DEVANAGARI SCRIPT BEHAVIOUR FOR HINDI. Prepared by. Technology Development for Indian Languages (TDIL) Programme
|
|
|
- Elvin Morris
- 5 years ago
- Views:
Transcription
1 DEVANAGARI SCRIPT BEHAVIOUR FOR HINDI Prepared by Technology Development for Indian Languages (TDIL) Programme Department of Electronics and Information Technology, Government of India in association with Centre for Development of Advanced Computing (C-DAC) 1
2 Table of Contents 0. INTRODUCTION OBJECTIVES OF "Devanagari Script behaviour for Hindi" END USERS FOR "Devanagari Script behaviour for Hindi" SCOPE TERMINOLOGY PHILOSOPHY AND UNDERLYING PRINCIPLES Devanagari Script behaviour for Hindi : STRUCTURE PERIPHERAL ELEMENTS OF THE "Devanagari Script behaviour for Hindi" CONFORMITY TO THE SYLLABLE STRUCTURE DEVANAGARI SCRIPT BEHAVIOUR FOR HINDI PROPER The Character Set of Hindi Consonant Mātrā Combinations The Ligature Set of Hindi Valid Combinations And Invalid Combinations The Collation Order of Hindi REFERENCES ANNEXURES Annexure I : Names of experts who have redrafted the document based on inputs of the committee Annexure 2: Shapes of Hindi characters as per Central Hindi Directorate Annexure 3: A Note on Zero Width Joiner and Zero Width Non-Joiner Annexure 4: Unicode Table of Devanāgarī Annexure 5: Definition of the Indic Akshar Annexure 6: NOTE ON AMBIGUOUS USE OF ANUSWARA (ANUNASIKA) WITH SUPERSCRIPT VOWEL SIGNS IN HINDI
3 0. INTRODUCTION The term Devanagari Script Behaviour for Hindi refers to the behaviour pattern of the writing system of Hindi. Languages which have written representations do not use a haphazard manner of storing the information within the system, but use a coherent pattern which is similar to the linguistic grammar of a given language. With the help of specialists (linguists, font designers, language experts, academicians) who work in the area of the written representation of the language, the manner in which the shapes of the characters of the language and the representation of the conjunct forms is provided. In other words, the Devanagari Script behaviour for Hindi deals with the surface structure of the Hindi and tries to provide the best possible fit for shapes and their representation. Since this is a highly subjective issue, the shapes provided here are recommendations at the best and conform to the perception of the mandating body/evaluators that consensually arrive at the best possible fit which is acceptable to a majority of users. Devanagari is a script shared by a large number of languages. In all, apart from Hindi, ten other official languages of India share the same script. However, although these languages share the same matricial script, they differ in the manner in which a. The choice of a character borrowed from the code-block of Devanagari script. b. The shape of a given character is represented c. The ligatural form of a given conjunct is represented d. The collation order. Each of these is explained below: a. Choice of Character: Languages differ in the choice of the characters from the Devanagari code-page. Thus Marathi and Konkani use ळ and ऱ (for generating out the eyelash ra). These are not present in Hindi or Dogri. The Hindi ऍ (U+090D) is represented in Marathi and Konkani as (U+0972). Nukta is used in Hindi and Dogri but not in Marathi or Konkani. b. The shape of the given character. Although Marathi and Hindi share the same script Devanāgarī, not only do they not share the same character inventory but in addition the representation of certain characters is different. Thus the Hindi /la/ is different from the Marathi /la/ in so far as the placement of the stem is concerned Hindi /ल/ Marathi /. 3
4 The same is the case with श which is represented in Hindi as श but in Marathi as Numbers also display differences The Hindi number set is as under: ० १ २ ३ ४ ५ ६ ७ ८ ९ The Marathi and Konkani number set is as under: c. The Ligatural shape of the conjunct. Marathi, Nepali and Konkani prefer stacked shapes of the conjuncts, whereas Hindi as per the directives of the Central Hindi Directorate (q.v.) prefers as far as possible to show conjuncts as linear. Thus the same ligature is seen as linear if the language is Hindi and as stacked if the language is Nepali or Marathi 1 Hindi: शक त Nepali/Marathi: However, in the case of the following stack, a marked difference is noticed. Central Hindi Directorate states that the conjunct of क and ल be linear and not stacked unlike Marathi where the conjunct is stacked: श तल d. The collation order within the language. The collation order 2 varies from language to language although they all share the same script. In the case of Hindi क ष ज ञ त र are sorted along with the first consonant of each ligature. Thus क ष is sorted along with क, ज ञ with ज and त र with त In Marathi क ष ज ञ occur at the end of the lexical sort, giving the two conjuncts a specific value of a letter. In Nepali क ष ज ञ त र are sorted at the end From the above it will be evident that each language, although it shares the same script, manifests a different behaviour insofar as the implementation of the script is concerned, in terms of its shapes, its ligatural form or even its collation order. Devanagari Script behaviour for Hindi is the term used to define: The writing system used to inscribe a Hindi The syllabic structure of the writing system of Hindi The rule ordering of the characters within the syllable 1, Although the Central Hindi Directorate recommends त as the normative form, in Hindi both versions seem to be used cf. books published by reputed publishers (शक त & are acceptable in Hindi writing style. 2 Cf of the document ). It would appear that both form 4
5 Description of the syllabic clusters / ligatures Description of valid and invalid clusters i.e. clusters not used within the Hindi Collation order of the characters: lexical / dictionary sorting order As mentioned above Devanāgarī caters to 11 official languages of India. Each of these languages has different representations of the shape of Individual characters as well as their ligatural representations. The Devanagari Script behaviour for Hindi in this document is pertinent to Hindi. Other similar documents define the structure of Marathi, Sanskrit, Nepali to name a few languages sharing the common script Devanāgarī and the Unicode code-block F (with exception of Rupee Sign and Swastik). 5
6 1. OBJECTIVES OF "Devanagari Script behaviour for Hindi" The objectives of the Devanagari Script behaviour for Hindi for language can be divided into two major parts: Societal: Provide a visual representation of shapes that are deemed to be in conformity with the perception of a given community. Ensure thereby that this perception is safe-guarded. Through wide-spread dissemination and creation of appropriate tools ensure that within the given linguistic community, all media try to adopt the given shape. Technical: Classify the language in terms of its ISO and also whether it belongs to the Abjad, Akshar (Alphasyllabary) class. Provide an inventory of the characters pertinent to the language and classify the same in terms of their taxonomy. As a corollary determine whether the inventory is in conformity to the Syllable Formalism as stipulated in ISCII 91 and subsequently adopted by Unicode. Since Brahmi is written from left to right, and since certain characters do not follow the linear left to right order, provide an inventory of displaced catenators, i.e. characters such as Mātrās that concatenate to the Consonant Propose the best shape representation of the individual characters as well as of the ligatures used within a given script. As a corollary request the expert(s) to identify the largest possible strings of such ligatures. This would serve as a useful input for the font developer, desirous of knowing the visual representation of such combinations and clusters. In the case of consonant clusters and ligatural forms, identify to maximum extent such valid combinations and list them out. This would serve as a useful guide for OS developers who would use these to validate or invalidate a combination, entered by the user. Provide usage of Zero Width Joiner (ZWJ) and Zero Width Non Joiner (ZWNJ) within the language. Since ZWJ/ZWNJ are stored in the data, this would ensure that incorrect use of these two signs which could affect search as well as Natural Language Processing, be avoided. 6
7 Finally provide the collation order pertinent to that Script / Language, which would be of great utility to high-end NLP as well as to CLDR s in the pertinent language. The collation order for Hindi is different from Marathi although both languages share the same script. Thus, in Marathi क ष, ज ञ are placed at the end of the consonant inventory, i.e. after ह in the sort order. In Hindi क ष is sorted along with क and ज ञ with ज. 7
8 2. END USERS FOR "Devanagari Script behaviour for Hindi" The Devanagari Script behaviour for Hindi can be used by a large number of users. The primary aim of the Devanagari Script behaviour for Hindi has been for the font developer. The Devanagari Script behaviour for Hindi can be used by font developers desirous of developing a font which is compliant with the perception of the characters and ligatures of a language by its user community. It allows the font designer to design a font which is in compliance with the norms and standards of that particular script. A major problem which will be dealt with in the template is one of ligatures. The final list of ligatures defined by the Devanagari Script behaviour for Hindi allows the font designer to write specific rules for such glyphs. The other target group is the OS and application developer. Once the possible ligatures and consonant Mātrā combinations have been identified, there is a need to provide a list of maximum combinations within the language. Certain features of the Devanagari Script behaviour for Hindi such as the shapes can also be used for testing Optical Character Recognition (OCR) and Online Handwriting Recognition (OHWR). Similarly information regarding ligatures as well as collation order can help in high-end NLP work such as detecting invalid combinations, correct implementation of syllable structure, prediction routines to name a few. Information regarding collation and character sets can be also used for CLDR. It permits the software developer to design and implement the keyboard and the input mechanism which will meet the requirement of the particular linguistic community. The collation or sort order as described in a Devanagari Script behaviour for Hindi permits the software developer to write software functions/ routines for sorting data in all applications. Devanagari Script behaviour for Hindi is equally important for keyboard design, especially when supplemented by frequency data from a corpus. As can be seen, the Devanagari Script behaviour for Hindi has a wide range of use and can be of utility to font developers, Indian language developers and linguists in the area of computation. 8
9 3. SCOPE This document contains following information about the language and the script used for writing the language. 1. Name of the language and its representation in the 3 letter mnemonic as per ISO & ISO standard. 2. Script used to inscribe the given language 3. The structure of the script used for writing the language Rule ordering of the characters within the syllable formation is a language Description of the syllabic clusters of the script Collation order of the characters: lexical / dictionary sorting order Compliance of the script with Unicode. These will be treated within the relevant sections of the document. 9
10 4. TERMINOLOGY 3 Abjad: A writing system in which each symbol always or usually stands for a consonant. The long vowels are indicated. However the short vowels are rarely marked and the reader needs to supply these. Example: Urdu written in Perso-Arabic Script is an example of this writing system. Abugida: Also called an alphasyllabary, it is a segmental writing system in which consonant vowel sequences are written as a unit: each unit is based on a consonant letter, and vowel notation is obligatory, but secondary. 4 The definition of Abugida can be taken from Unicode chapter 6 instead of Wikipedia Akshar: see Abugida. Allographs: A variant form of a grapheme that is in complementary distribution or free variation with another form of the same grapheme; an orthographic contextual variant 5. Thus ae and æ [U+00E6] in Latin alphabet are allographs. Similarly Rafar (repha), Rakar (cf. below) in Indic Scripts are allographs. AlloScript: The term relates to languages which share a common script. Sub-sets of scripts sharing a single matricial script are termed as alloscripts Thus Devanāgarī script is used to write 11 official languages of India. However these languages do not use the same set of characters. Marathi uses the retroflex lla - ळ [U+ 0933] which Hindi does not use. Flaps used in Hindi ड़ [U+095C] ढ [U+095D] are not used in Konkani. Alphabet: A set of letters used in writing a language. Example: The English alphabet. Aspirated consonant: A consonant which is pronounced with an extra puff of air coming out at the time of release of the oral obstruction 6. A consonant, especially a stop consonant followed by a puff of breath that is clearly audible before the next sound begins. 7 Example ख in Hindi Basic alphabet: The minimal set of letters which can be used for uniquely encoding every word of a language. The basic alphabet for English consists of only the upper-case letters A-Z. 3 As in the case of the BIS Document, in order to make the terminology accessible for all readers, examples have been chosen from English/Latin scripts, wherever possible. Some definitions have been excerpted from the BIS ISCII91 document and suitably modified where necessary. 4 Wikipedia definition Cf. P of BIS Document Slightly modified. 10
11 Catenators: Also termed as concatenators, these are characters which are concatenated to another character. In the Brahmi script these are the Mātrās or Vowel modifiers which are adjoined to the consonant and add a vocalic value to the consonant. Conjunct: The Brahmi derived scripts are noted for a large number of consonant conjunct forms that serve as orthographic abbreviations (ligatures) of two or more adjacent letterforms. This abbreviation takes place only in the context of a consonant cluster. Under normal circumstances, a consonant cluster is depicted with a conjunct glyph if such a glyph is available in the current font. In the absence of a conjunct glyph, the one or more dead consonants that form part of the cluster are depicted using half-form glyphs. In the absence of half-form glyphs, the dead consonants are depicted using the nominal consonant forms combined with visible virama signs. 8 Consonant: A letter representing a speech sound in which the flow of air is at least partly obstructed in the oral tract. Diacritic: A mark added to a letter which distinguishes it from the same letter without a mark, usually having a different phonetic value or stress. Displaced Catenator: (see Catenator) Within the Brahmi script, the writing system is linear and moves from left to right. However, in the case of some catenators this rule is not observed and the catenator (wholly or partially) is placed to the right of the consonant to which it relates. The short vowel i / / in Devanāgarī is an example of a displaced catenator. Display composing: It is the process of organizing the basic shapes available in a font in order to display (or print) a word. Display rendition: It is the process by which a string of characters is displayed (or printed). In this process several consecutive characters may combine with each other on the screen. The sequence of display of the characters may become different. Eyebrow repha: (See Eyelash ra). Eyelash ra: The eyelash ra or eyebrow ra is an allograph of ra+halant followed by ya or ha resulting in the following shape of ra: ऱ य ऱ ह. It is used in Konkani, Nepali and Marathi. In Marathi not all combinations of this type generate an eyelash ra e.g. दर य /darya/ ocean vs. दर र य /darya/ valleys. Unicode prescribes a combination of ऱ +य U+0931 U+094D U+092F ऱ +ह U+0931 U+094D U+0939 for generating the eyelash 8 Unicode ver. 6.0 Chapter 9.0 pp
12 ra. Earlier the eyelash ra was generated by a combination of ra+halant+zwj ऱ i.e. U+0930 U+094D U+200D Font: A set of symbols used for display or printing of a script in a particular style. International numerals: The conventional 0 to 9 digits used in English for denoting numbers. These are also known as Indo-Arabic numerals (to differentiate them from the Roman numerals like IX for 9). Latin alphabet: The alphabet used for writing the language of ancient Rome. Also known as the Roman alphabet. The alphabet is used today for writing English and European languages and also many Indian languages.. Letter: A character representing one or more of the simple or compound sounds used in speech. It can be any of the alphabetic symbols. Ligature: (see Conjunct). Nasal consonant: A consonant pronounced with the flow of air passing through the nose and the mouth. Example m, n in English. Nasalized vowel (Anunasika): A vowel pronounced with the flow of air passing both through the nose and the mouth. In Indian scripts this is denoted by a Candrabindu and gives the vowel/vowel sign over which it is placed a nasalized value. Example: ज च Phonetic alphabet: An alphabet which has direct correspondence between letters and sounds Example: The International Phonetic Alphabet. Pure consonant 11 : A consonant which does not have any vowel implicitly associated with it. Rafar: A special case of a ligature constituted by the adjunction of ra followed by a halant to consonant. The resultant combination places the ra on top of the consonant to which it is adjoined e.g. र +क = क In case the consonant itself is adjoined to another consonant, the rafar is placed above the final consonant of the ligature group e.g. र +घ +र य = र घर यक. See Repha. Rakar: A special case of a ligature constituted by the adjunction of a consonant followed by a halant to ra. In a large number of Brahmi derived scripts the ra is adjoined to the stem of consonant to which it relates e.g. क र In the case of consonants which have no Cf. p64 of this document 11 The term used is as per BIS DOCUMENT IS 13194: However, it could also be termed as short obstructive sound as per suggestion of experts. 12
13 stem such as the retroflexes in Devanāgarī, the rakar is placed below the consonant to which it relates e.g. ट र. Repha: (see Rafar). Roman script 12 : The script based on the ancient Roman alphabet, with the letters A Z and a-z (upper and lower case) and also additional diacritic marks used for writing a language which is not usually written in the Roman alphabet. Script: A distinctive and complete set of characters used for the written form of one or more languages. Script numerals: The 0 to 9 digits in a script, which have shapes distinct from their international counterparts. Syllable: A unit of pronunciation uttered without interruption, forming whole or part of a word, and usually having one vowel or diphthong sound optionally surrounded by one or more consonants. Transliteration: Representation of words with the closest corresponding letters in an alphabet of a different language. Vowel: The BIS document defines the vowel as A letter representing a speech sound made with the vibration of the vocal cords, but without audible obstruction 13. In some languages voiceless vowels do occur. Linguistically a Vowel is defined as a speech sound which is produced by comparatively open configuration of the vocal tract, with vibration of the vocal cords but without audible friction, and which is a unit of the sound system of a language that forms the nucleus of a syllable 14. Vowel sign/allograph: A graphic character associated with a letter, to Brahmi derived from a vowel to be associated with that character (Mātrā in Hindi). 12 The term used is as per BIS DOCUMENT IS 13194: 1991.Point No p Cf. P BIS Document IS
14 5. PHILOSOPHY AND UNDERLYING PRINCIPLES The Devanagari Script behaviour for Hindi is based on the following principles: 1. The document aims to depict the surface grammar of the written language: the manner in which characters as well as conjuncts are depicted. 2. Where a given script admits many languages, it is pre-supposed that such languages will prescribe different representations for a given shape or conjunct according to the perception of the native users of that language. 3. Corollary to the above, the result is a script and alloscripts i.e. a given script shared by many languages is not uniformly deployed across all the languages, but is subject to variations and modulations. 4. The term Devanagari Script behaviour for Hindi is used here in a nonnormative sense: what is prescribed is in the form of recommendations provided by experts who visualize the shape of the given script in their mother tongue in a specific manner. Subjective variations may occur The Devanagari Script behaviour for Hindi is limited to its synchronic use, i.e. the manner in which a given language as of today admits a character set within the script used to write it. It is not diachronic or historical in nature and does not study the evolution of the given script across centuries. 15 It is recommended that such variations be culled by placing the document for public review.. 14
15 6. Devanagari Script behaviour for Hindi : STRUCTURE The Devanagari Script behaviour for Hindi provided below has the following parts. Part 6.1. deals with peripheral elements such as the ISO of the language, the writing system used: (Alphasyllabic) Abugida or Abjad. Part 6.2. treats of the syllabic structure. It verifies whether the character set of the language complies with the ISCII syllabic structure and if not, which cases are not compliant. Part 6.3. is the Devanagari Script behaviour for Hindi proper and describes the character set as well as the conjunct shapes of the given script along with the collation order. Section which deals with the character set of the language. Sections and deal with the Consonant-Mātrā/ Consonant-Mātrā-Nasal combinations and also the 2, 3 and 4 Consonant Ligatures within the language. Combinations of Vowel with Anuswara 16 and Candrabindu are also provided. 16 Although Unicode uses the term Anuswar and some texts use the term Anunasika, the correct term to be used is Bindu. Anuswar is the linguistic term used for characterizing NASAL VOWELS, and anunasika is the term used for characterizing NASAL CONSONANTS. The diacritics should simply be called 'bindu' and chandrabindu'. (Dr Pramod Pandey) 15
16 6.1. PERIPHERAL ELEMENTS OF THE "Devanagari Script behaviour for Hindi" These constitute the elements that are peripheral to the document. The main parameters considered are the mnemonic and name of the language (needed for CLDR and also for language tags), the writing system used to inscribe the language and wherever possible a short history of the language Name of the language and its representation in the 3 letter mnemonic as per ISO & Name of the Language: HINDI ISO Mnemonics: hin This refers to a one line description of the language and its mnemonic representation as per the ISO Identification of the writing system(s) used to inscribe the given language Hindi is written using the Devanāgarī script. It is an alphasyllabary with the akshar as its core. This is a one line description of the script used to write the language. However, in case the language uses more than one script, all the scripts in question are specified, provided these constitute the official language of the given state. All scripts derived from Brahmi are Abugidas, i.e. syllabary driven systems. The main features of Abugidas are as under: The consonant has an implicit vowel built-in which is normally the schwa. The inherent vowel can be modified by the addition of other vowels or muted by a diacritic termed as a Virama or Halanta. Vowels can be handled as full vowels with a vocalic value. When two or more consonants join together they form ligatures which can be recognized by their shape तल or alternatively form an entirely new shape क ष = क ष. Abugidas / Alphasyllabaries because of their syllabic structure require a special description which is the subject of the discussion in 6.2. below Amendments needed in Unicode for Hindi language None has been proposed by the experts who have mandated the document. 16
17 6.2. CONFORMITY TO THE SYLLABLE STRUCTURE 17 Hindi language complies with the akshar structure described above. It can admit up to 3 consonant clusters. Alphasyllabaries are determined by the notion of the Akshar. The compositional grammar of the syllable determines it well-formedness. This is through a series of formal constraints based on a Backus-Naur Formalism which is given below. The akshar, first defined in the ISCII document (1991), identifies the following character sub-sets for the purposes of identifying the akshar. In what follows the syllable analysis will be restricted to Hindi. (C) Consonants क क ख ख ग ग घ ङ च छ ज ज झ ञ ट ठ ड ड़ ढ ढ ण थ द ध न प फ फ ब भ म र य र ल व श ष स ह (V) Vowels अ आ इ ई उ ऊ ऋ ए ऍ ऐ ओ ऑ औ (M) Mātrās 17 Annexure 5 provides a formalism for the Indic Akshar as represented on the W3CIndia site 18 अ अ are taught in primary schools as part of the barakhadi. However they have been excluded in the list since these are not individual characters per se but are combinations of the vowel अ and respectively. It is for this reason that Unicode does not provide separate code points for अ अ. 19 ऍ ऑ are accepted for transliterating Loan words borrowed from English such as ऑफ. In the case of the two short vowels ऎ,ऒ used in Dravidian, as per recommendation of Central Hindi Directorate p. 35, words having a short letter/short vowel sign and admitted in Hindi are automatically replaced by the corresponding long letter/vowel sign. Thus the short o of Oddanchatram ஒட டன சத த ரம is rendered as long o in Hindi: ओट टणचत त रम 17
18 (D) Diacritics - Anuswara Anuswara, an archinasal, is denoted by a dot above the letter after which it is to be pronounced. This falls under Nasal category. Candrabindu Candrabindu is pure nasalization as air comes from the nose. It is denoted by a breve with a dot superposed above the letter after which it is to be pronounced. This falls under Nasal category. -Visarga Visarga, denoted by two dots placed one above the other. For extra length with long vowels as seen in the Sanskrit text /उपद श ऽजन न सक/ ऽ - Avagraha 20 (H) Halanta - Halanta is used in most writing systems to signify the lack of an inherent vowel. (N) 21 Nukta Nukta is used in Hindi Each of these sub-types has its restrictions in terms of what can precede or follow it, within an akshar, as shown in the table below: PRECEDED BY SUBTYPE FOLLOWED BY H C N,M,D,H C N M,D,H V D C, N M D C, N,V,M D C, N H C C can be preceded by H or no subtype and followed by any one of the following: N,M,D,H N can be preceded by C and followed by any one of the following: M,D,H V can be preceded by no subtype and followed by D but not by another sub-type Avagraha is rarely used in Hindi and is used for representing text in Sanskrit where the character is needed.. 21 The nukta is a small dot placed under a character in certain scripts to show that they are flapped or for deriving consonants required for Urdu क,ख,ग,ज,फ 22 V followed by any other subtype will be either an illegal combination or will constitute two aksharas. Thus VM is illegal whereas VV as in आईन is a combination of two aksharas. 18
19 M can be preceded by C,N and followed by D. D can be preceded by C, N, V, M and followed by no other subtype. It closes the akshar. H can be preceded by C,N and followed only by C and no other sub-set Akshar Types The formalism defines the akshar in terms of both what can constitute an akshar and what cannot. A valid akshar as per this definition can be of only two types: 1. A vowel akshar : a full vowel. 2. A consonant akshar : a full consonant (having a mātrā ) The four other subsets viz. Mātrās, Vowel Modifiers, Halanta and Nukta cannot constitute an akshar by themselves or in combination among themselves. 1. The Vowel akshar is of the following types: 1.1. A pure vowel all by itself: अ, /a/ आ /ā/ etc A vowel followed by a modifier, i.e. either an archinasal (anuswara) or a visarga: ई /ĩ /, आ /āh/ 2. The Consonant akshar can be of the following types: 2.1. A full consonant (with or without Nukta), i.e. with the inherent vowel : क : /ka/ 2.2. A consonant 23 (with or without Nukta) followed by a mātrā, i.e. the inherent vowel being substituted by another vowel: क /ki:/,क /qi:/ 2.3. A consonant (with or without Nukta) followed by a modifier: क /k /, ह /hah 24 / 2.4. A consonant (with or without Nukta) followed by a mātrā and a modifier: क /kũ/, द /duh/ A consonant cluster i.e. a half consonant (Consonant+Halanta) followed by a full consonant followed optionally by a mātrā, a modifier or a combination of both. These result in a ligature or what is often termed as sanyuktakshara. त क /tka/ त क /tk /, त क /tkah/ त क /tkũ/, त द /tdu/. The above permutations and combinations result in 7 major akshar types. Of these the last type introduces the problem of the number of consonant clusters. ISCII (91, p.23) provides for up to three consonant clusters as the worst case, i.e. the largest possible string. This is functional for Modern Prakrits where the largest consonantal cluster rarely exceeds three consonant. Sanskrit is an exception where in a single word, five consonants can come together: क त नर यक /kārtsnya/ "wholeness", "entirety" (secondary derivative from the adjective कत न /kṛtsna/ meaning whole, complete.) This means that theoretically the following forms can be postulated: 23 For purposes of Simplification, C here will automatically be treated as being also consonant+nukta: C+ N 24 This character represents phonetically the weak implicit vowel, termed as schwa and often shown as /a/ also. 19
20 1. Vowel Set: With the Vowel as the node. V VD 2. Consonant set: With the Consonant as the node (an implicit or modified vowel is preimplied). Node Mātrā Modifier Mātrā+Modifier C 25 CM CD CMD CHC CHCM CHCD CHCMD CHCHC CHCHCM CHCHCD CHCHCMD CHCHCHC CHCHCHCM CHCHCHCD CHCHCHCM A total number of 16 theoretical syllables is therefore possible. Since the formal structure Devanagari Script behaviour for Hindi of the akshar is common to all Brahmi based scripts, it will not be treated in the sample template, but it will form the basis of an exhaustive description of the characters as well as their ligatural representations. 25 C here will automatically be treated as being also consonant+nukta, C+N to simplify the explanation 20
21 6.3 DEVANAGARI SCRIPT BEHAVIOUR FOR HINDI PROPER This section lays down in detail the different parameters of the Devanagari Script behaviour for Hindi. These are: The Character Set of Hindi The Consonant mātrā combinations of Hindi as well as Vowel and nasal modifier combinations The Ligature Set of Hindi Inventory of Valid and Invalid Combinations with respect to and Collocation Order of Hindi The Character Set of Hindi. This section provides detailed information about the characters in the language and the list of the same and also more importantly shows the manner in which the character is to be written. Each subsection comprises therefore two parts: the basic character set and the shape each character should have, as mandated by the experts, who have designed the Devanagari Script behaviour for Hindi. This comprises the following: The Consonant Set The Vowel Set The Mātrā Set Displaced Catenators Shape of the combination of ra (rakar, repha) The Set of Diacritics Halant Numerals Punctuation marks Other symbols. 26 The shapes provided here are as desired by Central Hindi Directorate. These are provided in Appendix 1 21
22 Each of these will be analyzed in detail: The Consonant Set The Consonant set of Hindi comprises the following characters: A basic Consonant inventory arranged as per their Vargas 27. Laryngeal -vd - asp STOPS NASAL TAP LATERAL FRICATIVE APPROXIMANT -vd +vd +vd +vd +vd +vd -vd +vd +asp - +asp -asp asp Uvular क ग Velar क ख ग घ ङ ख Palatoalveolar श Palatal च छ ज झ ञ र य Retroflex ट ठ ड ढ ण ष Flaps ड़ ढ Dental/ थ द ध न र ल स ज Alveolar 28 Labio- Dental फ Bi-labial प फ ब भ म ह व Note: Ligatures क ष त र ज ञ श र are not listed in the consonants list, since they are ligatures 29 : क ष= क+ +ष, ज ञ =ज+ +ञ,त र =त+ +र,श र =श+ +र. However in standard textbooks as per CBSE syllabus these ligatures are treated as individual consonants and not ligatural forms. The Central Hindi Directorate clearly recommends that these be treated as ligatural forms and not individual consonants. 27 Based on comments and suggestions by Dr Pramod Pandey Professor, Centre for Linguistics, School of Languages, Literature and Culture Studies, Jawaharlal Nehru University to make the chart representative of Modern Hindi.. 28 The two points of articulation are placed together for sake of economy. 29 cf. p 2 and also p.5 of their document. 22
23 The exact shapes as desired by the experts are provided in the table below: Laryngeal -vd - asp Uvular क ग STOPS NASAL TAP LATERAL FRICATIVE APPROXIMANT -vd +vd +vd +vd +vd +vd -vd +vd +asp - +asp -asp asp Velar क ख ग घ ङ ख Palatoalveolar श Palatal च छ ज झ ञ र य Retroflex ट ठ ड ढ ण ष Flaps ड़ ढ Dental/ थ द ध न र ल स ज Alveolar Labio- Dental फ Bi-labial प फ ब भ म ह व 23
24 The Vowel Set The Vowel set of Hindi is as under: Character Unicode code-point Character name अ U+0905 DEVANAGARI LETTER A आ U+0906 DEVANAGARI LETTER AA इ U+0907 DEVANAGARI LETTER I ई U+0908 DEVANAGARI LETTER II उ U+0909 DEVANAGARI LETTER U ऊ U+090A DEVANAGARI LETTER UU ऋ U+090B DEVANAGARI LETTER VOCALIC R ए U+090F DEVANAGARI LETTER E ऍ U+090D DEVANAGARI LETTER CANDRA E ऐ U+0910 DEVANAGARI LETTER AI ओ U+0913 DEVANAGARI LETTER O ऑ U+0911 DEVANAGARI LETTER CANDRA O औ U+0914 DEVANAGARI LETTER AU As per expert recommendations the character set should be written as under: अ आ इ ई उ ऊ ऋ ए ऐ ऍ ओ ऑ औ 24
25 The Mātrā Set The Mātrā 30 (Vowel Sign) of Hindi is as under: Mātrā Names Mātrās Sign Where is it used? Consonant Shapes formed DEVANAGARI VOWEL SIGN AA आ क + आ = क DEVANAGARI VOWEL SIGN I इ क + इ = क DEVANAGARI VOWEL SIGN II ई क + ई = क DEVANAGARI VOWEL SIGN U उ क + उ = क DEVANAGARI VOWEL SIGN UU DEVANAGARI VOWEL SIGN VOCALIC R DEVANAGARI VOWEL SIGN E ऊ ऋ ए क + ऊ = क क + ऋ = क क + ए = क DEVANAGARI VOWEL SIGN CANDRA E DEVANAGARI VOWEL SIGN AI ऍ क + = क ऐ क + ऐ = क DEVANAGARI VOWEL SIGN O ओ क + ओ = क DEVANAGARI VOWEL SIGN CANDRA O DEVANAGARI VOWEL SIGN AU ऑ क + = क औ क + औ = क As per the experts recommendations the character set should be written as under: 30 Allographs 25
26 Displaced Catenators Under normal circumstances Vowel Modifiers also known as catenators (since they concatenate to the preceding consonant) in Brahmi based scripts are written from left to right in linear order (with the exception of Consonant stacks). However, certain modifiers are displaced and are placed to the left of the consonant to which they concatenate. As a general rule in all Devanāgarī script driven languages there is only one displaced catenator: CATENATOR POSITION EXAMPLE To left of character क, र, प Shape of the combination of ra (rakar, repha) The र takes a variety of shapes known as rakar and repha (rafar) depending on its position. When conjoined before a consonant by means of the halanta, it changes shape and is placed on top of the consonant or consonant clusters to which it relates. This is called a repha or rafar. When it is conjoined after a consonant with the help of a halanta, it appends to the consonant in the shape of a slanting stroke attached to the stem (side rakar) or in the case of consonants which have no stem such as ट, it is appended in the shape of a ^ to the bottom of the character (bottom rakar). Hindi has the following combinations of ra: RAFARS Top rafar: क तक e.g. top rafars will be formed in case of following words. धमक, चख RAKARS 1. Bottom rakar ट र ड र 2. Side rakar क र च र 3. Inside rakar ह र Examples of words where Rakars are used in Hindi are given below: Bottom rakar Side rakar Inside rakar ड रम, र ष ट ट र व र, चक र, प रस द,स र ह र व, ह र स 26
27 Diacritics These are as under in the case of Hindi: : - Anuswar र ग : - Candrabindu/Anunasika इ ट - Visarga द ख ऽ: - For extra length with long vowels e.g. / उपद श ऽजन न सक / Halant : - Halant सवत Numerals The international number set (Latino-Arabic set: 0,1,2,3,4,5,6,7,8,9) is used in official documents in Hindi. Following are the numbers used in Hindi. ० १ २ ३ ४ ५ ६ ७ ८ ९ Numeral Explanation Shapes ० Devanāgarī Digit Zero १ Devanāgarī Digit One २ Devanāgarī Digit Two ३ Devanāgarī Digit Three ४ Devanāgarī Digit Four ५ Devanāgarī Digit Five ६ Devanāgarī Digit Six ७ Devanāgarī Digit Seven ८ Devanāgarī Digit Eight ९ Devanāgarī Digit Nine 31 Avagraha is rarely used in Hindi and is used for representing text in Sanskrit here the character is needed.. The example cited is from 27
28 Punctuation Markers 28 Hindi uses punctuation markers from the Latin set. such as., ; : ( ) [ ] etc. However, the abbreviation marker( U+0970) is often used in Devanāgarī Purna and Deergha Virama (full-stop/danda) Devanāgarī code block: U+0964, U+0965,. However, Unicode recognizes these characters as DEVANAGARI DANDA ( ) and DEVANAGARI DOUBLE DANDA ( ). is used to mark the full stop and and are used for poetry written in Chhanda/Doha/Chaupai. The usage of the same is shown in the Doha of Sant Kabir given below च ह मट, चच मट मनव ब परव ह जसक कछ नह च हए वह शह श ह म ट कह क म ह र स, तर य र द म र य इक दन ऐस आएग, म र द ग र य A list of punctuations is provided below: 32 Devanagari Name Name of the marker Marker Shape " ट प" 32 /stop/ U+002E FULL STOP. प रश न चह न U+003F QUESTION MARK? /prashna chihna/ अल प वर म /alpaviram/ व मर यस चक चह न /vismaysuchak chihna/ ऊर धवक अल प वर म /urdhva alpaviram/ अधक वर म /ardhaviram/ उप वर म /upviram/ र य जक चह न /yojak chihna/ नद शक चह न U+002C COMMA, U+0021 EXCLAMATION MARK! U+0027 APOSTROPHE U+003B SEMICOLON ; U+003A COLON : U+002D HYPHEN-MINUS - U+002D HYPHEN-MINUS U+002D HYPHEN- MINUS Dash %E0%A4%9A%E0%A4%BF%E0%A4%A8%E0%A5%8D%E0%A4%B9) --
29 /nirdeshak chihna/ ल प चह न /lop chihna/ उद रण चह न /udharan chihna/ शब द चह न /shabda chihna क ष ट ठक /koshthak/ क ष ट ठक /koshthak/ क ष ट ठक /koshthak/ स क ष पस चक चह न /sankshepsuchak chinha/ प रण वर म /puran viram/ द घक वर म /dirgha viram/ ह सपद / त र टब धक /hanspad trutibodhak/ FULL STOP (U+002E) FULL STOP (U+002E) FULL STOP (U+002E) Elimination Sign U+002F SLASH / U+0022 QUOTATION MARK " " U+0027 APOSTROPHE SINGLE QUOTATION MARK U+0058 LATIN CAPITAL LETTER X used as a cross-out character. U+002D HYPHEN-MINUS U+002D HYPHEN- MINUS U+0022 QUOTATION MARK U+002D HYPHEN-MINUS U+002D HYPHEN-MINUS as above U+0028 LEFT PARENTHESIS U+0029 RIGHT PARENTHESIS U+005B LEFT SQUARE BRACKET U+005D RIGHT SQUARE BRACKET U+007B LEFT CURLY BRACKET U+007D RIGHT CURLY BRACKET U+0970 DEVANAGARI ABBREVIATION SIGN U+0964 DEVANAGARI DANDA Devanāgarī Purna Viram U+0965 DEVANAGARI DOUBLE DANDA Devanāgarī Deergha Viram Sign of left/add word... ' ' X - - " - - ( ) [ ] { } Other Symbols These are religious symbols and currency symbol included in Unicode: ॐ: Om (as written in Hindi) (Unicode code point: 0950) Rupee Sign as mandated by Government of India. (Unicode code point: 20B9) : Right-facing svasti sign (Unicode code point: 0FD5) 29
30 Consonant Mātrā Combinations. These refer to the shapes generated when a Mātrā is adjoined to the Consonant. The layout of these is in the shape of a matrix where the first horizontal row refers to the active consonant and the first vertical column refers to the vowel-modifier. Due to constraints of space and also for reasons of clarity, for each class a series of 3 tables are provided. Table 1: क ख ग घ ङ च छ ज झ ञ Table 2: ट ठ ड ढ ण थ द ध न Table 3: प फ ब भ म र य र ल व श ष स ह Table 4: क ख ग ज फ ड़ ढ All valid as well as invalid combinations have been provided since the primary aim of the document is to ensure that the font developer can develop a valid font based on the combinations. The Devanagari Script Behaviour for Hindi document provides therefore for such combinations which could be termed as dead but which are required by the font developer for developing the font for the particular language. It needs to be noted that the font developer requires to represent within the Open Type Table rules for all characters and even if the combinations of certain characters do not exist in the language, such combinations need to be represented to enable font developers to show the exact representation of these combinations. Such dead combinations may not be valid within the language system but are a precious resource for the font developer and hence have been included. e.g. Although the combination of ङ +Mātrā is theoretically not possible it needs to be handled at the font level in the anticipation that a user could type this combination. The font would show the following: ङ The classes are as under: refers to a simple concatenation of Consonant and Mātrā combinations refers to a concatenation of Consonant and Mātrā + Nasal marker combinations. These are with Anuswara and Candrabindu. Other diacritics such as avagraha and visarga have been avoided, since these are linear in nature, are adjoined to the combination and do not in any way modify the structure of the shapes. 30
31 Consonant and Mātrā combinations. This set refers to a simple concatenation of consonant and mātrā. Consonant and Mātrā combinations Set 1 क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ Remark 1- ङ and ञ are rarely used only as the first members of clusters and mostly as परसवणक or alternatives of अन व र 31
32 Consonant and Mātrā combinations Set 2 This set is in continuation of set 1 which shows consonant and mātrā combinations. ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न 32
33 Consonant and Mātrā combinations Set 3 This set is in continuation of set 2 which shows consonant and mātrā combinations. प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह 33
34 Consonant and Mātrā combinations Set 4 This set is in continuation of set 3 which shows consonant and mātrā combinations for nukta consonants. 33 क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ 34 क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ 33 क़,ग़ were not recognized as part of the consonant set by the Central Hindi Directorate, but have been accepted in its latest version.. 34 This combination is rarely used but still noted as a guide for the font designer. 34
35 Consonant and Mātrā +Nasal combinations. This set refers to a consonant and mātrā + nasal marker combinations. Consonant and Mātrā + Nasal combinations - Set 1 क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ चक चख चग चघ चङ चच चछ चज चझ चञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ 35
36 Consonant and Mātrā +Nasal combinations - Set 2 This set is in continuation of set 1 above which shows combinations of consonant and mātrā + nasal marker ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न चट चठ चड चढ चण च चथ चद चध चन ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न 35 ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न 35, are used only for the purpose of writing loan words mainly from English. However, since such occurrences are rare, the nasal shapes of, are rarely encountered in Hindi. 36
37 Consonant and Mātrā +Nasal combinations - Set 3 This set is in continuation of set 2 above which shows combinations of Consonant and Mātrā + Nasal marker प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह चप चफ चब चभ चम चर य चर चल चव चश चष चस चह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह 36 प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह 36 Since, are used only for the purpose of writing loan words mainly from English. However, since such occurrences are rare, the nasal shapes of, are rarely encountered in Hindi. 37
38 Consonant and Mātrā +Nasal combinations - Set 4 This set is in continuation of set 3 above which shows combinations of Consonant and Mātrā + Nasal marker क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ चक चख चग चज चफ चड़ चढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ 37 क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ 37 Since, are used only for the purpose of writing loan words mainly from English. However, since such occurrences are rare, the nasal shapes of, are rarely encountered in Hindi. 38
39 Consonant and Mātrā + Nasal combinations: With Candrabindu - Set 1 As per rule of the Central Hindi Directorate, Candrabindu cannot be placed over matras which are above the Shirorekha and in this case the Candrabindu is replaced by an Anuswar. This rule could create issues for OCR/OHWR if Chandrabindu is inputted over matras above the shirorekha and is automatically mapped to Anuswar as per the rule above. It is proposed that a Normalisation rule be introduced. In the case of OCR/OHWR which analyse the character at the display level, the combination matra+anuswar will be shown as such. क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ चक चख चग चघ चङ चच चछ चज चझ चञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज क ख ग घ ङ च छ ज क ख ग घ ङ च छ ज क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ क ख ग घ ङ च छ ज झ ञ झ झ झ ञ ञ ञ 39
40 Consonant and Mātrā +Nasal combinations With Candrabindu - Set 2 This set is in continuation of set 1 above which shows combinations of Consonant and Mātrā + Candrabindu. As per rule of the Central Hindi Directorate, Candrabindu cannot be placed over matras which are above the Shirorekha and in this case the Candrabindu is replaced by an Anuswar. ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न चट चठ चड चढ चण च चथ चद चध चन ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण ट ठ ड ढ ण ट ठ ड ढ ण थ थ द ध न द ध न थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न 38 ट ठ ड ढ ण थ द ध न ट ठ ड ढ ण थ द ध न 38 Since, are used only for the purpose of writing loan words mainly from English. However, since such occurrences are rare, the nasal shapes of, are rarely encountered in Hindi. 40
41 Consonant and Mātrā +Nasal combinations With Candrabindu - Set 3 This set is in continuation of set 2 above which shows combinations of Consonant and Mātrā + Candrabindu. As per rule of the Central Hindi Directorate, Candrabindu cannot be placed over matras which are above the Shirorekha and in this case the Candrabindu is replaced by an Anuswar. प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह चप चफ चब चभ चम चर य चर चल चव चश चष चस चह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल प फ ब भ म र य र ल प फ ब भ म र य र ल व श ष स ह व श ष स ह व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह प फ ब भ म र य र ल व श ष स ह 41
42 Consonant and Mātrā +Nasal combinations With Candrabindu - Set 4 This set is in continuation of set 3 above which shows combinations of Consonant and Mātrā + Candrabindu. As per rule of the Central Hindi Directorate, Candrabindu cannot be placed over matras which are above the Shirorekha and in this case the Candrabindu is replaced by an Anuswar. क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ चक चख चग चज चफ चड़ चढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ क ख ग ज फ ड़ ढ 42
43 Vowel+Nasal Combinations: Anuswar and Candrabindu The table below shows the combinations of full vowels with the nasal modifiers: Anuswar and Candrabindu. अ आ इ ई उ ऊ ऋ ऍ ए ऐ ऑ ओ औ अ आ इ ई उ ऊ ऋ ऍ ए ऐ ऑ ओ औ अ आ इ ई उ ऊ ऋ ऍ ए ऐ ऑ ओ औ Consonant and Mātrā combinations for Main Ligatures क ष,ज ञ,त र Although क ष,ज ञ,त र and श र are not consonants per se 39, it was felt that for the font developer all matra combinations with these three ligatural shapes be provided for the font developer. Set 1 Consonant and Mātrā combinations क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र 39 Cf. p
44 Set 2 Consonant and Mātrā + Nasal combinations: with Anuswara क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र चक ष चज ञ चत र चश र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र Set 3 Consonant and Mātrā + Nasal combinations: With Candrabindu As per rule of the Central Hindi Directorate, Candrabindu cannot be placed over matras which are above the Shirorekha and in this case the Candrabindu is replaced by an Anuswar. 44 क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र चक ष चज ञ चत र चश र क ष ज ञ त र श र क ष ज ञ त र क ष ज ञ त र श र क ष ज ञ त र क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र श र श र
45 क ष ज ञ त र श र क ष ज ञ त र श र क ष ज ञ त र श र 45
46 The Ligature Set of Hindi. Hindi has a large set of ligatural forms. These are combinations of Consonant+Halanta+Consonant (CHC) or CHCHC or even rarer CHCHCHC. The CHC combinations which are the most frequent are arranged in the shape of a matrix: the abscissa or horizontal axis refers to the Consonant which constitutes the ligature and the ordinate or vertical axis shows the consonant which forms the ligature and which is followed by a halanta. As in the ligature sets are divided into the following CHC (in a matrix) CHCHC CHCHCHC CHC ( combination of two Consonants) These ligatures are presented as in the earlier case of Consonant+Mātrā combinations in three sets. The following set shows a combination of two consonants. To know how particular combinations forms, select one consonant from the first column and second from first row e.g. Combination of consonant क and क joined by a Halant is the ligature तक 40. CHC( combination of two consonants) - Set 1 क ख ग घ ङ च छ ज झ ञ क तक 41 त ख त ग त घ तङ त च त छ त ज त झ तञ ख ख क ख ख ख ग ख घ ख ङ ख च ख छ ख ज ख झ ख ञ ग ग क ग ख ग ग ग घ ग ङ ग च ग छ ग ज ग झ ग ञ घ र घ क र घ ख र घ ग र घ घ र घङ र घ च र घ छ र घ ज र घ झ र घञ ङ ङ क ङ ख ङ ग ङ घ ङ ङ ङ च ङ छ ङ ज ङ झ ञ ञ च च क च ख च ग च घ च ङ च च च छ च ज च झ च ञ छ छ क छ ख छ ग छ घ छ ङ छ च छ छ छ ज छ झ छ ञ ज ज क ज ख ज ग ज घ ज ङ ज च ज छ ज ज ज झ ज ञ झ झ क झ ख झ ग झ घ झ ङ झ च झ छ झ ज झ झ झ ञ ञ ञ क ञ ख ञ ग ञ घ ञ ङ ञ च ञ छ ञ ज ञ झ ञ ञ ट ट क ट ख ट ग ट घ ट ङ ट च ट छ ट ज ट झ ट ञ 40 ZWJ/ZWNJ are generally not used in Hindi. cf. Annexure 3: Note on ZWJ/ZWNJ in Devanāgarī. 41 Although the Central Hindi Directorate prefers the linear form of the conjunct, the use of i.e. a stacked form is also permissible and is therefore noted as such. 46
47 क ठ ठ क ठ ख ठ ग ठ घ ठ ङ ठ च ठ छ ठ ज ठ झ ठ ञ ड ड क ड ख ड ग ड घ ड ङ ड च ड छ ड ज ड झ ड ञ ढ ढ क ढ ख ढ ग ढ घ ढ ङ ढ च ढ छ ढ ज ढ झ ढ ञ ण ण क ण ख ण ग ण घ ण ङ ण च ण छ ण ज ण झ ण ञ त त क त ख त ग त घ त ङ त च त छ त ज त झ त ञ थ थ क थ ख थ ग थ घ थ ङ थ च थ छ थ ज थ झ थ ञ द द क द ख द ग द घ द ङ द च द छ द ज द झ द ञ ध र ध क र ध ख र ध ग र ध घ र धङ र ध च र ध छ र ध ज र ध झ र धञ न न क न ख न ग न घ नङ न च न छ न ज न झ नञ प प क प ख प ग प घ प ङ प च प छ प ज प झ प ञ फ फ क फ ख फ ग फ घ फ ङ फ च फ छ फ ज फ झ फ ञ ब ब क ब ख ब ग ब घ ब ङ ब च ब छ ब ज ब झ ब ञ भ भ क भ ख भ ग भ घ भ ङ भ च भ छ भ ज भ झ भ ञ म म क म ख म ग म घ म ङ म च म छ म ज म झ म ञ य य क य ख य ग य घ य ङ य च य छ य ज य झ य ञ र खक गक घक ङक चक छक जक झक ञक ल ल क ल ख ल ग ल घ ल ङ ल च ल छ ल ज ल झ ल ञ व व क व ख व ग व घ व ङ व च व छ व ज व झ व ञ श श क श ख श ग श घ श ङ श च श छ श ज श झ श ञ ष ष ट क ष ट ख ष ट ग ष ट घ ष ट ङ ष ट च ष ट छ ष ट ज ष ट झ ष ट ञ स क ख ग घ ङ च छ ज झ ञ ह ह क ह ख ह ग ह घ ह ङ ह च ह छ ह ज ह झ ह ञ क क़ क क़ ख क़ ग क़ घ क़ ङ क़ च क़ छ क़ ज क़ झ क़ ञ ख ख़ क ख़ ख ख़ ग ख़ घ ख़ ङ ख़ च ख़ छ ख़ ज ख़ झ ख़ ञ ग ग़ क ग़ ख ग़ ग ग़ घ ग़ ङ ग़ च ग़ छ ग़ ज ग़ झ ग़ ञ ज ज़ क ज़ ख ज़ ग ज़ घ ज़ ङ ज़ च ज़ छ ज़ ज ज़ झ ज़ ञ फ फ़ क फ़ ख फ़ ग फ़ घ फ़ ङ फ़ च फ़ छ फ़ ज फ़ झ फ़ ञ ड़ ड़ क ड़ ख ड़ ग ड़ घ ड़ ङ ड़ च ड़ छ ड़ ज ड़ झ ड़ ञ ढ ढ क ढ ख ढ ग ढ घ ढ ङ ढ च ढ छ ढ ज ढ झ ढ ञ 47
48 CHC Set 2: The following set shows a combination of two consonants. To know how particular combinations forms, select one consonant from the first column and second from first row e.g. Combination of consonant क and ट is ligature त ट. CHC( combination of two consonants) - Set 2 ट ठ ड ढ ण थ द ध न क त ट त ठ त ड त ढ त ण त त थ त द त ध तन ख ख ट ख ठ ख ड ख ढ ख ण ख ख थ ख द ख ध ख न ग ग ट ग ठ ग ड ग ढ ग ण ग ग थ ग द ग ध ग न घ र घ ट र घ ठ र घ ड र घ ढ र घ ण र घ र घ थ र घ द र घ ध र घन ङ ङ ट ङ ठ ङ ड ङ ढ ङ ण ङ ङ थ ङ द ङ ध ङ न च च ट च ठ च ड च ढ च ण च च थ च द च ध च न छ छ ट छ ठ छ ड छ ढ छ ण छ छ थ छ द छ ध छ न ज ज ट ज ठ ज ड ज ढ ज ण ज ज थ ज द ज ध ज न झ झ ट झ ठ झ ड झ ढ झ ण झ झ थ झ द झ ध झ न ञ ञ ट ञ ठ ञ ड ञ ढ ञ ण ञ ञ थ ञ द ञ ध ञ न ट ट ट ट ड ट ढ ट ण ट ट थ ट द ट ध ट न ठ ठ ट ठ ठ ठ ड ठ ढ ठ ण ठ ठ थ ठ द ठ ध ठ न ड ड ट ड ठ ड ड ड ण ड ड थ ड द ड ध ड न ढ ढ ट ढ ठ ढ ड ढ ढ ढ ण ढ ढ थ ढ द ढ ध ढ न ण ण ट ण ठ ण ड ण ढ ण ण ण ण थ ण द ण ध ण न त त ट त ठ त ड त ढ त ण त त त थ त द त ध त न थ थ ट थ ठ थ ड थ ढ थ ण थ थ थ थ द थ ध थ न द द ट द ठ द ड द ढ द ण द द थ द द द न ध र ध ट र ध ठ र ध ड र ध ढ र ध ण र ध र ध थ र ध द र ध ध र धन न न ट न ठ न ड न ढ न ण न न थ न द न ध न न प प ट प ठ प ड प ढ प ण प प थ प द प ध प न फ फ ट फ ठ फ ड फ ढ फ ण फ फ थ फ द फ ध फ न 48
49 ब ब ट ब ठ ब ड ब ढ ब ण ब ब थ ब द ब ध ब न भ भ ट भ ठ भ ड भ ढ भ ण भ भ थ भ द भ ध भ न म म ट म ठ म ड म ढ म ण म म थ म द म ध म न य य ट य ठ य ड य ढ य ण य य थ य द य ध य न र टक ठक डक ढक णक क थक दक धक नक ल ल ट ल ठ ल ड ल ढ ल ण ल ल थ ल द ल ध ल न व व ट व ठ व ड व ढ व ण व व थ व द व ध व न श श ट श ठ श ड श ढ श ण श श थ श द श ध श न ष ष ट ट ष ट ठ ष ट ड ष ट ढ ष ट ण ष ट ष ट थ ष ट द ष ट ध ष ट न स ट ठ ड ढ ण थ द ध न ह ह ट ह ठ ह ड ह ढ ह ण ह ह थ ह द ह ध ह न क क़ ट क़ ठ क़ ड क़ ढ क़ ण क़ क़ थ क़ द क़ ध क़ न ख ख़ ट ख़ ठ ख़ ड ख़ ढ ख़ ण ख़ ख़ थ ख़ द ख़ ध ख़ न ग ग़ ट ग़ ठ ग़ ड ग़ ढ ग़ ण ग़ ग़ थ ग़ द ग़ ध ग़ न ज ज़ ट ज़ ठ ज़ ड ज़ ढ ज़ ण ज़ ज़ थ ज़ द ज़ ध ज़ न फ फ़ ट फ़ ठ फ़ ड फ़ ढ फ़ ण फ़ फ़ थ फ़ द फ़ ध फ़ न ड़ ड़ ट ड़ ठ ड़ ड ड़ ढ ड़ ण ड़ ड़ थ ड़ द ड़ ध ड़ न ढ ढ ट ढ ठ ढ ड ढ ढ ढ ण ढ ढ थ ढ द ढ ध ढ न 49
50 CHC SET 3: The following set shows a combination of two consonants. To know how a particular combinations forms, select one consonant from the first column and second from first row e.g. Combination of consonant क and प is the ligature त प. CHC( combination of two consonants) - Set 3 प फ ब भ म र य र ल व श ष स ह क त प त फ त ब त भ त म त र य क र तल त व तश क ष त स त ह ख ख प ख फ ख ब ख भ ख म ख र य ख र ख ल ख व ख श ख ष ख स ख ह ग ग प ग फ ग ब ग भ ग म ग र य ग र ग ल ग व ग श ग ष ग स ग ह घ र घ प र घ फ र घ ब र घ भ र घ म र घ र य घ र र घल र घ व र घ श र घ ष र घ स र घ ह ङ ङ प ङ फ ङ ब ङ भ ङ म ङ र य ङ र ङ ल ङ व ङ श ङ ष ङ स ङ ह च च प च फ च ब च भ च म च र य च र च ल च व च श च ष च स च ह छ छ प छ फ छ ब छ भ छ म छ र य छर छ ल छ व छ श छ ष छ स छ ह ज ज प ज फ ज ब ज भ ज म ज र य ज र ज ल ज व ज श ज ष ज स ज ह झ झ प झ फ झ ब झ भ झ म झ र य झ र झ ल झ व झ श झ ष झ स झ ह ञ ञ प ञ फ ञ ब ञ भ ञ म ञ र य ञ र ञ ल ञ व ञ श ञ ष ञ स ञ ह ट ट प ट फ ट ब ट भ ट म ट य ट र ट ल ट व ट श ट ष ट स ट ह ठ ठ प ठ फ ठ ब ठ भ ठ म ठ य ठ र ठ ल ठ व ठ श ठ ष ठ स ठ ह ड ड प ड फ ड ब ड भ ड म ड य ड र ड ल ड व ड श ड ष ड स ड ह ढ ढ प ढ फ ढ ब ढ भ ढ म ढ य ढ र ढ ल ढ व ढ श ढ ष ढ स ढ ह ण ण प ण फ ण ब ण भ ण म ण र य णर ण ल ण व ण श ण ष ण स ण ह त त प त फ त ब त भ त म त र य त र त ल त व त श त ष त स त ह थ थ प थ फ थ ब थ भ थ म थ र य थ र थ ल थ व थ श थ ष थ स थ ह द द प द फ द ब द भ द द द र द ल द व द श द ष द स द ह ध र ध प र ध फ र ध ब र ध भ र ध म र ध र य ध र र धल र ध व र धश र ध ष र ध स र ध ह न न प न फ न ब न भ न म न र य न र नल न व नश न ष न स न ह प प प प फ प ब प भ प म प र य प र प ल प व प श प ष प स प ह फ फ प फ फ फ ब फ भ फ म फ र य फ र फ ल फ व फ श फ ष फ स फ ह 50
51 ब ब प ब फ ब ब ब भ ब म ब र य ब र ब ल ब व ब श ब ष ब स ब ह भ भ प भ फ भ ब भ भ भ म भ र य भ र भ ल भ व भ श भ ष भ स भ ह म म प म फ म ब म भ म म म र य म र म ल म व म श म ष म स म ह य य प य फ य ब य भ य म य र य य र य ल य व य श य ष य स य ह र पक फक बक भक मक र यक रक लक वक शक षक सक हक ल ल प ल फ ल ब ल भ ल म ल र य लर ल ल ल व ल श ल ष ल स ल ह व व प व फ व ब व भ व म व र य व र व ल व व व श व ष व स व ह श श प श फ श ब श भ श म श र य श र 42 श ल श व श श श ष श स श ह ष ष ट प ष ट फ ष ट ब ष ट भ ष ट म ष ट र य ष ट र ष ट ल ष ट व ष ट श ष ट ष ष ट स ष ट ह स प फ ब भ म र य स र ल व श ष स ह ह ह प ह फ ह ब ह भ ह म ह र य ह र ह ल ह व ह श ह ष ह स ह ह क क़ प क़ फ क़ ब क़ भ क़ म क़ र य क़ र क़ ल क़ व क़ श क़ ष क़ स क़ ह ख ख़ प ख़ फ ख़ ब ख़ भ ख़ म ख़ र य ख़ र ख़ ल ख़ व ख़ श ख़ ष ख़ स ख़ ह ग ग़ प ग़ फ ग़ ब ग़ भ ग़ म ग़ र य ग़ र ग़ ल ग़ व ग़ श ग़ ष ग़ स ग़ ह ज ज़ प ज़ फ ज़ ब ज़ भ ज़ म ज़ र य ज़ र ज़ ल ज़ व ज़ श ज़ ष ज़ स ज़ ह फ फ़ प फ़ फ फ़ ब फ़ भ फ़ म फ़ र य फ़ र फ़ ल फ़ व फ़ श फ़ ष फ़ स फ़ ह ड़ ड़ प ड़ फ ड़ ब ड़ भ ड़ म ड़ र य ड़र ड़ ल ड़ व ड़ श ड़ ष ड़ स ड़ ह ढ ढ प ढ फ ढ ब ढ भ ढ म ढ र य ढ र ढ ल ढ व ढ श ढ ष ढ स ढ ह 42 An important combination very often mistyped is श+ = श which is often written as श+Halant+र+ = श र. Thus श ग र is wrongly written as श र ग र. 51
52 CHC SET 4: The following set shows a combination of two consonants of which the second form is the nukta. To know how particular combinations form, select one consonant from the first column and second from first row e.g. The combination of consonants क and क़ is ligature तक. 52 CHC Set 4 क ख ग ज फ ड़ ढ क तक तख तग तज तफ तड़ तढ ख ख क ख ख ख ग ख ज ख फ ख ड़ ख ढ ग ग क ग ख ग ग ग ज ग फ ग ड़ ग ढ घ र घक र घख र घग र घज र घफ र घड़ र घढ ङ ङ क ङ ख ङ ग ङ ज ङ फ ङ ड़ ङ ढ च च क च ख च ग च ज च फ च ड़ च ढ छ छ क छ ख छ ग छ ज छ फ छ ड़ छ ढ ज ज क ज ख ज ग ज ज ज फ ज ड़ ज ढ झ झ क झ ख झ ग झ ज झ फ झ ड़ झ ढ ञ ञ क ञ ख ञ ग ञ ज ञ फ ञ ड़ ञ ढ ट ट क ट ख ट ग ट ज ट फ ट ड़ ट ढ ठ ठ क ठ ख ठ ग ठ ज ठ फ ठ ड़ ठ ढ ड ड क ड ख ड ग ड ज ड फ ड ड़ ड ढ ढ ढ क ढ ख ढ ग ढ ज ढ फ ढ ड़ ढ ढ ण ण क ण ख ण ग ण ज ण फ ण ड़ ण ढ त त क त ख त ग त ज त फ त ड़ त ढ थ थ क थ ख थ ग थ ज थ फ थ ड़ थ ढ द द क द ख द ग द ज द फ द ड़ द ढ ध र धक र धख र धग र धज र धफ र धड़ र धढ न नक नख नग नज नफ नड़ नढ प प क प ख प ग प ज प फ प ड़ प ढ फ फ क फ ख फ ग फ ज फ फ फ ड़ फ ढ
53 ब ब क ब ख ब ग ब ज ब फ ब ड़ ब ढ भ भ क भ ख भ ग भ ज भ फ भ ड़ भ ढ म म क म ख म ग म ज म फ म ड़ म ढ य य क य ख य ग य ज य फ य ड़ य ढ र क क ख क ग क ज क फ क ड़क ढ क ल ल क ल ख ल ग ल ज ल फ ल ड़ ल ढ व व क व ख व ग व ज व फ व ड़ व ढ श श क श ख श ग श ज श फ श ड़ श ढ ष ष ट क ष ट ख ष ट ग ष ट ज ष ट फ ष ट ड़ ष ट ढ स क ख ग ज फ ड़ ढ ह ह क ह ख ह ग ह ज ह फ ह ड़ ह ढ क क़ क क़ ख क़ ग क़ ज क़ फ क़ ड़ क़ ढ ख ख़ क ख़ ख ख़ ग ख़ ज ख़ फ ख़ ड़ ख़ ढ ग ग़ क ग़ ख ग़ ग ग़ ज ग़ फ ग़ ड़ ग़ ढ ज ज़ क ज़ ख ज़ ग ज़ ज ज़ फ ज़ ड़ ज़ ढ फ फ़ क फ़ ख फ़ ग फ़ ज फ़ फ फ़ ड़ फ़ ढ ड़ ड़ क ड़ ख ड़ ग ड़ ज ड़ फ ड़ ड़ ड़ ढ ढ ढ क ढ ख ढ ग ढ ज ढ फ ढ ड़ ढ ढ 53
54 CHCHC ( combination of three Consonants) These are not as frequent as the CHC combinations. Only the major are listed below. With a few exceptions these are mainly linear in nature. A majority of these are due to loan words which have entered Hindi. Combinations with mātrās have not been taken into account Quite a few examples are culled from Bahri and Nalanda Dictionaries. Others are taken form the CIIL corpus. 54
55 CHCHC Example तक ष द तक ष प तट र इल तट र न तट स प तट स तत र य र य तत र य भ स तत र प चवतत र तत व प थतत व तप र व तप र द तल र य श तल र य क ष ण क ष ण क ष म भ ग र यलक ष म क ष र य अनप क ष र य क ष व इक ष व क त ड फत ड त व त भ त व व त व त र र य ख व व ख व व ज ग ग र व णग ग र म ग ज र य प र ग ज र य ष ग द व प र ग द व र ग नर य अग नर य ध न ग भ र दग भ रम ग व र य व ग व र यवह र च छ व उच छ व स ज ज व उज ज वल त तल त क ष त त थ त त व त प र त प ल त म र य त र र य त थ त न त प त प त फ त र य त व द ग र द ज ञ द द व द द ष द भ र द र र य द व र य नतव नट र नट स उत तल श त क ष णक स प क त त थ त त व उत प र रक उत प लव थ नमह त म र य व चत र र य त थ न र य ज त न ईषत प ष ट ट ह त प द उत फ क मत र य त वर प उद ग र व सद ज ञ न ए द द व र न म क द द ष ट ट उद भ रम द रद र र य सद व र यवह र इनतव र यर इनफ क नट रर य ट डनट स 55
56 नत र य अ चनत र य ट सक प ट सकम न नत र उप-मनत र ण र यक वण र यक नद अ ननद त र यक अ मत र यक नद र अ रक षकनद र त रक स त रक नद र उप नद रन थ त सक वत सक नर धर य फलवनर धर य थ र यक स मथ र य ननर य व भननर य द क आद क नफ र क नफ र स द क स ह द क प त र य प र प त र य श द रक आद रक फ ट स एर यरक र फ ट स द वक अ द वक द व 45 ब ज र य क ब ज र य 44 र धदक प व र धदक म म र सम म र ज र धर यक अ र धर य न तर यक सतर य कलर र धवक उर धवक क रक अ र क रक रर य प र यक समप र यक तसक म तसकव द प रक अ प र द शक ख र यक म ख र यक फ र यक कफ र य क ग र यक वग र यक भ रक नभ र ग रक अ ग रक म र यक हम र यक र घर यक अर घर यक ल डक फ र वल डक च छक म र च च छ ल सक च ल सक च र यक अच र यक व र यक ब हव र यकसन ज ञक अ ज ञ न व रक नव रकण ज र यक वज र यक श वक प श वक ट रक प ट र ट 45 अ तर द व र दव. मनस त प - mental agony Arvind 44 Sanskrit loan.: A hump-backed bull cf. 56 Lexicon.
57 ष ट णक क ष ट णक ष ट ण र य व ष ट ण र य ष ट र यक ईष ट र य ष ट प र नष ट प रर य जन टक फ टक क र क क रप ट ल तर य र य ज ञवल तर य तव म तव ल ट र प ल ट र फ मक तव तव ड रन ल ड र चल ड रन ट र इडक ट रर यल ल प र य प रकल प र य त र य अग त र य ल भ र य प र गल भ र य त र अध व त र श व र प रप श व रक त व अ त वच ष ट क र नक ष ट क रर य थ र य व थ र य ष ट तव नष ट तव थ प र स प प रग ष ट ट य उक त व शष ट ट य प ल ए प ल न ड ष ट ट र अ रर ष ट ट र र य द व र सद व र ष ट ठ य ओष ट ठ र य 57
58 CHCHCHC ( Combination of four Consonants) These combinations are rare and found only in the following case 46 : त र र य त र र य ज व CHCHCHCHC ( Combination of five Consonants) Apart from the Sanskrit क त नर यक no other case of a five consonant cluster seems to exist. 46 The examples are culled from Bahri and Nalanda Dictionaries. 58
59 Valid Combinations And Invalid Combinations As mentioned in the Introduction as well as Section 1. End Users of the Devanagari Script behaviour for Hindi (cf. supra), the document targets basically the font designer desirous of knowing the exact shapes both of individual characters as well as combinations such as Consonant-Mātrā, Consonant-Mātrā-Nasal, Consonant+Halant+Consonant, Consonant+Halant+Consonant+Halant+Consonant. It has been therefore decided to display all and every combination both valid and invalid in the document. 59
60 6.3.5 The Collation Order of Hindi. Collation is one of the most important features of this document. It determines the order in which a given culture indexes its characters. This is best seen in a dictionary sort where for easy search words are sorted and arranged in a specific order. Within a given script, each allo-script may have a different sort-order. Thus in Hindi the conjunct glyph क ष is sorted along with क, since the first letter of that conjunct is क and on a similar principle ज ञ is sorted along with ज. The same is not the case with Marathi and Nepali which admit a different sort order. Different scripts admit different sort orders and for all high-end NLP applications, sort is a crucial feature to ensure that the applications index data as per the cultural perception of that community. In quite a few States, sort order is clearly defined by the statutory bodies of that state and hence it is crucial that such sort order be ascertained and introduced in the document. In the case of Hindi the following is the traditional sort order as determined by the experts and used in dictionaries. अ आ इ ई उ ऊ ऋ ए ऍ 47 ऐ ओ ऑ औ क ख ग घ ङ च छ ज झ ञ ट ठ ड ढ ण थ द ध न प फ ब भ म र य र ल व श ष स ह The order as given below is pertinent to sorting by a computer program and is compliant with CLDR as laid down by Unicode and W3C. अ आ इ ई उ ऊ ऋ ए ऍ ऐ ओ ऑ औ क ख ग घ ङ च छ ज झ ञ ट ठ ड ढ ण थ द ध न प फ ब भ म र य र ल व श ष स ह 47 ऍ and ऑ are normally not listed in traditional dictionaries, but are included as digital dictionaries do include these characters. 60
61 In Tabular format: अ आ इ ई उ ऊ ऋ ए ऍ ऐ ओ ऑ औ क ख ग घ ङ च छ ज झ ञ ट ठ ड ढ ण थ द ध न प फ ब भ म र य र ल व श ष स ह Following is the example of sort order for consonant क 48 क क क क क क क क क क क क क क क क क क 48 क is placed at the top of the sort table since it constitutes an akshar by itself. The other combinations listed after the consonant constitute matra or diacritic combinations. 61
62 7. REFERENCES INDIAN SCRIPT CODE FOR INFORMATION INTERCHANGE - ISCII IS NEW DELHI 3. क द र र य चहद नद श लर य: द वन गर ल प थ चहद व कन क म नक करण नई दल ल Omkar N Koul Modern Hindi Grammar. Hyattsville: Dunwoody Press, 2008, pp. x Yamuna Kachru. Hindi. London Oriental and African Language Library, xxii, pp Kalyan Kale, Anjali Soman. Learning Marathi 1st ed. Shri Vishakha Prakashan,
63 8. ANNEXURES Annexure I : Names of experts who have redrafted the document based on inputs of the committee Prepared by : Dr. Raiomond Doctor, Consultant, C-DAC, GIST, Pune Shapes in this documents are based on CHD book Inputs by : Mr. Prabhakar Pandey, Hindi Officer, C-DAC, Pune Mr. Tukaram Patil, Department of Hindi, University of Pune Dr. Sudhir Mishra, Hindi Linguist, C-DAC, Pune Hindi Language Expert nominated by Director, CIIL The first meeting of the Expert Committee on Linguistic Resources and Language Technology Standards for Validation of Hindi Script Grammar was held at DeitY on 12th Oct, 2012, under the chairmanship of Ms. Swaran Lata, HoD (HCC). The list of participants : S. No. Name Organization Mobile 1. Ms. Swaran Lata DeitY slata@mit.gov.in 2. Dr. Mukul Kumar Sinha 3. Prof. Panchanan Mohanty Expert Software consultants University of Hyderabad 4. Prof. B. Mallikarjun Central University or Karnataka 5. Prof. Ghanashyam Nepal 6. Sh. Atiur Rahman Khan 7. Sh. Prabhakar Pandey 8. Prof. Hidam Dolen Singh 9. Dr. Bhaskarjyoti Sarma University of North Bengal mukuls@yahoo.co.in panchananmotianty@gmail.com mallikarjun56@gmail.com nepalgs@gmail.com CDAC, Pune atiurk@gmail.com CDAC, Pune prabhakarp@cdac.in NERLC dikebgu@gmail.com Dibrugarh University bhasdu08@gmail.com 10. Sh. J.Kumar NIC Delhi kendolji@nic.in 11. Prof. Bisweswar Basumatary Bodo Sahitya Sabha bssjb@rediffmail.com 63
64 12. Sh. Manoj Jain DeitY Sh. Deepak Pandey CHD Ms. Nutan Pandey CHD Ms. Richa LDC-IL, CIIL Mysore Prof. Girish Nath Jha JNU Dr. Sudhir K. Mishra CDAC, Pune Sh Pravin Satpute Redhat Prof K. K.Goswami Retd Dr. Saurobh Gupta NIC Sh R.K. Pathak CTB, DOL, MHA Sh. Kewal Krishan NIC, D/O official language 23. Sh. Harinder Kumar DOL, MHA Sh. Vijay Kumar DeitY, Delhi Sh. M D Kulkarni CDAC, Pune mdk@cdac.in 26. Sh. Jasjit Singh CDAC jasjit@cdac.in 27. Sh. Naitik Tyagi W3C tyagi@w3.org 28. Ms. Tanushree Ojha W3C tanu.ojha@gmail.com 29. Prof. N Pramodni Devi 30. Prof. Shikhar Kumar Sharma 31. Prof. V R Jagannathan 32. Prof. Pushpak Bhattatacharya Manipur University Gauhati University npdini@yahoo.co.in sks001@gmail.com Retd vrj.nathan@gmail.com IITB, Mumbai pb@cse.iitb.ac.in 33. Ms. Kiran singh CDAC, Delhi kirans@cdac.in 34. Sh. Abhijit Bhattacharjee Luna Ergonomics abhijit@paninikeyped.com 64



65 Annexure 2: Shapes of Hindi characters as per Central Hindi Directorate Hindi Vowels Hindi Vowel Modifiers: Mātrās Hindi Diacritics and Rafar(Repha) Rakar 65

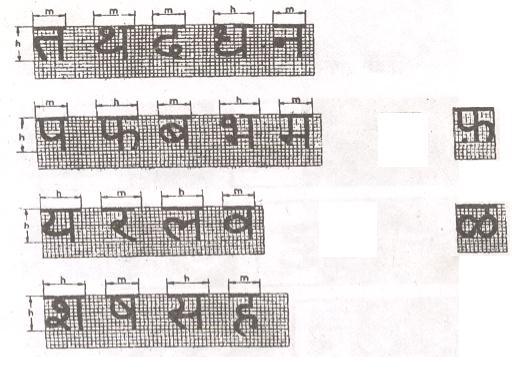
66 Hindi Consonants Ligatural Representations 66
DCA प रय जन क य म ग नद शक द र श नद श लय मह म ग ध अ तरर य ह द व व व लय प ट ह द व व व लय, ग ध ह स, वध (मह र ) DCA-09 Project Work Handbook
 DCA-09 Project Work Handbook") मह म ग ध अ तरर य ह द व व व लय (स सद र प रत अ ध नयम 1997, म क 3 क अ तगत थ पत क य व व व लय) Mahatma Gandhi Antarrashtriya Hindi Vishwavidyalaya (A Central University Established by Parliament by Act No.
मह म ग ध अ तरर य ह द व व व लय (स सद र प रत अ ध नयम 1997, म क 3 क अ तगत थ पत क य व व व लय) Mahatma Gandhi Antarrashtriya Hindi Vishwavidyalaya (A Central University Established by Parliament by Act No.
S. RAZA GIRLS HIGH SCHOOL
 S. RAZA GIRLS HIGH SCHOOL SYLLABUS SESSION 2017-2018 STD. III PRESCRIBED BOOKS ENGLISH 1) NEW WORLD READER 2) THE ENGLISH CHANNEL 3) EASY ENGLISH GRAMMAR SYLLABUS TO BE COVERED MONTH NEW WORLD READER THE
S. RAZA GIRLS HIGH SCHOOL SYLLABUS SESSION 2017-2018 STD. III PRESCRIBED BOOKS ENGLISH 1) NEW WORLD READER 2) THE ENGLISH CHANNEL 3) EASY ENGLISH GRAMMAR SYLLABUS TO BE COVERED MONTH NEW WORLD READER THE
क त क ई-व द य लय पत र क 2016 KENDRIYA VIDYALAYA ADILABAD
 क त क ई-व द य लय पत र क 2016 KENDRIYA VIDYALAYA ADILABAD FROM PRINCIPAL S KALAM Dear all, Only when one is equipped with both, worldly education for living and spiritual education, he/she deserves respect
क त क ई-व द य लय पत र क 2016 KENDRIYA VIDYALAYA ADILABAD FROM PRINCIPAL S KALAM Dear all, Only when one is equipped with both, worldly education for living and spiritual education, he/she deserves respect
HinMA: Distributed Morphology based Hindi Morphological Analyzer
 HinMA: Distributed Morphology based Hindi Morphological Analyzer Ankit Bahuguna TU Munich ankitbahuguna@outlook.com Lavita Talukdar IIT Bombay lavita.talukdar@gmail.com Pushpak Bhattacharyya IIT Bombay
HinMA: Distributed Morphology based Hindi Morphological Analyzer Ankit Bahuguna TU Munich ankitbahuguna@outlook.com Lavita Talukdar IIT Bombay lavita.talukdar@gmail.com Pushpak Bhattacharyya IIT Bombay
 वण म गळ ग र प ज http://www.mantraaonline.com/ वण म गळ ग र प ज Check List 1. Altar, Deity (statue/photo), 2. Two big brass lamps (with wicks, oil/ghee) 3. Matchbox, Agarbatti 4. Karpoor, Gandha Powder,
वण म गळ ग र प ज http://www.mantraaonline.com/ वण म गळ ग र प ज Check List 1. Altar, Deity (statue/photo), 2. Two big brass lamps (with wicks, oil/ghee) 3. Matchbox, Agarbatti 4. Karpoor, Gandha Powder,
Question (1) Question (2) RAT : SEW : : NOW :? (A) OPY (B) SOW (C) OSZ (D) SUY. Correct Option : C Explanation : Question (3)
 Question (2) RAT : SEW : : NOW :? (A) OPY (B) SOW (C) OSZ (D) SUY. Correct Option : C Explanation : Question (3)") Question (1) Correct Option : D (D) The tadpole is a young one's of frog and frogs are amphibians. The lamb is a young one's of sheep and sheep are mammals. Question (2) RAT : SEW : : NOW :? (A) OPY (B)
Question (1) Correct Option : D (D) The tadpole is a young one's of frog and frogs are amphibians. The lamb is a young one's of sheep and sheep are mammals. Question (2) RAT : SEW : : NOW :? (A) OPY (B)
ह द स ख! Hindi Sikho!
 ह द स ख! Hindi Sikho! by Shashank Rao Section 1: Introduction to Hindi In order to learn Hindi, you first have to understand its history and structure. Hindi is descended from an Indo-Aryan language known
ह द स ख! Hindi Sikho! by Shashank Rao Section 1: Introduction to Hindi In order to learn Hindi, you first have to understand its history and structure. Hindi is descended from an Indo-Aryan language known
ENGLISH Month August
 ENGLISH 2016-17 April May Topic Literature Reader (a) How I taught my Grand Mother to read (Prose) (b) The Brook (poem) Main Course Book :People Work Book :Verb Forms Objective Enable students to realise
ENGLISH 2016-17 April May Topic Literature Reader (a) How I taught my Grand Mother to read (Prose) (b) The Brook (poem) Main Course Book :People Work Book :Verb Forms Objective Enable students to realise
Consonants: articulation and transcription
 Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
Phonology 1: Handout January 20, 2005 Consonants: articulation and transcription 1 Orientation phonetics [G. Phonetik]: the study of the physical and physiological aspects of human sound production and
CAAP. Content Analysis Report. Sample College. Institution Code: 9011 Institution Type: 4-Year Subgroup: none Test Date: Spring 2011
 CAAP Content Analysis Report Institution Code: 911 Institution Type: 4-Year Normative Group: 4-year Colleges Introduction This report provides information intended to help postsecondary institutions better
CAAP Content Analysis Report Institution Code: 911 Institution Type: 4-Year Normative Group: 4-year Colleges Introduction This report provides information intended to help postsecondary institutions better
OCR for Arabic using SIFT Descriptors With Online Failure Prediction
 OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
OCR for Arabic using SIFT Descriptors With Online Failure Prediction Andrey Stolyarenko, Nachum Dershowitz The Blavatnik School of Computer Science Tel Aviv University Tel Aviv, Israel Email: stloyare@tau.ac.il,
Arabic Orthography vs. Arabic OCR
 Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
Arabic Orthography vs. Arabic OCR Rich Heritage Challenging A Much Needed Technology Mohamed Attia Having consistently been spoken since more than 2000 years and on, Arabic is doubtlessly the oldest among
The Prague Bulletin of Mathematical Linguistics NUMBER 95 APRIL
 The Prague Bulletin of Mathematical Linguistics NUMBER 95 APRIL 2011 33 50 Machine Learning Approach for the Classification of Demonstrative Pronouns for Indirect Anaphora in Hindi News Items Kamlesh Dutta
The Prague Bulletin of Mathematical Linguistics NUMBER 95 APRIL 2011 33 50 Machine Learning Approach for the Classification of Demonstrative Pronouns for Indirect Anaphora in Hindi News Items Kamlesh Dutta
Phonological Processing for Urdu Text to Speech System
 Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Phonological Processing for Urdu Text to Speech System Sarmad Hussain Center for Research in Urdu Language Processing, National University of Computer and Emerging Sciences, B Block, Faisal Town, Lahore,
Dickinson ISD ELAR Year at a Glance 3rd Grade- 1st Nine Weeks
 3rd Grade- 1st Nine Weeks R3.8 understand, make inferences and draw conclusions about the structure and elements of fiction and provide evidence from text to support their understand R3.8A sequence and
3rd Grade- 1st Nine Weeks R3.8 understand, make inferences and draw conclusions about the structure and elements of fiction and provide evidence from text to support their understand R3.8A sequence and
HISTORY COURSE WORK GUIDE 1. LECTURES, TUTORIALS AND ASSESSMENT 2. GRADES/MARKS SCHEDULE
 HISTORY COURSE WORK GUIDE 1. LECTURES, TUTORIALS AND ASSESSMENT Lectures and Tutorials Students studying History learn by reading, listening, thinking, discussing and writing. Undergraduate courses normally
HISTORY COURSE WORK GUIDE 1. LECTURES, TUTORIALS AND ASSESSMENT Lectures and Tutorials Students studying History learn by reading, listening, thinking, discussing and writing. Undergraduate courses normally
CROSS LANGUAGE INFORMATION RETRIEVAL: IN INDIAN LANGUAGE PERSPECTIVE
 CROSS LANGUAGE INFORMATION RETRIEVAL: IN INDIAN LANGUAGE PERSPECTIVE Pratibha Bajpai 1, Dr. Parul Verma 2 1 Research Scholar, Department of Information Technology, Amity University, Lucknow 2 Assistant
CROSS LANGUAGE INFORMATION RETRIEVAL: IN INDIAN LANGUAGE PERSPECTIVE Pratibha Bajpai 1, Dr. Parul Verma 2 1 Research Scholar, Department of Information Technology, Amity University, Lucknow 2 Assistant
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches
 NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
NCU IISR English-Korean and English-Chinese Named Entity Transliteration Using Different Grapheme Segmentation Approaches Yu-Chun Wang Chun-Kai Wu Richard Tzong-Han Tsai Department of Computer Science
Senior Stenographer / Senior Typist Series (including equivalent Secretary titles)
") New York State Department of Civil Service Committed to Innovation, Quality, and Excellence A Guide to the Written Test for the Senior Stenographer / Senior Typist Series (including equivalent Secretary
New York State Department of Civil Service Committed to Innovation, Quality, and Excellence A Guide to the Written Test for the Senior Stenographer / Senior Typist Series (including equivalent Secretary
Proof Theory for Syntacticians
 Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Department of Linguistics Ohio State University Syntax 2 (Linguistics 602.02) January 5, 2012 Logics for Linguistics Many different kinds of logic are directly applicable to formalizing theories in syntax
Detection of Multiword Expressions for Hindi Language using Word Embeddings and WordNet-based Features
 Detection of Multiword Expressions for Hindi Language using Word Embeddings and WordNet-based Features Dhirendra Singh Sudha Bhingardive Kevin Patel Pushpak Bhattacharyya Department of Computer Science
Detection of Multiword Expressions for Hindi Language using Word Embeddings and WordNet-based Features Dhirendra Singh Sudha Bhingardive Kevin Patel Pushpak Bhattacharyya Department of Computer Science
Word Stress and Intonation: Introduction
 Word Stress and Intonation: Introduction WORD STRESS One or more syllables of a polysyllabic word have greater prominence than the others. Such syllables are said to be accented or stressed. Word stress
Word Stress and Intonation: Introduction WORD STRESS One or more syllables of a polysyllabic word have greater prominence than the others. Such syllables are said to be accented or stressed. Word stress
Opportunities for Writing Title Key Stage 1 Key Stage 2 Narrative
 English Teaching Cycle The English curriculum at Wardley CE Primary is based upon the National Curriculum. Our English is taught through a text based curriculum as we believe this is the best way to develop
English Teaching Cycle The English curriculum at Wardley CE Primary is based upon the National Curriculum. Our English is taught through a text based curriculum as we believe this is the best way to develop
Problems of the Arabic OCR: New Attitudes
 Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
Problems of the Arabic OCR: New Attitudes Prof. O.Redkin, Dr. O.Bernikova Department of Asian and African Studies, St. Petersburg State University, St Petersburg, Russia Abstract - This paper reviews existing
1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature
 August/September Strand Topic Standard Notes Reading for Literature") 1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
1 st Grade Curriculum Map Common Core Standards Language Arts 2013 2014 1 st Quarter (September, October, November) August/September Strand Topic Standard Notes Reading for Literature Key Ideas and Details
STUDENT MOODLE ORIENTATION
 BAKER UNIVERSITY SCHOOL OF PROFESSIONAL AND GRADUATE STUDIES STUDENT MOODLE ORIENTATION TABLE OF CONTENTS Introduction to Moodle... 2 Online Aptitude Assessment... 2 Moodle Icons... 6 Logging In... 8 Page
BAKER UNIVERSITY SCHOOL OF PROFESSIONAL AND GRADUATE STUDIES STUDENT MOODLE ORIENTATION TABLE OF CONTENTS Introduction to Moodle... 2 Online Aptitude Assessment... 2 Moodle Icons... 6 Logging In... 8 Page
DEPARTMENT OF EXAMINATIONS, SRI LANKA GENERAL CERTIFICATE OF EDUCATION (ADVANCED LEVEL) EXAMINATION - AUGUST 2016
 EXAMINATION - AUGUST 2016") DEPARTMENT OF EXAMINATIONS, SRI LANKA GENERAL CERTIFICATE OF EDUCATION (ADVANCED LEVEL) EXAMINATION - AUGUST 2016 Applications of private candidates for the above examination will be received from 01.02.2016
DEPARTMENT OF EXAMINATIONS, SRI LANKA GENERAL CERTIFICATE OF EDUCATION (ADVANCED LEVEL) EXAMINATION - AUGUST 2016 Applications of private candidates for the above examination will be received from 01.02.2016
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers
 Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Speech Recognition using Acoustic Landmarks and Binary Phonetic Feature Classifiers October 31, 2003 Amit Juneja Department of Electrical and Computer Engineering University of Maryland, College Park,
Timeline. Recommendations
 Introduction Advanced Placement Course Credit Alignment Recommendations In 2007, the State of Ohio Legislature passed legislation mandating the Board of Regents to recommend and the Chancellor to adopt
Introduction Advanced Placement Course Credit Alignment Recommendations In 2007, the State of Ohio Legislature passed legislation mandating the Board of Regents to recommend and the Chancellor to adopt
Coast Academies Writing Framework Step 4. 1 of 7
 1 KPI Spell further homophones. 2 3 Objective Spell words that are often misspelt (English Appendix 1) KPI Place the possessive apostrophe accurately in words with regular plurals: e.g. girls, boys and
1 KPI Spell further homophones. 2 3 Objective Spell words that are often misspelt (English Appendix 1) KPI Place the possessive apostrophe accurately in words with regular plurals: e.g. girls, boys and
Ontologies vs. classification systems
 Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
Ontologies vs. classification systems Bodil Nistrup Madsen Copenhagen Business School Copenhagen, Denmark bnm.isv@cbs.dk Hanne Erdman Thomsen Copenhagen Business School Copenhagen, Denmark het.isv@cbs.dk
The College Board Redesigned SAT Grade 12
 A Correlation of, 2017 To the Redesigned SAT Introduction This document demonstrates how myperspectives English Language Arts meets the Reading, Writing and Language and Essay Domains of Redesigned SAT.
A Correlation of, 2017 To the Redesigned SAT Introduction This document demonstrates how myperspectives English Language Arts meets the Reading, Writing and Language and Essay Domains of Redesigned SAT.
THE HEAD START CHILD OUTCOMES FRAMEWORK
 THE HEAD START CHILD OUTCOMES FRAMEWORK Released in 2000, the Head Start Child Outcomes Framework is intended to guide Head Start programs in their curriculum planning and ongoing assessment of the progress
THE HEAD START CHILD OUTCOMES FRAMEWORK Released in 2000, the Head Start Child Outcomes Framework is intended to guide Head Start programs in their curriculum planning and ongoing assessment of the progress
GCSE Mathematics B (Linear) Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education
 Mark Scheme for November Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education") GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
GCSE Mathematics B (Linear) Component J567/04: Mathematics Paper 4 (Higher) General Certificate of Secondary Education Mark Scheme for November 2014 Oxford Cambridge and RSA Examinations OCR (Oxford Cambridge
Loughton School s curriculum evening. 28 th February 2017
 Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Loughton School s curriculum evening 28 th February 2017 Aims of this session Share our approach to teaching writing, reading, SPaG and maths. Share resources, ideas and strategies to support children's
Florida Reading Endorsement Alignment Matrix Competency 1
 Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Florida Reading Endorsement Alignment Matrix Competency 1 Reading Endorsement Guiding Principle: Teachers will understand and teach reading as an ongoing strategic process resulting in students comprehending
Implementing a tool to Support KAOS-Beta Process Model Using EPF
 Implementing a tool to Support KAOS-Beta Process Model Using EPF Malihe Tabatabaie Malihe.Tabatabaie@cs.york.ac.uk Department of Computer Science The University of York United Kingdom Eclipse Process Framework
Implementing a tool to Support KAOS-Beta Process Model Using EPF Malihe Tabatabaie Malihe.Tabatabaie@cs.york.ac.uk Department of Computer Science The University of York United Kingdom Eclipse Process Framework
Using SAM Central With iread
 Using SAM Central With iread January 1, 2016 For use with iread version 1.2 or later, SAM Central, and Student Achievement Manager version 2.4 or later PDF0868 (PDF) Houghton Mifflin Harcourt Publishing
Using SAM Central With iread January 1, 2016 For use with iread version 1.2 or later, SAM Central, and Student Achievement Manager version 2.4 or later PDF0868 (PDF) Houghton Mifflin Harcourt Publishing
South Carolina English Language Arts
 South Carolina English Language Arts A S O F J U N E 2 0, 2 0 1 0, T H I S S TAT E H A D A D O P T E D T H E CO M M O N CO R E S TAT E S TA N DA R D S. DOCUMENTS REVIEWED South Carolina Academic Content
South Carolina English Language Arts A S O F J U N E 2 0, 2 0 1 0, T H I S S TAT E H A D A D O P T E D T H E CO M M O N CO R E S TAT E S TA N DA R D S. DOCUMENTS REVIEWED South Carolina Academic Content
Pobrane z czasopisma New Horizons in English Studies Data: 18/11/ :52:20. New Horizons in English Studies 1/2016
 LANGUAGE Maria Curie-Skłodowska University () in Lublin k.laidler.umcs@gmail.com Online Adaptation of Word-initial Ukrainian CC Consonant Clusters by Native Speakers of English Abstract. The phenomenon
LANGUAGE Maria Curie-Skłodowska University () in Lublin k.laidler.umcs@gmail.com Online Adaptation of Word-initial Ukrainian CC Consonant Clusters by Native Speakers of English Abstract. The phenomenon
What the National Curriculum requires in reading at Y5 and Y6
 What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
What the National Curriculum requires in reading at Y5 and Y6 Word reading apply their growing knowledge of root words, prefixes and suffixes (morphology and etymology), as listed in Appendix 1 of the
Parallel Evaluation in Stratal OT * Adam Baker University of Arizona
 Parallel Evaluation in Stratal OT * Adam Baker University of Arizona tabaker@u.arizona.edu 1.0. Introduction The model of Stratal OT presented by Kiparsky (forthcoming), has not and will not prove uncontroversial
Parallel Evaluation in Stratal OT * Adam Baker University of Arizona tabaker@u.arizona.edu 1.0. Introduction The model of Stratal OT presented by Kiparsky (forthcoming), has not and will not prove uncontroversial
Primary English Curriculum Framework
 Primary English Curriculum Framework Primary English Curriculum Framework This curriculum framework document is based on the primary National Curriculum and the National Literacy Strategy that have been
Primary English Curriculum Framework Primary English Curriculum Framework This curriculum framework document is based on the primary National Curriculum and the National Literacy Strategy that have been
Universal contrastive analysis as a learning principle in CAPT
 Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Universal contrastive analysis as a learning principle in CAPT Jacques Koreman, Preben Wik, Olaf Husby, Egil Albertsen Department of Language and Communication Studies, NTNU, Trondheim, Norway jacques.koreman@ntnu.no,
Taking into Account the Oral-Written Dichotomy of the Chinese language :
 Taking into Account the Oral-Written Dichotomy of the Chinese language : The division and connections between lexical items for Oral and for Written activities Bernard ALLANIC 安雄舒长瑛 SHU Changying 1 I.
Taking into Account the Oral-Written Dichotomy of the Chinese language : The division and connections between lexical items for Oral and for Written activities Bernard ALLANIC 安雄舒长瑛 SHU Changying 1 I.
ELA/ELD Standards Correlation Matrix for ELD Materials Grade 1 Reading
 ELA/ELD Correlation Matrix for ELD Materials Grade 1 Reading The English Language Arts (ELA) required for the one hour of English-Language Development (ELD) Materials are listed in Appendix 9-A, Matrix
ELA/ELD Correlation Matrix for ELD Materials Grade 1 Reading The English Language Arts (ELA) required for the one hour of English-Language Development (ELD) Materials are listed in Appendix 9-A, Matrix
Be aware there will be a makeup date for missed class time on the Thanksgiving holiday. This will be discussed in class. Course Description
 HDCN 6303-METHODS: GROUP COUNSELING Department of Counseling and Dispute Resolution Southern Methodist University Thursday 6pm 10:15pm Jan Term 2013-14 Be aware there will be a makeup date for missed class
HDCN 6303-METHODS: GROUP COUNSELING Department of Counseling and Dispute Resolution Southern Methodist University Thursday 6pm 10:15pm Jan Term 2013-14 Be aware there will be a makeup date for missed class
LEXICAL COHESION ANALYSIS OF THE ARTICLE WHAT IS A GOOD RESEARCH PROJECT? BY BRIAN PALTRIDGE A JOURNAL ARTICLE
 LEXICAL COHESION ANALYSIS OF THE ARTICLE WHAT IS A GOOD RESEARCH PROJECT? BY BRIAN PALTRIDGE A JOURNAL ARTICLE Submitted in partial fulfillment of the requirements for the degree of Sarjana Sastra (S.S.)
LEXICAL COHESION ANALYSIS OF THE ARTICLE WHAT IS A GOOD RESEARCH PROJECT? BY BRIAN PALTRIDGE A JOURNAL ARTICLE Submitted in partial fulfillment of the requirements for the degree of Sarjana Sastra (S.S.)
The IDN Variant Issues Project: A Study of Issues Related to the Delegation of IDN Variant TLDs. 20 April 2011
 The IDN Variant Issues Project: A Study of Issues Related to the Delegation of IDN Variant TLDs 20 April 2011 Project Proposal updated based on comments received during the Public Comment period held from
The IDN Variant Issues Project: A Study of Issues Related to the Delegation of IDN Variant TLDs 20 April 2011 Project Proposal updated based on comments received during the Public Comment period held from
Arizona s English Language Arts Standards th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS
 Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
Arizona s English Language Arts Standards 11-12th Grade ARIZONA DEPARTMENT OF EDUCATION HIGH ACADEMIC STANDARDS FOR STUDENTS 11 th -12 th Grade Overview Arizona s English Language Arts Standards work together
Statewide Framework Document for:
 Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
Statewide Framework Document for: 270301 Standards may be added to this document prior to submission, but may not be removed from the framework to meet state credit equivalency requirements. Performance
A Neural Network GUI Tested on Text-To-Phoneme Mapping
 A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
A Neural Network GUI Tested on Text-To-Phoneme Mapping MAARTEN TROMPPER Universiteit Utrecht m.f.a.trompper@students.uu.nl Abstract Text-to-phoneme (T2P) mapping is a necessary step in any speech synthesis
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH
 SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
SEGMENTAL FEATURES IN SPONTANEOUS AND READ-ALOUD FINNISH Mietta Lennes Most of the phonetic knowledge that is currently available on spoken Finnish is based on clearly pronounced speech: either readaloud
F.No.29-3/2016-NVS(Acad.) Dated: Sub:- Organisation of Cluster/Regional/National Sports & Games Meet and Exhibition reg.
 Dated: Sub:- Organisation of Cluster/Regional/National Sports & Games Meet and Exhibition reg.") नव दय ववद य लय सम त (म नव स स धन ववक स म त र लय क एक स व यत स स न, ववद य लय श क ष एव स क षरत ववभ ग, भ रत सरक र) ब -15, इन स लयट य यन नल एयरय, स क लर 62, न यड, उत तर रद 201 309 NAVODAYA VIDYALAYA SAMITI
नव दय ववद य लय सम त (म नव स स धन ववक स म त र लय क एक स व यत स स न, ववद य लय श क ष एव स क षरत ववभ ग, भ रत सरक र) ब -15, इन स लयट य यन नल एयरय, स क लर 62, न यड, उत तर रद 201 309 NAVODAYA VIDYALAYA SAMITI
Content Language Objectives (CLOs) August 2012, H. Butts & G. De Anda
 August 2012, H. Butts & G. De Anda") Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
Content Language Objectives (CLOs) Outcomes Identify the evolution of the CLO Identify the components of the CLO Understand how the CLO helps provide all students the opportunity to access the rigor of
have to be modeled) or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,
 or isolated words. Output of the system is a grapheme-tophoneme conversion system which takes as its input the spelling of words,") A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
A Language-Independent, Data-Oriented Architecture for Grapheme-to-Phoneme Conversion Walter Daelemans and Antal van den Bosch Proceedings ESCA-IEEE speech synthesis conference, New York, September 1994
Standards for Members of the American Handwriting Analysis Foundation
 Standards for Members of the American Handwriting Analysis Foundation A. Purpose The purpose of this document is to provide a foundation for the development and evaluation of a set of standards for education,
Standards for Members of the American Handwriting Analysis Foundation A. Purpose The purpose of this document is to provide a foundation for the development and evaluation of a set of standards for education,
The analysis starts with the phonetic vowel and consonant charts based on the dataset:
 Ling 113 Homework 5: Hebrew Kelli Wiseth February 13, 2014 The analysis starts with the phonetic vowel and consonant charts based on the dataset: a) Given that the underlying representation for all verb
Ling 113 Homework 5: Hebrew Kelli Wiseth February 13, 2014 The analysis starts with the phonetic vowel and consonant charts based on the dataset: a) Given that the underlying representation for all verb
Myths, Legends, Fairytales and Novels (Writing a Letter)
") Assessment Focus This task focuses on Communication through the mode of Writing at Levels 3, 4 and 5. Two linked tasks (Hot Seating and Character Study) that use the same context are available to assess
Assessment Focus This task focuses on Communication through the mode of Writing at Levels 3, 4 and 5. Two linked tasks (Hot Seating and Character Study) that use the same context are available to assess
1. Introduction. 2. The OMBI database editor
 OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
OMBI bilingual lexical resources: Arabic-Dutch / Dutch-Arabic Carole Tiberius, Anna Aalstein, Instituut voor Nederlandse Lexicologie Jan Hoogland, Nederlands Instituut in Marokko (NIMAR) In this paper
LING 329 : MORPHOLOGY
 LING 329 : MORPHOLOGY TTh 10:30 11:50 AM, Physics 121 Course Syllabus Spring 2013 Matt Pearson Office: Vollum 313 Email: pearsonm@reed.edu Phone: 7618 (off campus: 503-517-7618) Office hrs: Mon 1:30 2:30,
LING 329 : MORPHOLOGY TTh 10:30 11:50 AM, Physics 121 Course Syllabus Spring 2013 Matt Pearson Office: Vollum 313 Email: pearsonm@reed.edu Phone: 7618 (off campus: 503-517-7618) Office hrs: Mon 1:30 2:30,
Student Handbook 2016 University of Health Sciences, Lahore
 Student Handbook 2016 University of Health Sciences, Lahore 1 Welcome to the Certificate in Medical Teaching programme 2016 at the University of Health Sciences, Lahore. This programme is for teachers
Student Handbook 2016 University of Health Sciences, Lahore 1 Welcome to the Certificate in Medical Teaching programme 2016 at the University of Health Sciences, Lahore. This programme is for teachers
University of Groningen. Systemen, planning, netwerken Bosman, Aart
 University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
University of Groningen Systemen, planning, netwerken Bosman, Aart IMPORTANT NOTE: You are advised to consult the publisher's version (publisher's PDF) if you wish to cite from it. Please check the document
Phonological and Phonetic Representations: The Case of Neutralization
 Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
Phonological and Phonetic Representations: The Case of Neutralization Allard Jongman University of Kansas 1. Introduction The present paper focuses on the phenomenon of phonological neutralization to consider
PAGE(S) WHERE TAUGHT If sub mission ins not a book, cite appropriate location(s))
 WHERE TAUGHT If sub mission ins not a book, cite appropriate location(s))") Ohio Academic Content Standards Grade Level Indicators (Grade 11) A. ACQUISITION OF VOCABULARY Students acquire vocabulary through exposure to language-rich situations, such as reading books and other
Ohio Academic Content Standards Grade Level Indicators (Grade 11) A. ACQUISITION OF VOCABULARY Students acquire vocabulary through exposure to language-rich situations, such as reading books and other
Orientation Workshop on Outcome Based Accreditation. May 21st, 2016
 Orientation Workshop on Outcome Based Accreditation May 21st, 2016 ABOUT NBA Established in the year 1994 under Section 10 (u) of AICTE Act. NBA became Autonomous in January 2010 and in April 2013 the
Orientation Workshop on Outcome Based Accreditation May 21st, 2016 ABOUT NBA Established in the year 1994 under Section 10 (u) of AICTE Act. NBA became Autonomous in January 2010 and in April 2013 the
AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC PP. VI, 282)
 (LONDON, BLOOMSBURY ACADEMIC PP. VI, 282)") B. PALTRIDGE, DISCOURSE ANALYSIS: AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC. 2012. PP. VI, 282) Review by Glenda Shopen _ This book is a revised edition of the author s 2006 introductory
B. PALTRIDGE, DISCOURSE ANALYSIS: AN INTRODUCTION (2 ND ED.) (LONDON, BLOOMSBURY ACADEMIC. 2012. PP. VI, 282) Review by Glenda Shopen _ This book is a revised edition of the author s 2006 introductory
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany
 Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
Entrepreneurial Discovery and the Demmert/Klein Experiment: Additional Evidence from Germany Jana Kitzmann and Dirk Schiereck, Endowed Chair for Banking and Finance, EUROPEAN BUSINESS SCHOOL, International
TEKS Comments Louisiana GLE
 Side-by-Side Comparison of the Texas Educational Knowledge Skills (TEKS) Louisiana Grade Level Expectations (GLEs) ENGLISH LANGUAGE ARTS: Kindergarten TEKS Comments Louisiana GLE (K.1) Listening/Speaking/Purposes.
Side-by-Side Comparison of the Texas Educational Knowledge Skills (TEKS) Louisiana Grade Level Expectations (GLEs) ENGLISH LANGUAGE ARTS: Kindergarten TEKS Comments Louisiana GLE (K.1) Listening/Speaking/Purposes.
CEFR Overall Illustrative English Proficiency Scales
 CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
CEFR Overall Illustrative English Proficiency s CEFR CEFR OVERALL ORAL PRODUCTION Has a good command of idiomatic expressions and colloquialisms with awareness of connotative levels of meaning. Can convey
1. REFLEXES: Ask questions about coughing, swallowing, of water as fast as possible (note! Not suitable for all
 Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
Human Communication Science Chandler House, 2 Wakefield Street London WC1N 1PF http://www.hcs.ucl.ac.uk/ ACOUSTICS OF SPEECH INTELLIGIBILITY IN DYSARTHRIA EUROPEAN MASTER S S IN CLINICAL LINGUISTICS UNIVERSITY
HDR Presentation of Thesis Procedures pro-030 Version: 2.01
 HDR Presentation of Thesis Procedures pro-030 To be read in conjunction with: Research Practice Policy Version: 2.01 Last amendment: 02 April 2014 Next Review: Apr 2016 Approved By: Academic Board Date:
HDR Presentation of Thesis Procedures pro-030 To be read in conjunction with: Research Practice Policy Version: 2.01 Last amendment: 02 April 2014 Next Review: Apr 2016 Approved By: Academic Board Date:
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access
 The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
The Perception of Nasalized Vowels in American English: An Investigation of On-line Use of Vowel Nasalization in Lexical Access Joyce McDonough 1, Heike Lenhert-LeHouiller 1, Neil Bardhan 2 1 Linguistics
Software Maintenance
 1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
1 What is Software Maintenance? Software Maintenance is a very broad activity that includes error corrections, enhancements of capabilities, deletion of obsolete capabilities, and optimization. 2 Categories
Mandarin Lexical Tone Recognition: The Gating Paradigm
 Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Kansas Working Papers in Linguistics, Vol. 0 (008), p. 8 Abstract Mandarin Lexical Tone Recognition: The Gating Paradigm Yuwen Lai and Jie Zhang University of Kansas Research on spoken word recognition
Modeling full form lexica for Arabic
 Modeling full form lexica for Arabic Susanne Alt Amine Akrout Atilf-CNRS Laurent Romary Loria-CNRS Objectives Presentation of the current standardization activity in the domain of lexical data modeling
Modeling full form lexica for Arabic Susanne Alt Amine Akrout Atilf-CNRS Laurent Romary Loria-CNRS Objectives Presentation of the current standardization activity in the domain of lexical data modeling
Approaches to control phenomena handout Obligatory control and morphological case: Icelandic and Basque
 Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
Approaches to control phenomena handout 6 5.4 Obligatory control and morphological case: Icelandic and Basque Icelandinc quirky case (displaying properties of both structural and inherent case: lexically
DOWNSTEP IN SUPYIRE* Robert Carlson Societe Internationale de Linguistique, Mali
 Studies in African inguistics Volume 4 Number April 983 DOWNSTEP IN SUPYIRE* Robert Carlson Societe Internationale de inguistique ali Downstep in the vast majority of cases can be traced to the influence
Studies in African inguistics Volume 4 Number April 983 DOWNSTEP IN SUPYIRE* Robert Carlson Societe Internationale de inguistique ali Downstep in the vast majority of cases can be traced to the influence
ANGLAIS LANGUE SECONDE
 ANGLAIS LANGUE SECONDE ANG-5055-6 DEFINITION OF THE DOMAIN SEPTEMBRE 1995 ANGLAIS LANGUE SECONDE ANG-5055-6 DEFINITION OF THE DOMAIN SEPTEMBER 1995 Direction de la formation générale des adultes Service
ANGLAIS LANGUE SECONDE ANG-5055-6 DEFINITION OF THE DOMAIN SEPTEMBRE 1995 ANGLAIS LANGUE SECONDE ANG-5055-6 DEFINITION OF THE DOMAIN SEPTEMBER 1995 Direction de la formation générale des adultes Service
GACE Computer Science Assessment Test at a Glance
 GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
GACE Computer Science Assessment Test at a Glance Updated May 2017 See the GACE Computer Science Assessment Study Companion for practice questions and preparation resources. Assessment Name Computer Science
source or where they are needed to distinguish two forms of a language. 4. Geographical Location. I have attempted to provide a geographical
 Database Structure 1 This database, compiled by Merritt Ruhlen, contains certain kinds of linguistic and nonlinguistic information for the world s roughly 5,000 languages. This introduction will discuss
Database Structure 1 This database, compiled by Merritt Ruhlen, contains certain kinds of linguistic and nonlinguistic information for the world s roughly 5,000 languages. This introduction will discuss
TABE 9&10. Revised 8/2013- with reference to College and Career Readiness Standards
 TABE 9&10 Revised 8/2013- with reference to College and Career Readiness Standards LEVEL E Test 1: Reading Name Class E01- INTERPRET GRAPHIC INFORMATION Signs Maps Graphs Consumer Materials Forms Dictionary
TABE 9&10 Revised 8/2013- with reference to College and Career Readiness Standards LEVEL E Test 1: Reading Name Class E01- INTERPRET GRAPHIC INFORMATION Signs Maps Graphs Consumer Materials Forms Dictionary
Linking Task: Identifying authors and book titles in verbose queries
 Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
Linking Task: Identifying authors and book titles in verbose queries Anaïs Ollagnier, Sébastien Fournier, and Patrice Bellot Aix-Marseille University, CNRS, ENSAM, University of Toulon, LSIS UMR 7296,
MASTER S THESIS GUIDE MASTER S PROGRAMME IN COMMUNICATION SCIENCE
 MASTER S THESIS GUIDE MASTER S PROGRAMME IN COMMUNICATION SCIENCE University of Amsterdam Graduate School of Communication Kloveniersburgwal 48 1012 CX Amsterdam The Netherlands E-mail address: scripties-cw-fmg@uva.nl
MASTER S THESIS GUIDE MASTER S PROGRAMME IN COMMUNICATION SCIENCE University of Amsterdam Graduate School of Communication Kloveniersburgwal 48 1012 CX Amsterdam The Netherlands E-mail address: scripties-cw-fmg@uva.nl
University of Exeter College of Humanities. Assessment Procedures 2010/11
 University of Exeter College of Humanities Assessment Procedures 2010/11 This document describes the conventions and procedures used to assess, progress and classify UG students within the College of Humanities.
University of Exeter College of Humanities Assessment Procedures 2010/11 This document describes the conventions and procedures used to assess, progress and classify UG students within the College of Humanities.
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1. High Priority Items Phonemic Awareness Instruction
 CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
CLASSIFICATION OF PROGRAM Critical Elements Analysis 1 Program Name: Macmillan/McGraw Hill Reading 2003 Date of Publication: 2003 Publisher: Macmillan/McGraw Hill Reviewer Code: 1. X The program meets
5 th Grade Language Arts Curriculum Map
 5 th Grade Language Arts Curriculum Map Quarter 1 Unit of Study: Launching Writer s Workshop 5.L.1 - Demonstrate command of the conventions of Standard English grammar and usage when writing or speaking.
5 th Grade Language Arts Curriculum Map Quarter 1 Unit of Study: Launching Writer s Workshop 5.L.1 - Demonstrate command of the conventions of Standard English grammar and usage when writing or speaking.
Number of students enrolled in the program in Fall, 2011: 20. Faculty member completing template: Molly Dugan (Date: 1/26/2012)
") Program: Journalism Minor Department: Communication Studies Number of students enrolled in the program in Fall, 2011: 20 Faculty member completing template: Molly Dugan (Date: 1/26/2012) Period of reference
Program: Journalism Minor Department: Communication Studies Number of students enrolled in the program in Fall, 2011: 20 Faculty member completing template: Molly Dugan (Date: 1/26/2012) Period of reference
Learning Disability Functional Capacity Evaluation. Dear Doctor,
 Dear Doctor, I have been asked to formulate a vocational opinion regarding NAME s employability in light of his/her learning disability. To assist me with this evaluation I would appreciate if you can
Dear Doctor, I have been asked to formulate a vocational opinion regarding NAME s employability in light of his/her learning disability. To assist me with this evaluation I would appreciate if you can
THE PENNSYLVANIA STATE UNIVERSITY SCHREYER HONORS COLLEGE DEPARTMENT OF MATHEMATICS ASSESSING THE EFFECTIVENESS OF MULTIPLE CHOICE MATH TESTS
 THE PENNSYLVANIA STATE UNIVERSITY SCHREYER HONORS COLLEGE DEPARTMENT OF MATHEMATICS ASSESSING THE EFFECTIVENESS OF MULTIPLE CHOICE MATH TESTS ELIZABETH ANNE SOMERS Spring 2011 A thesis submitted in partial
THE PENNSYLVANIA STATE UNIVERSITY SCHREYER HONORS COLLEGE DEPARTMENT OF MATHEMATICS ASSESSING THE EFFECTIVENESS OF MULTIPLE CHOICE MATH TESTS ELIZABETH ANNE SOMERS Spring 2011 A thesis submitted in partial
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES MODELING IMPROVED AMHARIC SYLLBIFICATION ALGORITHM
 ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES MODELING IMPROVED AMHARIC SYLLBIFICATION ALGORITHM BY NIRAYO HAILU GEBREEGZIABHER A THESIS SUBMITED TO THE SCHOOL OF GRADUATE STUDIES OF ADDIS ABABA UNIVERSITY
ADDIS ABABA UNIVERSITY SCHOOL OF GRADUATE STUDIES MODELING IMPROVED AMHARIC SYLLBIFICATION ALGORITHM BY NIRAYO HAILU GEBREEGZIABHER A THESIS SUBMITED TO THE SCHOOL OF GRADUATE STUDIES OF ADDIS ABABA UNIVERSITY
Ohio s Learning Standards-Clear Learning Targets
 Ohio s Learning Standards-Clear Learning Targets Math Grade 1 Use addition and subtraction within 20 to solve word problems involving situations of 1.OA.1 adding to, taking from, putting together, taking
Ohio s Learning Standards-Clear Learning Targets Math Grade 1 Use addition and subtraction within 20 to solve word problems involving situations of 1.OA.1 adding to, taking from, putting together, taking
Massachusetts Department of Elementary and Secondary Education. Title I Comparability
 Massachusetts Department of Elementary and Secondary Education Title I Comparability 2009-2010 Title I provides federal financial assistance to school districts to provide supplemental educational services
Massachusetts Department of Elementary and Secondary Education Title I Comparability 2009-2010 Title I provides federal financial assistance to school districts to provide supplemental educational services
Emmaus Lutheran School English Language Arts Curriculum
 Emmaus Lutheran School English Language Arts Curriculum Rationale based on Scripture God is the Creator of all things, including English Language Arts. Our school is committed to providing students with
Emmaus Lutheran School English Language Arts Curriculum Rationale based on Scripture God is the Creator of all things, including English Language Arts. Our school is committed to providing students with
SARDNET: A Self-Organizing Feature Map for Sequences
 SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
SARDNET: A Self-Organizing Feature Map for Sequences Daniel L. James and Risto Miikkulainen Department of Computer Sciences The University of Texas at Austin Austin, TX 78712 dljames,risto~cs.utexas.edu
Fisk Street Primary School
 Fisk Street Primary School Literacy at Fisk Street Primary School is made up of the following components: Speaking and Listening Reading Writing Spelling Grammar Handwriting The Australian Curriculum specifies
Fisk Street Primary School Literacy at Fisk Street Primary School is made up of the following components: Speaking and Listening Reading Writing Spelling Grammar Handwriting The Australian Curriculum specifies
On-Line Data Analytics
 International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
International Journal of Computer Applications in Engineering Sciences [VOL I, ISSUE III, SEPTEMBER 2011] [ISSN: 2231-4946] On-Line Data Analytics Yugandhar Vemulapalli #, Devarapalli Raghu *, Raja Jacob
ACCOUNTING FOR LAWYERS SYLLABUS
 ACCOUNTING FOR LAWYERS SYLLABUS PROF. WILLIS OFFICE: 331 PHONE: 352-273-0680 (TAX OFFICE) OFFICE HOURS: Wednesday 10:00 2:00 (for Tax Timing) plus Tuesday/Thursday from 1:00 4:00 (all classes). Email:
ACCOUNTING FOR LAWYERS SYLLABUS PROF. WILLIS OFFICE: 331 PHONE: 352-273-0680 (TAX OFFICE) OFFICE HOURS: Wednesday 10:00 2:00 (for Tax Timing) plus Tuesday/Thursday from 1:00 4:00 (all classes). Email:
Lecture 1: Machine Learning Basics
 1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3
1/69 Lecture 1: Machine Learning Basics Ali Harakeh University of Waterloo WAVE Lab ali.harakeh@uwaterloo.ca May 1, 2017 2/69 Overview 1 Learning Algorithms 2 Capacity, Overfitting, and Underfitting 3