BENCHMARKING MACHINE LEARNING TECHNIQUES FOR SOFTWARE DEFECT DETECTION. Presented By: Sheenam Sharma Masters of Computer Science
|
|
|
- Jeremy Walton
- 5 years ago
- Views:
Transcription


1 BENCHMARKING MACHINE LEARNING TECHNIQUES FOR SOFTWARE DEFECT DETECTION Presented By: Sheenam Sharma Masters of Computer Science

2 Introduction Related Work Dataset Supervised techniques for machine learning Classification Various classification algorithms Unsupervised techniques for machine learning Clustering Performance indicators Results Conclusion Discussion

3 INTRODUCTION Software maintenance is the most challenging task. Good to fix a bug before the deliverable. Machine learning can help in analyzing the data and retrieval of useful information which can help developers in detecting defects. Machine learning techniques used for bug detection: Classification Clustering

4 RELATED WORK Classification algorithms have been benchmarked using AUC curves. AUC was selected as the authors believed that it is the most informative source for benchmarking. Some authors focused only on the decision tree classification algorithms present in Weka.
5 Data set The datasets from PROMISE data repository were used in the experiments. The datasets were collected from real software projects by NASA and have many software modules. Public domain datasets in the experiments were used as the research was a benchmarking procedure of defect prediction. Weka tool was used for performing experiments.
6 Classification Classification is a data mining and machine learning approach. In software bug prediction it involves categorization of software modules into defective or non-defective that is denoted by a set of software complexity metrics by utilizing a classification model.
7 Classification Algorithms Decision Tree Bagging Random Forest Boosting SMO or SVM ZeroR
8 Decision tree DT builds a tree-like structure by recursively partitioning the input attribute space into a set of non-overlapping spaces. A DT can also be seen as a set of decision rules from the root to the leaves. It is often used due to its natural interpretation. A DT takes one attribute, and divides the instances forming a tree.
9 Bagging Bagging uses multiple weak learners to form a strong learner that has better predictive performance than individual weak learners. A huge data set is divided into small chunks and base classifier is selected which operates separately but concurrently on these chunks. In the last, results from these classifiers are voted so as to get the best outcome. Random Forest is an example of Bagging.
10 Boosting Just like Bagging, Boosting also uses multiple weak learners to form a strong learner that has better predictive performance than individual weak learners. Unlike Bagging, it divides the problem into small chunks and one chunk is selected on which base classifier operates. From the results, instances which were wrongly classified are selected and classifier is again trained on it so as to increase the accuracy.
11 Suppose we have a set of training examples {x1, x2,., xn}, where xi Rd along with their class labels {y1, y2,., yn} and yi {-1, 1}. The task of SVM is to find a hyper plane to separate the data with the maximum margin between the hyper plane and the nearest data points of each class. SVM
12 ZEROR This classification algorithm is used mostly as a baseline algorithm for experiments. The results of these classifier are based on majority. Suppose class A has 51 instances and class B has 48 instances, this classifier will classify all the instances in class A.

13 CLASSIFICATION Algorithms in weka

14 Clustering Clustering is method that moves data points among a set of clusters until similar item clusters are formed or a desired set is acquired. Clustering methods make assumptions about the data set. If that assumption holds, then it results into a good cluster.

15 Clustering Algorithms in weka
 TP / (TP + FN) F-measure= (2 * precision * recall) / (Precision + recall) Mean Absolute Error")
16 PERFORMANCE INDICATORS Accuracy = (correctly classified software bugs/ Total software bugs) * 100 Precision= Recall= TP / (TP+FP) TP / (TP + FN) F-measure= (2 * precision * recall) / (Precision + recall) Mean Absolute Error (MAE)
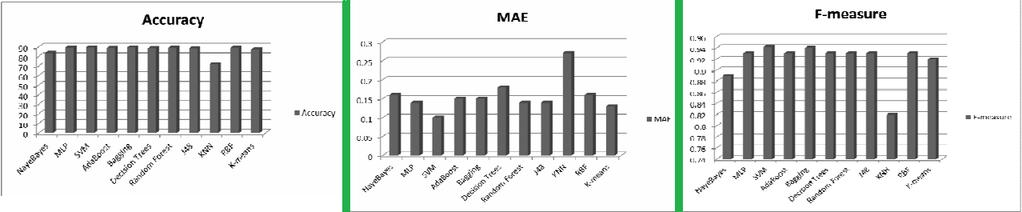

17 Experimental results
18 Conclusion From the experiments it was concluded that SVM and Bagging had maximum accuracy and f-measure. Moreover, MAE for both these algorithms was low. Hence, the authors concluded that these two techniques performed well on the bug s dataset.
19 references Luiz Fernando Capretz and Faheem Ahmed Saiqa Aleem, "BENCHMARKING MACHINE LEARNING TECHNIQUES FOR SOFTWARE DEFECT DETECTION," International Journal of Software Engineering & Applications (IJSEA), vol. 6, no. 3, pp , May J.Van Ryzin, Classification and Clustering. New York: Harcourt Brace Jovanovich. Sahil Saroop, "Exploring Mediatoil Imagery: A Content-Based Approach," University of Ottawa, Ottawa, Thesis David M. W POWERS, "EVALUATION: FROM PRECISION, RECALL AND F-MEASURE TO ROC, INFORMEDNESS, MARKEDNESS & CORRELATION," Journal of Machine Learning Technologies, vol. 2, no. 1, pp , Feb

20 Discussion In which other fields of software engineering can you think where machine learning techniques can be applied? Can you think of areas other than software engineering where you can use machine learning? Can the results concluded by the author be generalized on all the dataset s related to bugs?

21
Learning From the Past with Experiment Databases
 Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Learning From the Past with Experiment Databases Joaquin Vanschoren 1, Bernhard Pfahringer 2, and Geoff Holmes 2 1 Computer Science Dept., K.U.Leuven, Leuven, Belgium 2 Computer Science Dept., University
Python Machine Learning
 Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Python Machine Learning Unlock deeper insights into machine learning with this vital guide to cuttingedge predictive analytics Sebastian Raschka [ PUBLISHING 1 open source I community experience distilled
Reducing Features to Improve Bug Prediction
 Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Reducing Features to Improve Bug Prediction Shivkumar Shivaji, E. James Whitehead, Jr., Ram Akella University of California Santa Cruz {shiv,ejw,ram}@soe.ucsc.edu Sunghun Kim Hong Kong University of Science
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition
 Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Introduction to Ensemble Learning Featuring Successes in the Netflix Prize Competition Todd Holloway Two Lecture Series for B551 November 20 & 27, 2007 Indiana University Outline Introduction Bias and
Twitter Sentiment Classification on Sanders Data using Hybrid Approach
 IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
IOSR Journal of Computer Engineering (IOSR-JCE) e-issn: 2278-0661,p-ISSN: 2278-8727, Volume 17, Issue 4, Ver. I (July Aug. 2015), PP 118-123 www.iosrjournals.org Twitter Sentiment Classification on Sanders
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks
 Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
Predicting Student Attrition in MOOCs using Sentiment Analysis and Neural Networks Devendra Singh Chaplot, Eunhee Rhim, and Jihie Kim Samsung Electronics Co., Ltd. Seoul, South Korea {dev.chaplot,eunhee.rhim,jihie.kim}@samsung.com
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
CS Machine Learning
 CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
CS 478 - Machine Learning Projects Data Representation Basic testing and evaluation schemes CS 478 Data and Testing 1 Programming Issues l Program in any platform you want l Realize that you will be doing
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees
 Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Impact of Cluster Validity Measures on Performance of Hybrid Models Based on K-means and Decision Trees Mariusz Łapczy ski 1 and Bartłomiej Jefma ski 2 1 The Chair of Market Analysis and Marketing Research,
Issues in the Mining of Heart Failure Datasets
 International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
International Journal of Automation and Computing 11(2), April 2014, 162-179 DOI: 10.1007/s11633-014-0778-5 Issues in the Mining of Heart Failure Datasets Nongnuch Poolsawad 1 Lisa Moore 1 Chandrasekhar
Rule Learning With Negation: Issues Regarding Effectiveness
 Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Rule Learning With Negation: Issues Regarding Effectiveness S. Chua, F. Coenen, G. Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX Liverpool, United
Module 12. Machine Learning. Version 2 CSE IIT, Kharagpur
 Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Module 12 Machine Learning 12.1 Instructional Objective The students should understand the concept of learning systems Students should learn about different aspects of a learning system Students should
Word Segmentation of Off-line Handwritten Documents
 Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Word Segmentation of Off-line Handwritten Documents Chen Huang and Sargur N. Srihari {chuang5, srihari}@cedar.buffalo.edu Center of Excellence for Document Analysis and Recognition (CEDAR), Department
Human Emotion Recognition From Speech
 RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
RESEARCH ARTICLE OPEN ACCESS Human Emotion Recognition From Speech Miss. Aparna P. Wanare*, Prof. Shankar N. Dandare *(Department of Electronics & Telecommunication Engineering, Sant Gadge Baba Amravati
Machine Learning and Data Mining. Ensembles of Learners. Prof. Alexander Ihler
 Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Machine Learning and Data Mining Ensembles of Learners Prof. Alexander Ihler Ensemble methods Why learn one classifier when you can learn many? Ensemble: combine many predictors (Weighted) combina
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
A Case Study: News Classification Based on Term Frequency
 A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
A Case Study: News Classification Based on Term Frequency Petr Kroha Faculty of Computer Science University of Technology 09107 Chemnitz Germany kroha@informatik.tu-chemnitz.de Ricardo Baeza-Yates Center
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
Rule Learning with Negation: Issues Regarding Effectiveness
 Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
Rule Learning with Negation: Issues Regarding Effectiveness Stephanie Chua, Frans Coenen, and Grant Malcolm University of Liverpool Department of Computer Science, Ashton Building, Ashton Street, L69 3BX
ScienceDirect. A Framework for Clustering Cardiac Patient s Records Using Unsupervised Learning Techniques
 Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Available online at www.sciencedirect.com ScienceDirect Procedia Computer Science 98 (2016 ) 368 373 The 6th International Conference on Current and Future Trends of Information and Communication Technologies
Detecting English-French Cognates Using Orthographic Edit Distance
 Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Detecting English-French Cognates Using Orthographic Edit Distance Qiongkai Xu 1,2, Albert Chen 1, Chang i 1 1 The Australian National University, College of Engineering and Computer Science 2 National
Probabilistic Latent Semantic Analysis
 Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Probabilistic Latent Semantic Analysis Thomas Hofmann Presentation by Ioannis Pavlopoulos & Andreas Damianou for the course of Data Mining & Exploration 1 Outline Latent Semantic Analysis o Need o Overview
Australian Journal of Basic and Applied Sciences
 AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
AENSI Journals Australian Journal of Basic and Applied Sciences ISSN:1991-8178 Journal home page: www.ajbasweb.com Feature Selection Technique Using Principal Component Analysis For Improving Fuzzy C-Mean
Comparison of EM and Two-Step Cluster Method for Mixed Data: An Application
 International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
International Journal of Medical Science and Clinical Inventions 4(3): 2768-2773, 2017 DOI:10.18535/ijmsci/ v4i3.8 ICV 2015: 52.82 e-issn: 2348-991X, p-issn: 2454-9576 2017, IJMSCI Research Article Comparison
Learning Methods in Multilingual Speech Recognition
 Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Learning Methods in Multilingual Speech Recognition Hui Lin Department of Electrical Engineering University of Washington Seattle, WA 98125 linhui@u.washington.edu Li Deng, Jasha Droppo, Dong Yu, and Alex
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011
 Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
Detecting Wikipedia Vandalism using Machine Learning Notebook for PAN at CLEF 2011 Cristian-Alexandru Drăgușanu, Marina Cufliuc, Adrian Iftene UAIC: Faculty of Computer Science, Alexandru Ioan Cuza University,
*Net Perceptions, Inc West 78th Street Suite 300 Minneapolis, MN
 From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
From: AAAI Technical Report WS-98-08. Compilation copyright 1998, AAAI (www.aaai.org). All rights reserved. Recommender Systems: A GroupLens Perspective Joseph A. Konstan *t, John Riedl *t, AI Borchers,
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning
 Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Experiment Databases: Towards an Improved Experimental Methodology in Machine Learning Hendrik Blockeel and Joaquin Vanschoren Computer Science Dept., K.U.Leuven, Celestijnenlaan 200A, 3001 Leuven, Belgium
Cross-lingual Short-Text Document Classification for Facebook Comments
 2014 International Conference on Future Internet of Things and Cloud Cross-lingual Short-Text Document Classification for Facebook Comments Mosab Faqeeh, Nawaf Abdulla, Mahmoud Al-Ayyoub, Yaser Jararweh
2014 International Conference on Future Internet of Things and Cloud Cross-lingual Short-Text Document Classification for Facebook Comments Mosab Faqeeh, Nawaf Abdulla, Mahmoud Al-Ayyoub, Yaser Jararweh
Mining Association Rules in Student s Assessment Data
 www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
www.ijcsi.org 211 Mining Association Rules in Student s Assessment Data Dr. Varun Kumar 1, Anupama Chadha 2 1 Department of Computer Science and Engineering, MVN University Palwal, Haryana, India 2 Anupama
Algebra 1, Quarter 3, Unit 3.1. Line of Best Fit. Overview
 Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Algebra 1, Quarter 3, Unit 3.1 Line of Best Fit Overview Number of instructional days 6 (1 day assessment) (1 day = 45 minutes) Content to be learned Analyze scatter plots and construct the line of best
Generative models and adversarial training
 Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Day 4 Lecture 1 Generative models and adversarial training Kevin McGuinness kevin.mcguinness@dcu.ie Research Fellow Insight Centre for Data Analytics Dublin City University What is a generative model?
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages
 Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Iterative Cross-Training: An Algorithm for Learning from Unlabeled Web Pages Nuanwan Soonthornphisaj 1 and Boonserm Kijsirikul 2 Machine Intelligence and Knowledge Discovery Laboratory Department of Computer
Disambiguation of Thai Personal Name from Online News Articles
 Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
Disambiguation of Thai Personal Name from Online News Articles Phaisarn Sutheebanjard Graduate School of Information Technology Siam University Bangkok, Thailand mr.phaisarn@gmail.com Abstract Since online
AUTOMATED FABRIC DEFECT INSPECTION: A SURVEY OF CLASSIFIERS
 AUTOMATED FABRIC DEFECT INSPECTION: A SURVEY OF CLASSIFIERS Md. Tarek Habib 1, Rahat Hossain Faisal 2, M. Rokonuzzaman 3, Farruk Ahmed 4 1 Department of Computer Science and Engineering, Prime University,
AUTOMATED FABRIC DEFECT INSPECTION: A SURVEY OF CLASSIFIERS Md. Tarek Habib 1, Rahat Hossain Faisal 2, M. Rokonuzzaman 3, Farruk Ahmed 4 1 Department of Computer Science and Engineering, Prime University,
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations
 Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
Evaluating and Comparing Classifiers: Review, Some Recommendations and Limitations Katarzyna Stapor (B) Institute of Computer Science, Silesian Technical University, Gliwice, Poland katarzyna.stapor@polsl.pl
(Sub)Gradient Descent
Gradient Descent") (Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
(Sub)Gradient Descent CMSC 422 MARINE CARPUAT marine@cs.umd.edu Figures credit: Piyush Rai Logistics Midterm is on Thursday 3/24 during class time closed book/internet/etc, one page of notes. will include
Linking the Ohio State Assessments to NWEA MAP Growth Tests *
 Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Linking the Ohio State Assessments to NWEA MAP Growth Tests * *As of June 2017 Measures of Academic Progress (MAP ) is known as MAP Growth. August 2016 Introduction Northwest Evaluation Association (NWEA
Assignment 1: Predicting Amazon Review Ratings
 Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Assignment 1: Predicting Amazon Review Ratings 1 Dataset Analysis Richard Park r2park@acsmail.ucsd.edu February 23, 2015 The dataset selected for this assignment comes from the set of Amazon reviews for
Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio
 SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
SCSUG Student Symposium 2016 Analyzing sentiments in tweets for Tesla Model 3 using SAS Enterprise Miner and SAS Sentiment Analysis Studio Praneth Guggilla, Tejaswi Jha, Goutam Chakraborty, Oklahoma State
The stages of event extraction
 The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
The stages of event extraction David Ahn Intelligent Systems Lab Amsterdam University of Amsterdam ahn@science.uva.nl Abstract Event detection and recognition is a complex task consisting of multiple sub-tasks
THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING
 SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
SISOM & ACOUSTICS 2015, Bucharest 21-22 May THE ROLE OF DECISION TREES IN NATURAL LANGUAGE PROCESSING MarilenaăLAZ R 1, Diana MILITARU 2 1 Military Equipment and Technologies Research Agency, Bucharest,
Applications of data mining algorithms to analysis of medical data
 Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Master Thesis Software Engineering Thesis no: MSE-2007:20 August 2007 Applications of data mining algorithms to analysis of medical data Dariusz Matyja School of Engineering Blekinge Institute of Technology
Historical maintenance relevant information roadmap for a self-learning maintenance prediction procedural approach
 IOP Conference Series: Materials Science and Engineering PAPER OPEN ACCESS Historical maintenance relevant information roadmap for a self-learning maintenance prediction procedural approach To cite this
IOP Conference Series: Materials Science and Engineering PAPER OPEN ACCESS Historical maintenance relevant information roadmap for a self-learning maintenance prediction procedural approach To cite this
Switchboard Language Model Improvement with Conversational Data from Gigaword
 Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Katholieke Universiteit Leuven Faculty of Engineering Master in Artificial Intelligence (MAI) Speech and Language Technology (SLT) Switchboard Language Model Improvement with Conversational Data from Gigaword
Activity Recognition from Accelerometer Data
 Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Activity Recognition from Accelerometer Data Nishkam Ravi and Nikhil Dandekar and Preetham Mysore and Michael L. Littman Department of Computer Science Rutgers University Piscataway, NJ 08854 {nravi,nikhild,preetham,mlittman}@cs.rutgers.edu
Generating Test Cases From Use Cases
 1 of 13 1/10/2007 10:41 AM Generating Test Cases From Use Cases by Jim Heumann Requirements Management Evangelist Rational Software pdf (155 K) In many organizations, software testing accounts for 30 to
1 of 13 1/10/2007 10:41 AM Generating Test Cases From Use Cases by Jim Heumann Requirements Management Evangelist Rational Software pdf (155 K) In many organizations, software testing accounts for 30 to
Software Development Plan
 Version 2.0e Software Development Plan Tom Welch, CPC Copyright 1997-2001, Tom Welch, CPC Page 1 COVER Date Project Name Project Manager Contact Info Document # Revision Level Label Business Confidential
Version 2.0e Software Development Plan Tom Welch, CPC Copyright 1997-2001, Tom Welch, CPC Page 1 COVER Date Project Name Project Manager Contact Info Document # Revision Level Label Business Confidential
Active Learning. Yingyu Liang Computer Sciences 760 Fall
 Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Active Learning Yingyu Liang Computer Sciences 760 Fall 2017 http://pages.cs.wisc.edu/~yliang/cs760/ Some of the slides in these lectures have been adapted/borrowed from materials developed by Mark Craven,
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models
 Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Extracting Opinion Expressions and Their Polarities Exploration of Pipelines and Joint Models Richard Johansson and Alessandro Moschitti DISI, University of Trento Via Sommarive 14, 38123 Trento (TN),
Conference Presentation
 Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Conference Presentation Towards automatic geolocalisation of speakers of European French SCHERRER, Yves, GOLDMAN, Jean-Philippe Abstract Starting in 2015, Avanzi et al. (2016) have launched several online
Truth Inference in Crowdsourcing: Is the Problem Solved?
 Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Truth Inference in Crowdsourcing: Is the Problem Solved? Yudian Zheng, Guoliang Li #, Yuanbing Li #, Caihua Shan, Reynold Cheng # Department of Computer Science, Tsinghua University Department of Computer
Universidade do Minho Escola de Engenharia
 Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Universidade do Minho Escola de Engenharia Universidade do Minho Escola de Engenharia Dissertação de Mestrado Knowledge Discovery is the nontrivial extraction of implicit, previously unknown, and potentially
Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade
 Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade The third grade standards primarily address multiplication and division, which are covered in Math-U-See
Math-U-See Correlation with the Common Core State Standards for Mathematical Content for Third Grade The third grade standards primarily address multiplication and division, which are covered in Math-U-See
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence
 Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Business Analytics and Information Tech COURSE NUMBER: 33:136:494 COURSE TITLE: Data Mining and Business Intelligence COURSE DESCRIPTION This course presents computing tools and concepts for all stages
Semi-supervised methods of text processing, and an application to medical concept extraction. Yacine Jernite Text-as-Data series September 17.
 Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
Semi-supervised methods of text processing, and an application to medical concept extraction Yacine Jernite Text-as-Data series September 17. 2015 What do we want from text? 1. Extract information 2. Link
arxiv: v1 [cs.cl] 2 Apr 2017
![arxiv: v1 [cs.cl] 2 Apr 2017](/thumbs/71/66163758.jpg "arxiv: v1 [cs.cl] 2 Apr 2017") Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Word-Alignment-Based Segment-Level Machine Translation Evaluation using Word Embeddings Junki Matsuo and Mamoru Komachi Graduate School of System Design, Tokyo Metropolitan University, Japan matsuo-junki@ed.tmu.ac.jp,
Mining Student Evolution Using Associative Classification and Clustering
 Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
Mining Student Evolution Using Associative Classification and Clustering 19 Mining Student Evolution Using Associative Classification and Clustering Kifaya S. Qaddoum, Faculty of Information, Technology
A Vector Space Approach for Aspect-Based Sentiment Analysis
 A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
A Vector Space Approach for Aspect-Based Sentiment Analysis by Abdulaziz Alghunaim B.S., Massachusetts Institute of Technology (2015) Submitted to the Department of Electrical Engineering and Computer
Optimizing to Arbitrary NLP Metrics using Ensemble Selection
 Optimizing to Arbitrary NLP Metrics using Ensemble Selection Art Munson, Claire Cardie, Rich Caruana Department of Computer Science Cornell University Ithaca, NY 14850 {mmunson, cardie, caruana}@cs.cornell.edu
Optimizing to Arbitrary NLP Metrics using Ensemble Selection Art Munson, Claire Cardie, Rich Caruana Department of Computer Science Cornell University Ithaca, NY 14850 {mmunson, cardie, caruana}@cs.cornell.edu
Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes
 Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes Viviana Molano 1, Carlos Cobos 1, Martha Mendoza 1, Enrique Herrera-Viedma 2, and
Feature Selection based on Sampling and C4.5 Algorithm to Improve the Quality of Text Classification using Naïve Bayes Viviana Molano 1, Carlos Cobos 1, Martha Mendoza 1, Enrique Herrera-Viedma 2, and
Indian Institute of Technology, Kanpur
 Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Indian Institute of Technology, Kanpur Course Project - CS671A POS Tagging of Code Mixed Text Ayushman Sisodiya (12188) {ayushmn@iitk.ac.in} Donthu Vamsi Krishna (15111016) {vamsi@iitk.ac.in} Sandeep Kumar
Using dialogue context to improve parsing performance in dialogue systems
 Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Using dialogue context to improve parsing performance in dialogue systems Ivan Meza-Ruiz and Oliver Lemon School of Informatics, Edinburgh University 2 Buccleuch Place, Edinburgh I.V.Meza-Ruiz@sms.ed.ac.uk,
Finding Your Friends and Following Them to Where You Are
 Finding Your Friends and Following Them to Where You Are Adam Sadilek Dept. of Computer Science University of Rochester Rochester, NY, USA sadilek@cs.rochester.edu Henry Kautz Dept. of Computer Science
Finding Your Friends and Following Them to Where You Are Adam Sadilek Dept. of Computer Science University of Rochester Rochester, NY, USA sadilek@cs.rochester.edu Henry Kautz Dept. of Computer Science
CSC200: Lecture 4. Allan Borodin
 CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
CSC200: Lecture 4 Allan Borodin 1 / 22 Announcements My apologies for the tutorial room mixup on Wednesday. The room SS 1088 is only reserved for Fridays and I forgot that. My office hours: Tuesdays 2-4
B. How to write a research paper
 From: Nikolaus Correll. "Introduction to Autonomous Robots", ISBN 1493773070, CC-ND 3.0 B. How to write a research paper The final deliverable of a robotics class often is a write-up on a research project,
From: Nikolaus Correll. "Introduction to Autonomous Robots", ISBN 1493773070, CC-ND 3.0 B. How to write a research paper The final deliverable of a robotics class often is a write-up on a research project,
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks
 POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
POS tagging of Chinese Buddhist texts using Recurrent Neural Networks Longlu Qin Department of East Asian Languages and Cultures longlu@stanford.edu Abstract Chinese POS tagging, as one of the most important
Visit us at:
 White Paper Integrating Six Sigma and Software Testing Process for Removal of Wastage & Optimizing Resource Utilization 24 October 2013 With resources working for extended hours and in a pressurized environment,
White Paper Integrating Six Sigma and Software Testing Process for Removal of Wastage & Optimizing Resource Utilization 24 October 2013 With resources working for extended hours and in a pressurized environment,
Netpix: A Method of Feature Selection Leading. to Accurate Sentiment-Based Classification Models
 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models 1 Netpix: A Method of Feature Selection Leading to Accurate Sentiment-Based Classification Models James B.
Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation
 School of Computer Science Human-Computer Interaction Institute Carnegie Mellon University Year 2007 Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation Noboru Matsuda
School of Computer Science Human-Computer Interaction Institute Carnegie Mellon University Year 2007 Predicting Students Performance with SimStudent: Learning Cognitive Skills from Observation Noboru Matsuda
Beyond the Pipeline: Discrete Optimization in NLP
 Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
Beyond the Pipeline: Discrete Optimization in NLP Tomasz Marciniak and Michael Strube EML Research ggmbh Schloss-Wolfsbrunnenweg 33 69118 Heidelberg, Germany http://www.eml-research.de/nlp Abstract We
This scope and sequence assumes 160 days for instruction, divided among 15 units.
 In previous grades, students learned strategies for multiplication and division, developed understanding of structure of the place value system, and applied understanding of fractions to addition and subtraction
In previous grades, students learned strategies for multiplication and division, developed understanding of structure of the place value system, and applied understanding of fractions to addition and subtraction
K-Medoid Algorithm in Clustering Student Scholarship Applicants
 Scientific Journal of Informatics Vol. 4, No. 1, May 2017 p-issn 2407-7658 http://journal.unnes.ac.id/nju/index.php/sji e-issn 2460-0040 K-Medoid Algorithm in Clustering Student Scholarship Applicants
Scientific Journal of Informatics Vol. 4, No. 1, May 2017 p-issn 2407-7658 http://journal.unnes.ac.id/nju/index.php/sji e-issn 2460-0040 K-Medoid Algorithm in Clustering Student Scholarship Applicants
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS
 COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
COMPUTER-ASSISTED INDEPENDENT STUDY IN MULTIVARIATE CALCULUS L. Descalço 1, Paula Carvalho 1, J.P. Cruz 1, Paula Oliveira 1, Dina Seabra 2 1 Departamento de Matemática, Universidade de Aveiro (PORTUGAL)
CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH
 ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
ISSN: 0976-3104 Danti and Bhushan. ARTICLE OPEN ACCESS CLASSIFICATION OF TEXT DOCUMENTS USING INTEGER REPRESENTATION AND REGRESSION: AN INTEGRATED APPROACH Ajit Danti 1 and SN Bharath Bhushan 2* 1 Department
Radius STEM Readiness TM
 Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Curriculum Guide Radius STEM Readiness TM While today s teens are surrounded by technology, we face a stark and imminent shortage of graduates pursuing careers in Science, Technology, Engineering, and
Content-based Image Retrieval Using Image Regions as Query Examples
 Content-based Image Retrieval Using Image Regions as Query Examples D. N. F. Awang Iskandar James A. Thom S. M. M. Tahaghoghi School of Computer Science and Information Technology, RMIT University Melbourne,
Content-based Image Retrieval Using Image Regions as Query Examples D. N. F. Awang Iskandar James A. Thom S. M. M. Tahaghoghi School of Computer Science and Information Technology, RMIT University Melbourne,
Handling Concept Drifts Using Dynamic Selection of Classifiers
 Handling Concept Drifts Using Dynamic Selection of Classifiers Paulo R. Lisboa de Almeida, Luiz S. Oliveira, Alceu de Souza Britto Jr. and and Robert Sabourin Universidade Federal do Paraná, DInf, Curitiba,
Handling Concept Drifts Using Dynamic Selection of Classifiers Paulo R. Lisboa de Almeida, Luiz S. Oliveira, Alceu de Souza Britto Jr. and and Robert Sabourin Universidade Federal do Paraná, DInf, Curitiba,
Large-Scale Web Page Classification. Sathi T Marath. Submitted in partial fulfilment of the requirements. for the degree of Doctor of Philosophy
 Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
Large-Scale Web Page Classification by Sathi T Marath Submitted in partial fulfilment of the requirements for the degree of Doctor of Philosophy at Dalhousie University Halifax, Nova Scotia November 2010
An Empirical Comparison of Supervised Ensemble Learning Approaches
 An Empirical Comparison of Supervised Ensemble Learning Approaches Mohamed Bibimoune 1,2, Haytham Elghazel 1, Alex Aussem 1 1 Université de Lyon, CNRS Université Lyon 1, LIRIS UMR 5205, F-69622, France
An Empirical Comparison of Supervised Ensemble Learning Approaches Mohamed Bibimoune 1,2, Haytham Elghazel 1, Alex Aussem 1 1 Université de Lyon, CNRS Université Lyon 1, LIRIS UMR 5205, F-69622, France
South Carolina College- and Career-Ready Standards for Mathematics. Standards Unpacking Documents Grade 5
 South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents Grade 5 South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents
South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents Grade 5 South Carolina College- and Career-Ready Standards for Mathematics Standards Unpacking Documents
Language Acquisition Fall 2010/Winter Lexical Categories. Afra Alishahi, Heiner Drenhaus
 Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Language Acquisition Fall 2010/Winter 2011 Lexical Categories Afra Alishahi, Heiner Drenhaus Computational Linguistics and Phonetics Saarland University Children s Sensitivity to Lexical Categories Look,
Article A Novel, Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful: A Case Study for Modern Greek
 Article A Novel, Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful: A Case Study for Modern Greek Vasileios Athanasiou and Manolis Maragoudakis * Artificial
Article A Novel, Gradient Boosting Framework for Sentiment Analysis in Languages where NLP Resources Are Not Plentiful: A Case Study for Modern Greek Vasileios Athanasiou and Manolis Maragoudakis * Artificial
Using Web Searches on Important Words to Create Background Sets for LSI Classification
 Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Using Web Searches on Important Words to Create Background Sets for LSI Classification Sarah Zelikovitz and Marina Kogan College of Staten Island of CUNY 2800 Victory Blvd Staten Island, NY 11314 Abstract
Fragment Analysis and Test Case Generation using F- Measure for Adaptive Random Testing and Partitioned Block based Adaptive Random Testing
 Fragment Analysis and Test Case Generation using F- Measure for Adaptive Random Testing and Partitioned Block based Adaptive Random Testing D. Indhumathi Research Scholar Department of Information Technology
Fragment Analysis and Test Case Generation using F- Measure for Adaptive Random Testing and Partitioned Block based Adaptive Random Testing D. Indhumathi Research Scholar Department of Information Technology
arxiv: v1 [cs.lg] 3 May 2013
![arxiv: v1 [cs.lg] 3 May 2013](/thumbs/71/66031940.jpg "arxiv: v1 [cs.lg] 3 May 2013") Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Feature Selection Based on Term Frequency and T-Test for Text Categorization Deqing Wang dqwang@nlsde.buaa.edu.cn Hui Zhang hzhang@nlsde.buaa.edu.cn Rui Liu, Weifeng Lv {liurui,lwf}@nlsde.buaa.edu.cn arxiv:1305.0638v1
Automatic document classification of biological literature
 BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic
BMC Bioinformatics This Provisional PDF corresponds to the article as it appeared upon acceptance. Copyedited and fully formatted PDF and full text (HTML) versions will be made available soon. Automatic
Bachelor Class
 Bachelor Class 2015-2016 Siegfried Nijssen 11 January 2016 Popularity of Topics 1 Popularity of Topics 4 Popularity of Topics Assignment of Topics I contacted all supervisors with the first choices Most
Bachelor Class 2015-2016 Siegfried Nijssen 11 January 2016 Popularity of Topics 1 Popularity of Topics 4 Popularity of Topics Assignment of Topics I contacted all supervisors with the first choices Most
Montana Content Standards for Mathematics Grade 3. Montana Content Standards for Mathematical Practices and Mathematics Content Adopted November 2011
 Montana Content Standards for Mathematics Grade 3 Montana Content Standards for Mathematical Practices and Mathematics Content Adopted November 2011 Contents Standards for Mathematical Practice: Grade
Montana Content Standards for Mathematics Grade 3 Montana Content Standards for Mathematical Practices and Mathematics Content Adopted November 2011 Contents Standards for Mathematical Practice: Grade
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar
 EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
EdIt: A Broad-Coverage Grammar Checker Using Pattern Grammar Chung-Chi Huang Mei-Hua Chen Shih-Ting Huang Jason S. Chang Institute of Information Systems and Applications, National Tsing Hua University,
Simple Random Sample (SRS) & Voluntary Response Sample: Examples: A Voluntary Response Sample: Examples: Systematic Sample Best Used When
 & Voluntary Response Sample: Examples: A Voluntary Response Sample: Examples: Systematic Sample Best Used When") Simple Random Sample (SRS) & Voluntary Response Sample: In statistics, a simple random sample is a group of people who have been chosen at random from the general population. A simple random sample is
Simple Random Sample (SRS) & Voluntary Response Sample: In statistics, a simple random sample is a group of people who have been chosen at random from the general population. A simple random sample is
Artificial Neural Networks written examination
 1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
1 (8) Institutionen för informationsteknologi Olle Gällmo Universitetsadjunkt Adress: Lägerhyddsvägen 2 Box 337 751 05 Uppsala Artificial Neural Networks written examination Monday, May 15, 2006 9 00-14
Physics 270: Experimental Physics
 2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
2017 edition Lab Manual Physics 270 3 Physics 270: Experimental Physics Lecture: Lab: Instructor: Office: Email: Tuesdays, 2 3:50 PM Thursdays, 2 4:50 PM Dr. Uttam Manna 313C Moulton Hall umanna@ilstu.edu
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Model Ensemble for Click Prediction in Bing Search Ads
 Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
Model Ensemble for Click Prediction in Bing Search Ads Xiaoliang Ling Microsoft Bing xiaoling@microsoft.com Hucheng Zhou Microsoft Research huzho@microsoft.com Weiwei Deng Microsoft Bing dedeng@microsoft.com
For Jury Evaluation. The Road to Enlightenment: Generating Insight and Predicting Consumer Actions in Digital Markets
 FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO The Road to Enlightenment: Generating Insight and Predicting Consumer Actions in Digital Markets Jorge Moreira da Silva For Jury Evaluation Mestrado Integrado
FACULDADE DE ENGENHARIA DA UNIVERSIDADE DO PORTO The Road to Enlightenment: Generating Insight and Predicting Consumer Actions in Digital Markets Jorge Moreira da Silva For Jury Evaluation Mestrado Integrado
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT
 WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
WE GAVE A LAWYER BASIC MATH SKILLS, AND YOU WON T BELIEVE WHAT HAPPENED NEXT PRACTICAL APPLICATIONS OF RANDOM SAMPLING IN ediscovery By Matthew Verga, J.D. INTRODUCTION Anyone who spends ample time working
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling
 Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Experiments with SMS Translation and Stochastic Gradient Descent in Spanish Text Author Profiling Notebook for PAN at CLEF 2013 Andrés Alfonso Caurcel Díaz 1 and José María Gómez Hidalgo 2 1 Universidad
Welcome to. ECML/PKDD 2004 Community meeting
 Welcome to ECML/PKDD 2004 Community meeting A brief report from the program chairs Jean-Francois Boulicaut, INSA-Lyon, France Floriana Esposito, University of Bari, Italy Fosca Giannotti, ISTI-CNR, Pisa,
Welcome to ECML/PKDD 2004 Community meeting A brief report from the program chairs Jean-Francois Boulicaut, INSA-Lyon, France Floriana Esposito, University of Bari, Italy Fosca Giannotti, ISTI-CNR, Pisa,