.edu) 22 11
12 Temporal-Difference Learning Idea: learn from every experience! - Update V(s) each time we experience a transition (s, a, s, r) - Likely outcomes s will contribute updates more often Temporal difference learning of values - Policy still fixed, still doing evaluation! - Move values toward value of whatever successor occurs: running average S. Joo (sungmoon.joo@cc.gatech.edu) 23 Temporal-Difference Learning Idea: learn from every experience! Over time, updates will mimic Bellman s update! - Update V(s) each time we experience a transition (s, a, s, r) - Likely outcomes s will contribute updates more often Temporal difference learning of values - Policy still fixed, still doing evaluation! - Move values toward value of whatever successor occurs: running average S. Joo (sungmoon.joo@cc.gatech.edu) 24 12
 25 TD Learning Example http://www.cs.berkeley.edu/~pabbeel/ S. Joo (sungmoon.joo@cc.gatech.edu) 26 13")
13 Exponential Moving Average Exponential moving average Decreasing learning rate(α) can give converging averages S. Joo 25 TD Learning Example S. Joo 26 13

14 Interim Summary Model-based: - Learn the model empirically through experience - Solve for values as if the learned model were correct Model-free: - Direct evaluation: V(s) = sample estimate of sum of rewards accumulated from state s onwards - Temporal difference value learning Move values toward value of whatever successor occurs: running average! S. Joo (sungmoon.joo@cc.gatech.edu) 27 RL examples: Spider Walking S. Joo (sungmoon.joo@cc.gatech.edu) 28 14
15 Something Else than TD? TD value leaning is a model free way to do policy evaluation, mimicking Bellman updates with running sample averages Idea: learn Q values, not values Makes action selection model free too! S. Joo (sungmoon.joo@cc.gatech.edu) 29 Revisit Q-Learning Value iteration: - Start with V 0 (s) = 0 - Given V k, calculate V k+1 values for all states: Q iteration: - Start with Q 0 (s,a) = 0 - Given Q k, calculate Q k+1 values for all states and actions: S. Joo (sungmoon.joo@cc.gatech.edu) 30 15
 31 Q-Learning, and Beyond Q-learning converges to optimal policy!")
16 Revisit Q-Learning Since we don t know T and/or R, learn them(i.e. compute average) as we go Q S. Joo (sungmoon.joo@cc.gatech.edu) 31 Q-Learning, and Beyond Q-learning converges to optimal policy!! Caveats - You have to explore enough - You have to eventually make the learning rate small enough but not decrease it too quickly - Basically, in the limit, it doesn t matter how you select actions. - Basic Q-learning keeps a table of all Q-values :Infeasible Approximate Q-learning(feature-based) Policy Search - Problem: often the feature based policies that work well (win games, maximize utilities) aren t the ones that approximate V / Q best - Solution : learn policies that maximize rewards, not the values that predict them - Start with an ok solution (e.g. Q-learning) then fine-tune by local optimization (e.g. hill climbing) S. Joo (sungmoon.joo@cc.gatech.edu) 32 16
17 Summary Value/Policy Iteration the MDP Idea: Compute averages over T using sample outcomes *Online book: Sutton and Barto S. Joo (sungmoon.joo@cc.gatech.edu) 33 17
Lecture 10: Reinforcement Learning
 Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Lecture 1: Reinforcement Learning Cognitive Systems II - Machine Learning SS 25 Part III: Learning Programs and Strategies Q Learning, Dynamic Programming Lecture 1: Reinforcement Learning p. Motivation
Reinforcement Learning by Comparing Immediate Reward
 Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Reinforcement Learning by Comparing Immediate Reward Punit Pandey DeepshikhaPandey Dr. Shishir Kumar Abstract This paper introduces an approach to Reinforcement Learning Algorithm by comparing their immediate
Exploration. CS : Deep Reinforcement Learning Sergey Levine
 Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Exploration CS 294-112: Deep Reinforcement Learning Sergey Levine Class Notes 1. Homework 4 due on Wednesday 2. Project proposal feedback sent Today s Lecture 1. What is exploration? Why is it a problem?
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
TD(λ) and Q-Learning Based Ludo Players
 and Q-Learning Based Ludo Players") TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
TD(λ) and Q-Learning Based Ludo Players Majed Alhajry, Faisal Alvi, Member, IEEE and Moataz Ahmed Abstract Reinforcement learning is a popular machine learning technique whose inherent self-learning ability
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Speeding Up Reinforcement Learning with Behavior Transfer
 Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Speeding Up Reinforcement Learning with Behavior Transfer Matthew E. Taylor and Peter Stone Department of Computer Sciences The University of Texas at Austin Austin, Texas 78712-1188 {mtaylor, pstone}@cs.utexas.edu
Axiom 2013 Team Description Paper
 Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
Axiom 2013 Team Description Paper Mohammad Ghazanfari, S Omid Shirkhorshidi, Farbod Samsamipour, Hossein Rahmatizadeh Zagheli, Mohammad Mahdavi, Payam Mohajeri, S Abbas Alamolhoda Robotics Scientific Association
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering
 ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
ENME 605 Advanced Control Systems, Fall 2015 Department of Mechanical Engineering Lecture Details Instructor Course Objectives Tuesday and Thursday, 4:00 pm to 5:15 pm Information Technology and Engineering
Laboratorio di Intelligenza Artificiale e Robotica
 Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Laboratorio di Intelligenza Artificiale e Robotica A.A. 2008-2009 Outline 2 Machine Learning Unsupervised Learning Supervised Learning Reinforcement Learning Genetic Algorithms Genetics-Based Machine Learning
Georgetown University at TREC 2017 Dynamic Domain Track
 Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Georgetown University at TREC 2017 Dynamic Domain Track Zhiwen Tang Georgetown University zt79@georgetown.edu Grace Hui Yang Georgetown University huiyang@cs.georgetown.edu Abstract TREC Dynamic Domain
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for
 Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Learning Optimal Dialogue Strategies: A Case Study of a Spoken Dialogue Agent for Email Marilyn A. Walker Jeanne C. Fromer Shrikanth Narayanan walker@research.att.com jeannie@ai.mit.edu shri@research.att.com
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
High-level Reinforcement Learning in Strategy Games
 High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
High-level Reinforcement Learning in Strategy Games Christopher Amato Department of Computer Science University of Massachusetts Amherst, MA 01003 USA camato@cs.umass.edu Guy Shani Department of Computer
ISFA2008U_120 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM
 Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Proceedings of 28 ISFA 28 International Symposium on Flexible Automation Atlanta, GA, USA June 23-26, 28 ISFA28U_12 A SCHEDULING REINFORCEMENT LEARNING ALGORITHM Amit Gil, Helman Stern, Yael Edan, and
Improving Action Selection in MDP s via Knowledge Transfer
 In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
In Proc. 20th National Conference on Artificial Intelligence (AAAI-05), July 9 13, 2005, Pittsburgh, USA. Improving Action Selection in MDP s via Knowledge Transfer Alexander A. Sherstov and Peter Stone
On the Combined Behavior of Autonomous Resource Management Agents
 On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
On the Combined Behavior of Autonomous Resource Management Agents Siri Fagernes 1 and Alva L. Couch 2 1 Faculty of Engineering Oslo University College Oslo, Norway siri.fagernes@iu.hio.no 2 Computer Science
AMULTIAGENT system [1] can be defined as a group of
![AMULTIAGENT system [1] can be defined as a group of](/thumbs/71/65976880.jpg "AMULTIAGENT system [1] can be defined as a group of") 156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
156 IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS PART C: APPLICATIONS AND REVIEWS, VOL. 38, NO. 2, MARCH 2008 A Comprehensive Survey of Multiagent Reinforcement Learning Lucian Buşoniu, Robert Babuška,
Lecture 6: Applications
 Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
Lecture 6: Applications Michael L. Littman Rutgers University Department of Computer Science Rutgers Laboratory for Real-Life Reinforcement Learning What is RL? Branch of machine learning concerned with
2/15/13. POS Tagging Problem. Part-of-Speech Tagging. Example English Part-of-Speech Tagsets. More Details of the Problem. Typical Problem Cases
 POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
POS Tagging Problem Part-of-Speech Tagging L545 Spring 203 Given a sentence W Wn and a tagset of lexical categories, find the most likely tag T..Tn for each word in the sentence Example Secretariat/P is/vbz
A Reinforcement Learning Variant for Control Scheduling
 A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
A Reinforcement Learning Variant for Control Scheduling Aloke Guha Honeywell Sensor and System Development Center 3660 Technology Drive Minneapolis MN 55417 Abstract We present an algorithm based on reinforcement
An investigation of imitation learning algorithms for structured prediction
 JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
JMLR: Workshop and Conference Proceedings 24:143 153, 2012 10th European Workshop on Reinforcement Learning An investigation of imitation learning algorithms for structured prediction Andreas Vlachos Computer
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology
 ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
ReinForest: Multi-Domain Dialogue Management Using Hierarchical Policies and Knowledge Ontology Tiancheng Zhao CMU-LTI-16-006 Language Technologies Institute School of Computer Science Carnegie Mellon
Regret-based Reward Elicitation for Markov Decision Processes
 444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
444 REGAN & BOUTILIER UAI 2009 Regret-based Reward Elicitation for Markov Decision Processes Kevin Regan Department of Computer Science University of Toronto Toronto, ON, CANADA kmregan@cs.toronto.edu
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA
 Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Testing A Moving Target: How Do We Test Machine Learning Systems? Peter Varhol Technology Strategy Research, USA Testing a Moving Target How Do We Test Machine Learning Systems? Peter Varhol, Technology
Task Completion Transfer Learning for Reward Inference
 Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
Machine Learning for Interactive Systems: Papers from the AAAI-14 Workshop Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs,
FF+FPG: Guiding a Policy-Gradient Planner
 FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
FF+FPG: Guiding a Policy-Gradient Planner Olivier Buffet LAAS-CNRS University of Toulouse Toulouse, France firstname.lastname@laas.fr Douglas Aberdeen National ICT australia & The Australian National University
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots
 Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
Continual Curiosity-Driven Skill Acquisition from High-Dimensional Video Inputs for Humanoid Robots Varun Raj Kompella, Marijn Stollenga, Matthew Luciw, Juergen Schmidhuber The Swiss AI Lab IDSIA, USI
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Seminar - Organic Computing
 Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Seminar - Organic Computing Self-Organisation of OC-Systems Markus Franke 25.01.2006 Typeset by FoilTEX Timetable 1. Overview 2. Characteristics of SO-Systems 3. Concern with Nature 4. Design-Concepts
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Lecture 1: Basic Concepts of Machine Learning
 Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Lecture 1: Basic Concepts of Machine Learning Cognitive Systems - Machine Learning Ute Schmid (lecture) Johannes Rabold (practice) Based on slides prepared March 2005 by Maximilian Röglinger, updated 2010
Chinese Language Parsing with Maximum-Entropy-Inspired Parser
 Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Chinese Language Parsing with Maximum-Entropy-Inspired Parser Heng Lian Brown University Abstract The Chinese language has many special characteristics that make parsing difficult. The performance of state-of-the-art
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
ALL-IN-ONE MEETING GUIDE THE ECONOMICS OF WELL-BEING
 ALL-IN-ONE MEETING GUIDE THE ECONOMICS OF WELL-BEING LeanIn.0rg, 2016 1 Overview Do we limit our thinking and focus only on short-term goals when we make trade-offs between career and family? This final
ALL-IN-ONE MEETING GUIDE THE ECONOMICS OF WELL-BEING LeanIn.0rg, 2016 1 Overview Do we limit our thinking and focus only on short-term goals when we make trade-offs between career and family? This final
MGT/MGP/MGB 261: Investment Analysis
 UNIVERSITY OF CALIFORNIA, DAVIS GRADUATE SCHOOL OF MANAGEMENT SYLLABUS for Fall 2014 MGT/MGP/MGB 261: Investment Analysis Daytime MBA: Tu 12:00p.m. - 3:00 p.m. Location: 1302 Gallagher (CRN: 51489) Sacramento
UNIVERSITY OF CALIFORNIA, DAVIS GRADUATE SCHOOL OF MANAGEMENT SYLLABUS for Fall 2014 MGT/MGP/MGB 261: Investment Analysis Daytime MBA: Tu 12:00p.m. - 3:00 p.m. Location: 1302 Gallagher (CRN: 51489) Sacramento
Cross Language Information Retrieval
 Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Cross Language Information Retrieval RAFFAELLA BERNARDI UNIVERSITÀ DEGLI STUDI DI TRENTO P.ZZA VENEZIA, ROOM: 2.05, E-MAIL: BERNARDI@DISI.UNITN.IT Contents 1 Acknowledgment.............................................
Learning Prospective Robot Behavior
 Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Learning Prospective Robot Behavior Shichao Ou and Rod Grupen Laboratory for Perceptual Robotics Computer Science Department University of Massachusetts Amherst {chao,grupen}@cs.umass.edu Abstract This
Outline for Session III
 Outline for Session III Before you begin be sure to have the following materials Extra JM cards Extra blank break-down sheets Extra proposal sheets Proposal reports Attendance record Be at the meeting
Outline for Session III Before you begin be sure to have the following materials Extra JM cards Extra blank break-down sheets Extra proposal sheets Proposal reports Attendance record Be at the meeting
An OO Framework for building Intelligence and Learning properties in Software Agents
 An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
An OO Framework for building Intelligence and Learning properties in Software Agents José A. R. P. Sardinha, Ruy L. Milidiú, Carlos J. P. Lucena, Patrick Paranhos Abstract Software agents are defined as
Learning Methods for Fuzzy Systems
 Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
Learning Methods for Fuzzy Systems Rudolf Kruse and Andreas Nürnberger Department of Computer Science, University of Magdeburg Universitätsplatz, D-396 Magdeburg, Germany Phone : +49.39.67.876, Fax : +49.39.67.8
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks
 System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
System Implementation for SemEval-2017 Task 4 Subtask A Based on Interpolated Deep Neural Networks 1 Tzu-Hsuan Yang, 2 Tzu-Hsuan Tseng, and 3 Chia-Ping Chen Department of Computer Science and Engineering
Shockwheat. Statistics 1, Activity 1
 Statistics 1, Activity 1 Shockwheat Students require real experiences with situations involving data and with situations involving chance. They will best learn about these concepts on an intuitive or informal
Statistics 1, Activity 1 Shockwheat Students require real experiences with situations involving data and with situations involving chance. They will best learn about these concepts on an intuitive or informal
Running Head: STUDENT CENTRIC INTEGRATED TECHNOLOGY
 SCIT Model 1 Running Head: STUDENT CENTRIC INTEGRATED TECHNOLOGY Instructional Design Based on Student Centric Integrated Technology Model Robert Newbury, MS December, 2008 SCIT Model 2 Abstract The ADDIE
SCIT Model 1 Running Head: STUDENT CENTRIC INTEGRATED TECHNOLOGY Instructional Design Based on Student Centric Integrated Technology Model Robert Newbury, MS December, 2008 SCIT Model 2 Abstract The ADDIE
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses
 Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Designing a Rubric to Assess the Modelling Phase of Student Design Projects in Upper Year Engineering Courses Thomas F.C. Woodhall Masters Candidate in Civil Engineering Queen s University at Kingston,
Task Completion Transfer Learning for Reward Inference
 Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
Task Completion Transfer Learning for Reward Inference Layla El Asri 1,2, Romain Laroche 1, Olivier Pietquin 3 1 Orange Labs, Issy-les-Moulineaux, France 2 UMI 2958 (CNRS - GeorgiaTech), France 3 University
TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION. by Yang Xu PhD of Information Sciences
 TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION by Yang Xu PhD of Information Sciences Submitted to the Graduate Faculty of in partial fulfillment of the requirements for the degree of Doctor of Philosophy
TOKEN-BASED APPROACH FOR SCALABLE TEAM COORDINATION by Yang Xu PhD of Information Sciences Submitted to the Graduate Faculty of in partial fulfillment of the requirements for the degree of Doctor of Philosophy
IAT 888: Metacreation Machines endowed with creative behavior. Philippe Pasquier Office 565 (floor 14)
") IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
IAT 888: Metacreation Machines endowed with creative behavior Philippe Pasquier Office 565 (floor 14) pasquier@sfu.ca Outline of today's lecture A little bit about me A little bit about you What will that
Robot Learning Simultaneously a Task and How to Interpret Human Instructions
 Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Robot Learning Simultaneously a Task and How to Interpret Human Instructions Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer To cite this version: Jonathan Grizou, Manuel Lopes, Pierre-Yves Oudeyer.
Acquiring Competence from Performance Data
 Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
Acquiring Competence from Performance Data Online learnability of OT and HG with simulated annealing Tamás Biró ACLC, University of Amsterdam (UvA) Computational Linguistics in the Netherlands, February
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
MODULE 4 Data Collection and Hypothesis Development. Trainer Outline
 MODULE 4 Data Collection and Hypothesis Development Trainer Outline The following trainer guide includes estimated times for each section of the module, an overview of the information to be presented,
MODULE 4 Data Collection and Hypothesis Development Trainer Outline The following trainer guide includes estimated times for each section of the module, an overview of the information to be presented,
An Introduction to Simio for Beginners
 An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
An Introduction to Simio for Beginners C. Dennis Pegden, Ph.D. This white paper is intended to introduce Simio to a user new to simulation. It is intended for the manufacturing engineer, hospital quality
Learning and Transferring Relational Instance-Based Policies
 Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning and Transferring Relational Instance-Based Policies Rocío García-Durán, Fernando Fernández y Daniel Borrajo Universidad Carlos III de Madrid Avda de la Universidad 30, 28911-Leganés (Madrid),
Learning to Schedule Straight-Line Code
 Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
Learning to Schedule Straight-Line Code Eliot Moss, Paul Utgoff, John Cavazos Doina Precup, Darko Stefanović Dept. of Comp. Sci., Univ. of Mass. Amherst, MA 01003 Carla Brodley, David Scheeff Sch. of Elec.
8. UTILIZATION OF SCHOOL FACILITIES
 8. UTILIZATION OF SCHOOL FACILITIES Page 105 Page 106 8. UTILIZATION OF SCHOOL FACILITIES OVERVIEW The capacity of a school facility is driven by the number of classrooms or other spaces in which children
8. UTILIZATION OF SCHOOL FACILITIES Page 105 Page 106 8. UTILIZATION OF SCHOOL FACILITIES OVERVIEW The capacity of a school facility is driven by the number of classrooms or other spaces in which children
Foothill College Summer 2016
 Foothill College Summer 2016 Intermediate Algebra Math 105.04W CRN# 10135 5.0 units Instructor: Yvette Butterworth Text: None; Beoga.net material used Hours: Online Except Final Thurs, 8/4 3:30pm Phone:
Foothill College Summer 2016 Intermediate Algebra Math 105.04W CRN# 10135 5.0 units Instructor: Yvette Butterworth Text: None; Beoga.net material used Hours: Online Except Final Thurs, 8/4 3:30pm Phone:
CS 100: Principles of Computing
 CS 100: Principles of Computing Kevin Molloy August 29, 2017 1 Basic Course Information 1.1 Prerequisites: None 1.2 General Education Fulfills Mason Core requirement in Information Technology (ALL). 1.3
CS 100: Principles of Computing Kevin Molloy August 29, 2017 1 Basic Course Information 1.1 Prerequisites: None 1.2 General Education Fulfills Mason Core requirement in Information Technology (ALL). 1.3
Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration
 INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
INTERSPEECH 2013 Semi-Supervised GMM and DNN Acoustic Model Training with Multi-system Combination and Confidence Re-calibration Yan Huang, Dong Yu, Yifan Gong, and Chaojun Liu Microsoft Corporation, One
CS177 Python Programming
 CS177 Python Programming Recitation 1 Introduction Adapted from John Zelle s Book Slides 1 Course Instructors Dr. Elisha Sacks E-mail: eps@purdue.edu Ruby Tahboub (Course Coordinator) E-mail: rtahboub@purdue.edu
CS177 Python Programming Recitation 1 Introduction Adapted from John Zelle s Book Slides 1 Course Instructors Dr. Elisha Sacks E-mail: eps@purdue.edu Ruby Tahboub (Course Coordinator) E-mail: rtahboub@purdue.edu
Challenges in Deep Reinforcement Learning. Sergey Levine UC Berkeley
 Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
Challenges in Deep Reinforcement Learning Sergey Levine UC Berkeley Discuss some recent work in deep reinforcement learning Present a few major challenges Show some of our recent work toward tackling
A process by any other name
 January 05, 2016 Roger Tregear A process by any other name thoughts on the conflicted use of process language What s in a name? That which we call a rose By any other name would smell as sweet. William
January 05, 2016 Roger Tregear A process by any other name thoughts on the conflicted use of process language What s in a name? That which we call a rose By any other name would smell as sweet. William
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Dublin City Schools Mathematics Graded Course of Study GRADE 4
 I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
I. Content Standard: Number, Number Sense and Operations Standard Students demonstrate number sense, including an understanding of number systems and reasonable estimates using paper and pencil, technology-supported
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
ADDIE: A systematic methodology for instructional design that includes five phases: Analysis, Design, Development, Implementation, and Evaluation.
 ADDIE: A systematic methodology for instructional design that includes five phases: Analysis, Design, Development, Implementation, and Evaluation. I first was exposed to the ADDIE model in April 1983 at
ADDIE: A systematic methodology for instructional design that includes five phases: Analysis, Design, Development, Implementation, and Evaluation. I first was exposed to the ADDIE model in April 1983 at
Course Syllabus. Course Information Course Number/Section OB 6301-MBP
 Course Syllabus Course Information Course Number/Section OB 6301-MBP Course Title Organizational Behavior Term Fall 2016 Days & Times Mondays, 7:00-9:45 Location JSOM 2.117 Professor Contact Information
Course Syllabus Course Information Course Number/Section OB 6301-MBP Course Title Organizational Behavior Term Fall 2016 Days & Times Mondays, 7:00-9:45 Location JSOM 2.117 Professor Contact Information
Professor Christina Romer. LECTURE 24 INFLATION AND THE RETURN OF OUTPUT TO POTENTIAL April 20, 2017
 Economics 2 Spring 2017 Professor Christina Romer Professor David Romer LECTURE 24 INFLATION AND THE RETURN OF OUTPUT TO POTENTIAL April 20, 2017 I. OVERVIEW II. HOW OUTPUT RETURNS TO POTENTIAL A. Moving
Economics 2 Spring 2017 Professor Christina Romer Professor David Romer LECTURE 24 INFLATION AND THE RETURN OF OUTPUT TO POTENTIAL April 20, 2017 I. OVERVIEW II. HOW OUTPUT RETURNS TO POTENTIAL A. Moving
Process improvement, The Agile Way! By Ben Linders Published in Methods and Tools, winter
 Process improvement, The Agile Way! By Ben Linders Published in Methods and Tools, winter 2010. http://www.methodsandtools.com/ Summary Business needs for process improvement projects are changing. Organizations
Process improvement, The Agile Way! By Ben Linders Published in Methods and Tools, winter 2010. http://www.methodsandtools.com/ Summary Business needs for process improvement projects are changing. Organizations
Hentai High School A Game Guide
 Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Hentai High School A Game Guide Hentai High School is a sex game where you are the Principal of a high school with the goal of turning the students into sex crazed people within 15 years. The game is difficult
Visual CP Representation of Knowledge
 Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Visual CP Representation of Knowledge Heather D. Pfeiffer and Roger T. Hartley Department of Computer Science New Mexico State University Las Cruces, NM 88003-8001, USA email: hdp@cs.nmsu.edu and rth@cs.nmsu.edu
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD
 TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
TABLE OF CONTENTS TABLE OF CONTENTS COVER PAGE HALAMAN PENGESAHAN PERNYATAAN NASKAH SOAL TUGAS AKHIR ACKNOWLEDGEMENT FOREWORD TABLE OF CONTENTS LIST OF FIGURES LIST OF TABLES LIST OF APPENDICES LIST OF
What to Do When Conflict Happens
 PREVIEW GUIDE What to Do When Conflict Happens Table of Contents: Sample Pages from Leader s Guide and Workbook..pgs. 2-15 Program Information and Pricing.. pgs. 16-17 BACKGROUND INTRODUCTION Workplace
PREVIEW GUIDE What to Do When Conflict Happens Table of Contents: Sample Pages from Leader s Guide and Workbook..pgs. 2-15 Program Information and Pricing.. pgs. 16-17 BACKGROUND INTRODUCTION Workplace
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, / X
 The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
The 9 th International Scientific Conference elearning and software for Education Bucharest, April 25-26, 2013 10.12753/2066-026X-13-154 DATA MINING SOLUTIONS FOR DETERMINING STUDENT'S PROFILE Adela BÂRA,
Major Milestones, Team Activities, and Individual Deliverables
 Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Major Milestones, Team Activities, and Individual Deliverables Milestone #1: Team Semester Proposal Your team should write a proposal that describes project objectives, existing relevant technology, engineering
Discriminative Learning of Beam-Search Heuristics for Planning
 Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
Discriminative Learning of Beam-Search Heuristics for Planning Yuehua Xu School of EECS Oregon State University Corvallis,OR 97331 xuyu@eecs.oregonstate.edu Alan Fern School of EECS Oregon State University
The Good Judgment Project: A large scale test of different methods of combining expert predictions
 The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
The Good Judgment Project: A large scale test of different methods of combining expert predictions Lyle Ungar, Barb Mellors, Jon Baron, Phil Tetlock, Jaime Ramos, Sam Swift The University of Pennsylvania
Book Review: Build Lean: Transforming construction using Lean Thinking by Adrian Terry & Stuart Smith
 Howell, Greg (2011) Book Review: Build Lean: Transforming construction using Lean Thinking by Adrian Terry & Stuart Smith. Lean Construction Journal 2011 pp 3-8 Book Review: Build Lean: Transforming construction
Howell, Greg (2011) Book Review: Build Lean: Transforming construction using Lean Thinking by Adrian Terry & Stuart Smith. Lean Construction Journal 2011 pp 3-8 Book Review: Build Lean: Transforming construction
Natural Language Processing. George Konidaris
 Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
Natural Language Processing George Konidaris gdk@cs.brown.edu Fall 2017 Natural Language Processing Understanding spoken/written sentences in a natural language. Major area of research in AI. Why? Humans
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
The Evolution of Random Phenomena
 The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
The Evolution of Random Phenomena A Look at Markov Chains Glen Wang glenw@uchicago.edu Splash! Chicago: Winter Cascade 2012 Lecture 1: What is Randomness? What is randomness? Can you think of some examples
Planning with External Events
 94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
94 Planning with External Events Jim Blythe School of Computer Science Carnegie Mellon University Pittsburgh, PA 15213 blythe@cs.cmu.edu Abstract I describe a planning methodology for domains with uncertainty
Using AMT & SNOMED CT-AU to support clinical research
 Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
Using AMT & SNOMED CT-AU to support clinical research Simon J. McBRIDE, Michael J. LAWLEY, Hugo LEROUX and Simon GIBSON CSIRO Australian E-Health Research Centre 2 August 2012 PREVENTATIVE HEALTH FLAGSHIP
BSP !!! Trainer s Manual. Sheldon Loman, Ph.D. Portland State University. M. Kathleen Strickland-Cohen, Ph.D. University of Oregon
 Basic FBA to BSP Trainer s Manual Sheldon Loman, Ph.D. Portland State University M. Kathleen Strickland-Cohen, Ph.D. University of Oregon Chris Borgmeier, Ph.D. Portland State University Robert Horner,
Basic FBA to BSP Trainer s Manual Sheldon Loman, Ph.D. Portland State University M. Kathleen Strickland-Cohen, Ph.D. University of Oregon Chris Borgmeier, Ph.D. Portland State University Robert Horner,
Julia Smith. Effective Classroom Approaches to.
 Julia Smith @tessmaths Effective Classroom Approaches to GCSE Maths resits julia.smith@writtle.ac.uk Agenda The context of GCSE resit in a post-16 setting An overview of the new GCSE Key features of a
Julia Smith @tessmaths Effective Classroom Approaches to GCSE Maths resits julia.smith@writtle.ac.uk Agenda The context of GCSE resit in a post-16 setting An overview of the new GCSE Key features of a
ACTL5103 Stochastic Modelling For Actuaries. Course Outline Semester 2, 2014
 UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
UNSW Australia Business School School of Risk and Actuarial Studies ACTL5103 Stochastic Modelling For Actuaries Course Outline Semester 2, 2014 Part A: Course-Specific Information Please consult Part B
BADM 641 (sec. 7D1) (on-line) Decision Analysis August 16 October 6, 2017 CRN: 83777
 (on-line) Decision Analysis August 16 October 6, 2017 CRN: 83777") BADM 641 (sec. 7D1) (on-line) Decision Analysis August 16 October 6, 2017 CRN: 83777 SEMESTER: Fall 2017 INSTRUCTOR: Jack Fuller, Ph.D. OFFICE: 108 Business and Economics Building, West Virginia University,
BADM 641 (sec. 7D1) (on-line) Decision Analysis August 16 October 6, 2017 CRN: 83777 SEMESTER: Fall 2017 INSTRUCTOR: Jack Fuller, Ph.D. OFFICE: 108 Business and Economics Building, West Virginia University,
Firms and Markets Saturdays Summer I 2014
 PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
PRELIMINARY DRAFT VERSION. SUBJECT TO CHANGE. Firms and Markets Saturdays Summer I 2014 Professor Thomas Pugel Office: Room 11-53 KMC E-mail: tpugel@stern.nyu.edu Tel: 212-998-0918 Fax: 212-995-4212 This
HUBBARD COMMUNICATIONS OFFICE Saint Hill Manor, East Grinstead, Sussex. HCO BULLETIN OF 11 AUGUST 1978 Issue I RUDIMENTS DEFINITIONS AND PATTER
 HUBBARD COMMUNICATIONS OFFICE Saint Hill Manor, East Grinstead, Sussex Remimeo All Auditors HCO BULLETIN OF 11 AUGUST 1978 Issue I RUDIMENTS DEFINITIONS AND PATTER (Ref: HCOB 15 Aug 69, FLYING RUDS) (NOTE:
HUBBARD COMMUNICATIONS OFFICE Saint Hill Manor, East Grinstead, Sussex Remimeo All Auditors HCO BULLETIN OF 11 AUGUST 1978 Issue I RUDIMENTS DEFINITIONS AND PATTER (Ref: HCOB 15 Aug 69, FLYING RUDS) (NOTE:
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling
 Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Adaptive Generation in Dialogue Systems Using Dynamic User Modeling Srinivasan Janarthanam Heriot-Watt University Oliver Lemon Heriot-Watt University We address the problem of dynamically modeling and
Using focal point learning to improve human machine tacit coordination
 DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
DOI 10.1007/s10458-010-9126-5 Using focal point learning to improve human machine tacit coordination InonZuckerman SaritKraus Jeffrey S. Rosenschein The Author(s) 2010 Abstract We consider an automated
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
IMGD Technical Game Development I: Iterative Development Techniques. by Robert W. Lindeman
 IMGD 3000 - Technical Game Development I: Iterative Development Techniques by Robert W. Lindeman gogo@wpi.edu Motivation The last thing you want to do is write critical code near the end of a project Induces
IMGD 3000 - Technical Game Development I: Iterative Development Techniques by Robert W. Lindeman gogo@wpi.edu Motivation The last thing you want to do is write critical code near the end of a project Induces
2017 FALL PROFESSIONAL TRAINING CALENDAR
 2017 FALL PROFESSIONAL TRAINING CALENDAR Date Title Price Instructor Sept 20, 1:30 4:30pm Feedback to boost employee performance 50 Euros Sept 26, 1:30 4:30pm Dealing with Customer Objections 50 Euros
2017 FALL PROFESSIONAL TRAINING CALENDAR Date Title Price Instructor Sept 20, 1:30 4:30pm Feedback to boost employee performance 50 Euros Sept 26, 1:30 4:30pm Dealing with Customer Objections 50 Euros